出自 :http://neuralnetworksanddeeplearning.com/ 。
卷积神经网络采用了三种基本概念:局部感受野(local receptive fields),共享权重(sharedweights),和混合(pooling)。
局部感受野: 在之前看到的全连接层的网络中,输入被描绘成纵向排列的神经元。但在一个卷积网络中,把输入看作是一个 28 × 28 的方形排列的神经元更有帮助,其值对应于我们用作输入的 28 × 28 的像素光强度:

和通常一样,我们把输入像素连接到一个隐藏神经元层。但是我们不会把每个输入像素连接到每个隐藏神经元。相反,我们只是把输入图像进行小的,局部区域的连接。说的确切一点,第一个隐藏层中的每个神经元会连接到一个输入神经元的一个小区域,例如,一个 5 × 5 的区域,对应于 25 个输入像素。所以对于一个特定的隐藏神经元,我们可能有看起来像这样的连接
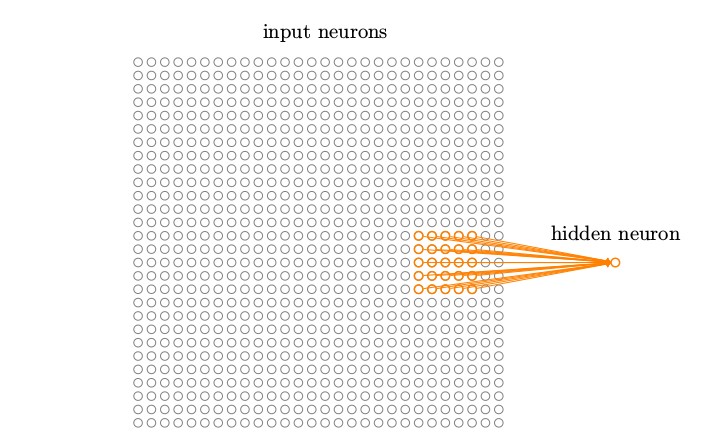
这个输入图像的区域被称为隐藏神经元的局部感受野。它是输入像素上的一个小窗口。每个连接学习一个权重。而隐藏神经元同时也学习一个总的偏置。你可以把这个特定的隐藏神经元看作是在学习分析它的局部感受野。
我们然后在整个输入图像上交叉移动局部感受野。对于每个局部感受野,在第一个隐藏层中有一个不同的隐藏神经元。为了正确说明,让我们从左上⻆开始一个局部感受野:
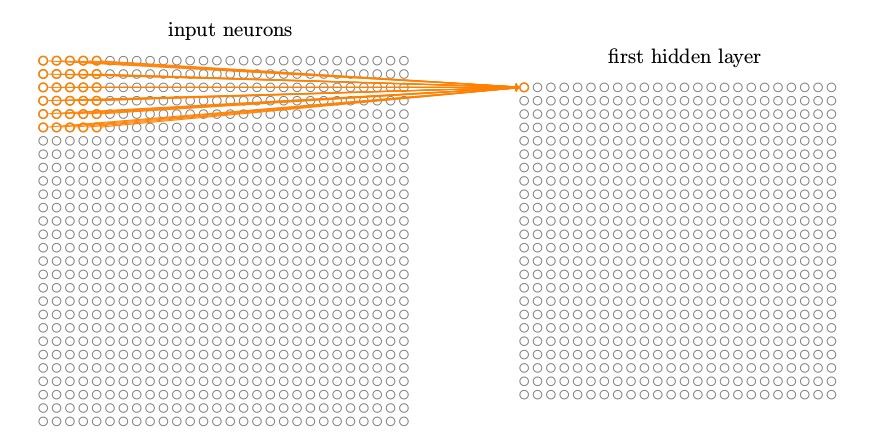
然后我们往右一个像素(即一个神经元)移动局部感受野,连接到第二个隐藏神经元: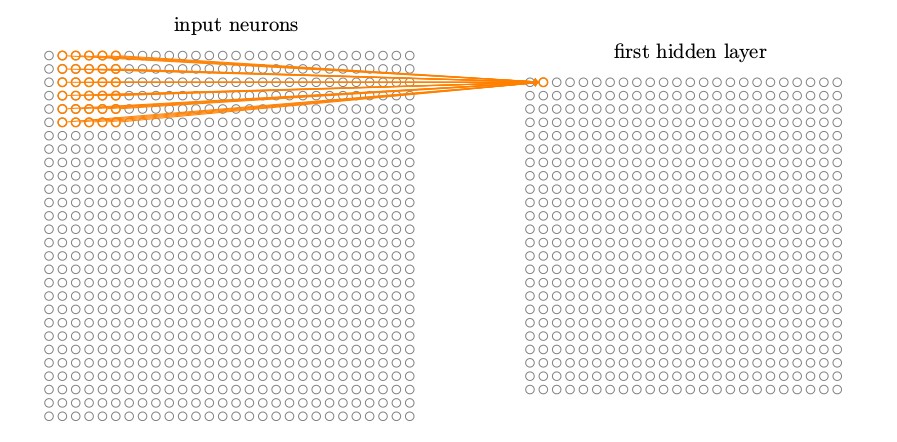
如此重复,构建起第一个隐藏层。注意如果我们有一个 28 × 28 的输入图像,5 × 5 的局部感受野,那么隐藏层中就会有 24 × 24 个神经元。这是因为在抵达右边(或者底部)的输入图像之前,我们只能把局部感受野横向移动 23 个神经元(或者往下 23 个神经元)。我显示的局部感受野每次移动一个像素。实际上,有时候会使用不同的跨距。例如,我可以往右(或下)移动 2 个像素的局部感受野,这种情况下我们使用了 2 个跨距。在这章里我们大部分时候会固定使用 1 的跨距,但是值得知道人们有时用不同的跨距试验。
共享权重和偏置: 我已经说过每个隐藏神经元具有一个偏置和连接到它的局部感受野的5 × 5 权重。我没有提及的是我们打算对 24 × 24 隐藏神经元中的每一个使用相同的权重和偏置。
换句话说,对第 j, k 个隐藏神经元,输出为:
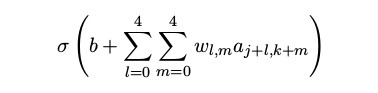
这里 σ 是神经元的激活函数 —— 可以是我们在前面章里使用过的 S 型函数。b 是偏置的共享值。wl,m是一个共享权重的 5 × 5 数组。最后,我们使用 ax,y 来表示位置为 x, y 的输入激活值。
这意味着第一个隐藏层的所有神经元检测完全相同的特征 ,只是在输入图像的不同位置。要明白为什么是这个道理,把权重和偏置设想成隐藏神经元可以挑选的东西,例如,在一个特定的局部感受野的垂直边缘。这种能力在图像的其它位置也很可能是有用的。因此,在图像中应用相同的特征检测器是非常有用的。用稍微更抽象的术语,卷积网络能很好地适应图像的平移不变性:例如稍稍移动一幅猫的图像,它仍然是一幅猫的图像 。
因为这个原因,我们有时候把从输入层到隐藏层的映射称为一个特征映射。我们把定义特征映射的权重称为共享权重。我们把以这种方式定义特征映射的偏置称为共享偏置。共享权重和偏置经常被称为一个卷积核或者滤波器。在文献中,人们有时以稍微不同的方式使用这些术语,对此我不打算去严格区分;稍后我们会看一些具体的例子。
目前我描述的网络结构只能检测一种局部特征的类型。为了完成图像识别我们需要超过一个的特征映射。所以一个完整的卷积层由几个不同的特征映射组成:
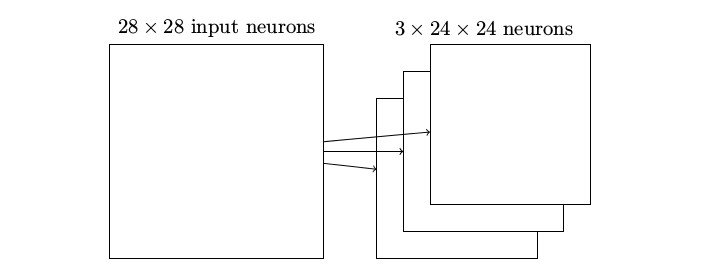
在这个例子中,有 3 个特征映射。每个特征映射定义为一个 5 × 5 共享权重和单个共享偏置的集合。其结果是网络能够检测 3 种不同的特征,每个特征都在整个图像中可检测。
为了让上面的图示简单些,我仅仅展示了 3 个特征映射。然而,在实践中卷积网络可能使用很多(也许多得多)的特征映射。一种早期的识别 MNIST 数字的卷积网络,LeNet-5,使用 6 个特征映射,每个关联到一个 5 × 5 的局部感受野。所以上面的插图例子实际和 LeNet-5 很接近。而在我们在本章后面要开发的例子里,我们将使用具有 20 和 40 个特征映射的卷积层。让我们快速看下已经学到的一些特征 :

这 20 幅图像对应于 20 个不同的特征映射(或滤波器、核)。每个映射有一幅 5 × 5 块的图像表示,对应于局部感受野中的 5 × 5 权重。白色块意味着一个小(典型的,更小的负数)权重,所以这样的特征映射对相应的输入像素有更小的响应。更暗的块意味着一个更大的权重,所以这样的特征映射对相应的输入像素有更大的响应。非常粗略地讲,上面的图像显示了卷基层作出响应的特征类型。
所以我们能从这些特征映射中得到什么结论?很明显这里有超出了我们期望的空间结构:这些特征许多有清晰的亮和暗的子区域。这表示我们的网络实际上正在学习和空间结构相关的东西。然而,除了那个,看清这些特征检测器在学什么是很困难的。当然,我们并不是在学习(例如)Gabor 滤波器,它已经被用在很多传统的图像识别方法中。实际上,现在有许多关于通过卷积网络来更好理解特征的工作成果。如果你感兴趣,我建议从 Matthew Zeiler 和 Rob Fergus 的(2013)论文 Visualizing and Understanding Convolutional Networks 开始。
共享权重和偏置的一个很大的优点是,它大大减少了参与的卷积网络的参数。对于每个特征映射我们需要 25 = 5 × 5 个共享权重,加上一个共享偏置。所以每个特征映射需要 26 个参数。如果我们有 20 个特征映射,那么总共有 20 × 26 = 520 个参数来定义卷积层。作为对比,假设我们有一个全连接的第一层,具有 784 = 28 × 28 个输入神经元,和一个相对适中的 30 个隐藏神经元,正如我们在本书之前的很多例子中使用的。总共有 784 × 30 个权重,加上额外的 30 个偏置,共有 23, 550 个参数。换句话说,这个全连接的层有多达 40 倍于卷基层的参数。
当然,我们不能真正做一个参数数量之间的直接比较,因为这两个模型的本质是不同的。但是,直观地,使用卷积层的平移不变性似乎很可能减少全连接模型中达到同样性能的参数数量。反过来,这将导致更快的卷积模型的训练,并最终,将有助于我们使用卷积层建立深度网络。
混合层: 除了刚刚描述的卷积层,卷积神经网络也包含混合层(pooling layers)。混合层通常紧接着在卷积层之后使用。它要做的是简化从卷积层输出的信息。
详细地说,一个混合层取得从卷积层输出的每一个特征映射,并且从它们准备一个凝缩的特征映射。例如,混合层的每个单元可能概括了前一层的一个(比如)2 × 2 的区域。作为一个具体的例子,一个常⻅的混合的程序被称为最大值混合(max-pooling)。在最大值混合中,一个混合单元简单地输出其 2 × 2 输入区域的最大激活值,正如下图说明的: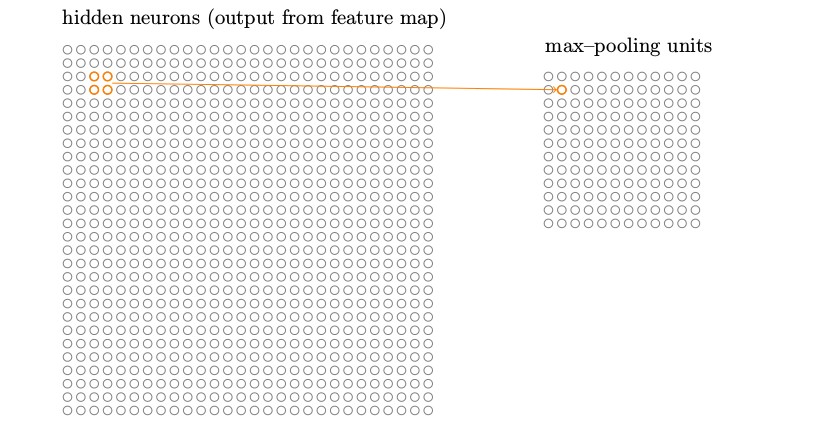
注意既然从卷积层有 24 × 24 个神经元输出,混合后我们得到 12 × 12 个神经元。
正如上面提到的,卷积层通常包含超过一个特征映射。我们将最大值混合分别应用于每一个特征映射。所以如果有三个特征映射,组合在一起的卷积层和最大值
混合层看起来像这样
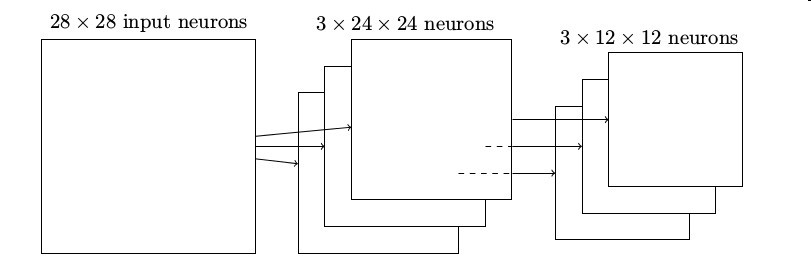
我们可以把最大值混合看作一种网络询问是否有一个给定的特征在一个图像区域中的哪个地方被发现的方式。然后它扔掉确切的位置信息。直观上,一旦一个特征被发现,它的确切位置并不如它相对于其它特征的大概位置重要。一个很大的好处是,这样可以有很多被更少地混合的特征,所以这有助于减少在以后的层所需的参数的数目。
最大值混合并不是用于混合的仅有的技术。另一个常用的方法是 L2 混合(L2 pooling)。这里我们取 2 × 2 区域中激活值的平方和的平方根,而不是最大激活值。虽然细节不同,但其直观上和最大值混合是相似的: L2 混合是一种凝缩从卷积层输出的信息的方式。在实践中,两种技术都被广泛应用。而且有时候人们使用其它混合操作的类型。如果你正在尝试优化性能,你可以使用验证数据来比较混合的不同方法,并选择一个工作得最好的。但我们不打算惦记这种细节上的优化。
综合在一起: 我们现在可以把这些思想都放在一起来构建一个完整的卷积神经网络。它和我们刚看到的架构相似,但是有额外的一层 10 个输出神经元,对应于 10 个可能的 MNIST 数字(’0’,’1’,’2’ 等):
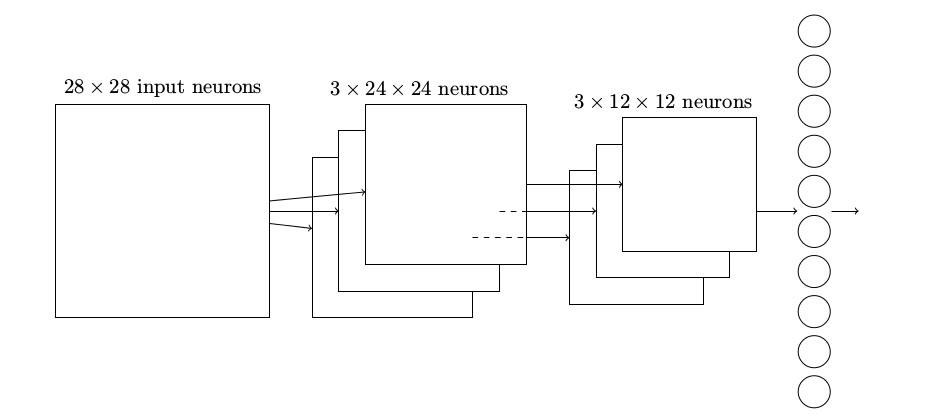
这个网络从 28 × 28 个输入神经元开始,这些神经元用于对 MNIST 图像的像素强度进行编码。接着的是一个卷积层,使用一个 5 × 5 局部感受野和 3 个特征映射。其结果是一个 3 × 24 × 24隐藏特征神经元层。下一步是一个最大值混合层,应用于 2 × 2 区域,遍及 3 个特征映射。结果
是一个 3 × 12 × 12 隐藏特征神经元层。
网络中最后连接的层是一个全连接层。更确切地说,这一层将最大值混合层的每一个神经元连接到每一个输出神经元。这个全连接结构和我们之前章节中使用的相同。然而,注意上面的图示,为了简化,我只使用了一个箭头,而不是显示所有的连接。当然,你可以很容易想象到这些连接。
这个卷积架构和之前章节中使用的架构相当不同。但是总体的描述是相似的:一个由很多简单的单元构成的网络,这些单元的行为由它们的权重和偏置确定。而总体的目标仍然是一样的:用训练数据来训练网络的权重和偏置,使得网络可以胜任分类输入数字。
特别的,正如本书中前面那样,我们将用随即梯度下降和反向传播训练我们的网络。这大部分按照前面章节中完全相同的方式来处理。然而,我们确实需要对反向传播程序做些修改。原因是我们之前的反向传播的推导是针对全连接层的网络。幸运的是,针对卷积和最大值混合层的推导是简单的。如果你想理解细节,那么我请你完成下面的问题。注意这个问题会花费些时间来完成,除非你确实已经吸收了前面的反向传播的推导(这种情况下是容易的)。
问题
• 卷积网络中的反向传播在一个具有全连接层的网络中,反向传播的核心方程是 (BP1)–(BP4)(链接)。假设我们有这样一个网络,它包含有一个卷积层,一个最大值混合层,和一个全连接的输出层,正如上面讨论的那样。反向传播的方程式要如何修改?