安装
1 pip3 install SQLAlchemy -i https://pypi.douban.com/simple
ORM框架:SQLAlchemy
作用:
1.提供简单的规则
2.自动转换成SQL语句
有两类ORM框架
1.DB first: 手动创建数据库以及表通过ORM框架自动生成类
2.code first:手动创建类通过ORM框架自动生成表 SQLAlchemy做了把类、对象转换成SQL语句 类代表一张表,对象就代表类中的一行数据
a.功能:
1.创建数据库表
-连接数据库(pymysql、mysqldb)
-类转换成SQL语句
2.操作数据行
-增
-删
-改
-查
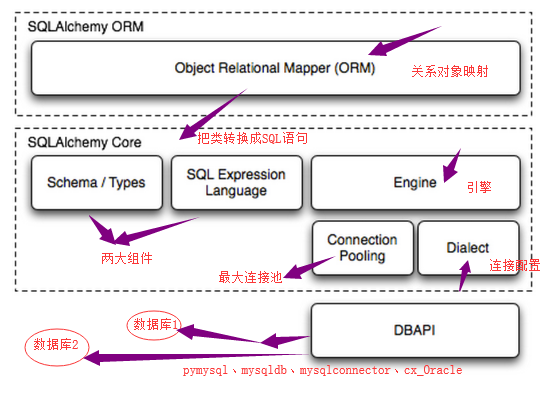
整体架构图:
增删改查
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # pip3 install SQLAlchemy -i https://pypi.douban.com/simple 4 from sqlalchemy.ext.declarative import declarative_base 5 from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index, CHAR 6 from sqlalchemy import create_engine 7 from sqlalchemy.orm import sessionmaker, relationship 8 9 Base = declarative_base() 10 11 12 # 创建单表 13 class UserType(Base): 14 __tablename__ = 'usertype' 15 id = Column(Integer, primary_key=True, autoincrement=True) 16 title = Column(String(32), nullable=True, index=True) 17 18 19 class Users(Base): 20 __tablename__ = 'users' 21 id = Column(Integer, primary_key=True, autoincrement=True) 22 name = Column(String(32), nullable=True, index=True, default='sb') 23 extra = Column(CHAR(16), unique=True) 24 user_type_id = Column(Integer, ForeignKey('usertype.id')) 25 # 方便取数据 26 user_type = relationship("UserType", backref='xxoo') 27 # __table__args__ = ( 28 # UniqueConstraint('id', 'name', name='uix_id_name'), 29 # Index('ix_id_name', 'name', 'extra') 30 # ) 31 32 33 def create_db(): 34 Base.metadata.create_all(engine) 35 36 37 def drop_db(): 38 Base.metadata.drop_all(engine) 39 40 41 engine = create_engine("mysql+pymysql://root:@127.0.0.1:3306/db2?charset=utf8", max_overflow=5) 42 Session = sessionmaker(bind=engine) 43 session = Session() # 相当于在连接池取出一个连接 44 # 类 代表表 45 # 对象 代表数据行 46 # ###########增加########################### 47 # obj = UserType(title='普通用户') 48 # session.add(obj) 49 50 # obj_list = [ 51 # UserType(title='超级用户'), 52 # UserType(title='白金用户'), 53 # UserType(title='黑金用户'), 54 # ] 55 # session.add_all(obj_list) 56 57 # ###########查########################### 58 # print(session.query(UserType)) # 生成的SQL语句 59 # 1.查所有 60 # user_type_list = session.query(UserType).all() # 里边是一个个UserType对象列表 61 # for row in user_type_list: 62 # print(row.id, row.title) 63 64 # 2.过滤 65 # select ** UserType where **** filter delete update后边传的是表达式 66 # user_type_list = session.query(UserType.id, UserType.title).filter(UserType.id > 2) 67 # for row in user_type_list: 68 # print(row.id, row.title) 69 70 71 # 3.查到之后删除 72 # user_type_list = session.query(UserType).filter(UserType.id > 2).delete() 73 74 # 4.查到之后的修改 75 # user_type_list = session.query(UserType.id, UserType.title).filter(UserType.id > 0).update({"title": "黑金"}) # 批量修改 76 # user_type_list = session.query(UserType.id, UserType.title).filter(UserType.id > 0). 77 # update({UserType.title: UserType.title+'x'}, synchronize_session=False) # 批量修改 78 # user_type_list = session.query(UserType).filter(UserType.id > 0). 79 # update({"salary": Users.salary + 1}, synchronize_session="evaluate") 根据更新的字段不同后边synchronize_session参数肯定要改变处理的方式不一样 80 81 # 连表操作 82 # ret = session.query(Users).join(UserType) # INNER JOIN 83 # ret = session.query(Users).join(UserType, isouter=True) # LEFT OUTER JOIN 84 # ret = session.query(UserType).join(Users, isouter=True) # 换下位置就是右连接 85 # print(ret) 86 87 # 子查询 88 # select * from (select * from tb) as B 89 # q1 = session.query(UserType).filter(UserType.id > 0).subquery() # 变成子查询必须加上subquery()函数 90 # res = session.query(q1).all() 91 # print(res) 92 93 # select id ,(select * from users) from usertype 94 # res = session.query(UserType.id, session.query(Users).subquery()).all() 95 # print(res) # 列表里头套元组 96 # 相当于把笛卡尔积搞出来了[(2, 1, 'eric', 'aaa', 1), (1, 1, 'eric', 'aaa', 1), (2, 2, 'sb', 'bbb', 2), (1, 2, 'sb', 'bbb', 2)] 97 # print(session.query(UserType.id, session.query(Users).as_scalar())) 98 # res = session.query(UserType.id, session.query(Users).filter(Users.user_type_id == UserType.id).as_scalar()) 99 # print(res) 100 101 102 # 需求1 拿到用户名字以及对应的用户类型 user_type = relationship("UserType", backref='xxoo') 103 # user_list = session.query(Users, UserType).join(UserType, isouter=True) 104 # for row in user_list: 105 # print(row[0].name, row[1].title) 106 107 # user_list = session.query(Users.name, UserType.title).join(UserType, isouter=True) 108 # user_list = session.query(Users.name, UserType.title).join(UserType, isouter=True).all() all()全部取出来直接加到内存 109 # for row in user_list: 110 # print(type(row)) 111 # print(row[0], row[1], row.name, row.title) 112 113 # user_list = session.query(Users) 114 # for row in user_list: 115 # # print(row.id, row.name, row.user_type) 116 # print(row.id, row.name, row.user_type.title) 117 118 119 # 需求2 获取用户类型及以下的所有用户 user_type = relationship("UserType", backref='xxoo') 120 user_type = session.query(UserType) 121 for row in user_type: 122 # print(row.title, session.query(Users).filter(Users.user_type_id == row.id).all()) 123 print(row.title, row.xxoo) 124 125 session.commit() 126 session.close()
其它


1 # 条件 2 ret = session.query(Users).filter_by(name='eric').all() # 传的参数 3 ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all() # 条件默认是and连接 传的表达式 4 ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all() 5 ret = session.query(Users).filter(Users.id.in_([1,3,4])).all() 6 ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() # ~ 非 7 ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all() 8 from sqlalchemy import and_, or_ 9 ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all() 10 ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all() 11 ret = session.query(Users).filter( 12 or_( 13 Users.id < 2, 14 and_(Users.name == 'eric', Users.id > 3), 15 Users.extra != "" 16 )).all() 17 18 19 # 通配符 20 ret = session.query(Users).filter(Users.name.like('e%')).all() 21 ret = session.query(Users).filter(~Users.name.like('e%')).all() 22 23 # 限制 24 ret = session.query(Users)[1:2] 25 26 # 排序 27 ret = session.query(Users).order_by(Users.name.desc()).all() 28 ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() 29 30 # 分组 31 from sqlalchemy.sql import func 32 33 ret = session.query(Users).group_by(Users.extra).all() 34 ret = session.query( 35 func.max(Users.id), 36 func.sum(Users.id), 37 func.min(Users.id)).group_by(Users.name).all() 38 39 ret = session.query( 40 func.max(Users.id), 41 func.sum(Users.id), 42 func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() 43 44 # 连表 45 46 ret = session.query(Users, UserType).filter(Users.id == UserType.id).all() 47 48 ret = session.query(Users).join(UserType).all() 49 50 ret = session.query(Users).join(UserType, isouter=True).all() 51 52 53 # 组合 54 q1 = session.query(Users.name).filter(Users.id > 2) 55 q2 = session.query(UserType.title).filter(UserType.id < 2) 56 ret = q1.union(q2).all() 57 58 q1 = session.query(Users.name).filter(Users.id > 2) 59 q2 = session.query(UserType.title).filter(UserType.id < 2) 60 ret = q1.union_all(q2).all()