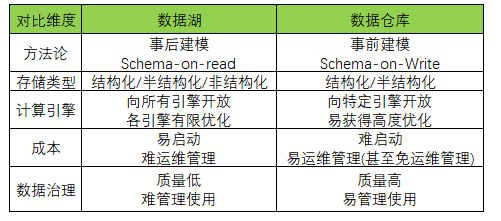
第一个维度是方法论,数据湖其实是一个文件存储系统,用户可以往里面放任何一种文件或者数据,它的一个典型特点是事后建模,它的方法论是用户先把数据放上来,然后再考虑如何使用,也叫做SchemaOnRead。数据仓库正好相反,它是事前建模的模式,当你在把数据推进数据仓库的时候,要求先CreateTable/Schema,这是方法论上的不同。
第二维度存储的形态上,数据湖存储的是文件,数据仓库存储的是表(具体表如何存储对用户不可见)。数据仓库是面向结构化关系表达设计的,因此面向AI这种非结构化数据,存在很大挑战,它几乎不支持音视图类型的数据。而数据湖可以存储所有类型,更灵活更有优势。
第三维度面向计算引擎,数据湖天然是一种更开放的架构,适配更容易,但是几乎也很难做到非常好的端到端优化。举个例子,当客户把数据上传到数据湖上,可能是一个行存的Log文件格式,上层的分析引擎几乎很难跟它做非常好的优化分析(因为非列存、缺乏统计信息和索引的支持)。而数据仓库因为是偏端到端的设计,很难做到开放,但是端到端的优化更容易。
第四个维度从成本层面看,数据湖非常容易上手,它就是个存储系统,你只要把数据放上去就形成了一个数据湖。但随着数据量的增长,运维管理会越来越困难,所以有很多数据湖最终有可能变成数据沼泽(比如,大家也不知道这个数据属于谁,该被谁来用,能不能删掉,应该怎么治理),这是数据湖面临的一个问题。
第五个维度,而数据仓库在把数据上传之前要事先建模,而且大多数数据仓库建立之初要有一个有关整体数据模型的顶层设计,所以数据仓库的启动的成本很高。但是这种很好的顶设规划,会使数据仓库在日后扩展时的运维和管理成本变得更低,使得它长线的成本优势变得非常明显。从这个层面看,数据仓库的数据质量高,也容易管理和治理,数据湖相对难一些。
从上述五个对比维度去看数据湖和数据仓库,这两个体系可以说是硬币的两个面。现在很多厂商开始考虑怎么在数据湖上应用更多数据仓库技术,反过来数据仓库厂商也希望用数据湖的技术使自己更开放,这两个技术在互相学习和融合,最终催生了一个新的技术热点,也就是湖仓一体。
实际上湖仓一体有两个流派,第一个流派是以数仓这种方式诞生的,它是一个左右派,左边是一个数据仓库,右边是一个数据湖,中间以高速网络相连形成一个反对式的联动;第二个流派是从数据湖向数仓演进,整体架构是在数据湖上搭建数据仓库。这两个流派的代表分别是AWS Redshift/阿里云MaxCompute,以及Databricks,目前这两个流派都还在发展中。
虽然湖仓一体是目前的热点,但它仍然是一个新兴方向,还有非常多未知的问题要解决。