最近一直在尝试用pytorch版本的Tiny yolo v3,来训练自己的数据集。为记录下整个过程,在原创博客:https://blog.csdn.net/sinat_27634939/article/details/89884011的基础上,补充了一点东西。
主要流程分为六步:
一、数据集制作
1、首先,我们要对自己的数据进行标注,使用的工具是labelimg。Iabelimg可以直接网页搜索下载exe,运行使用。也可以在python的环境下,输入命令:pip install labelimg,在conda管理的python环境中安装labelimg,运行方法就是直接在该conda环境下CMD输入labelimg即可运行。labelimg打开后的效果如下图所示。
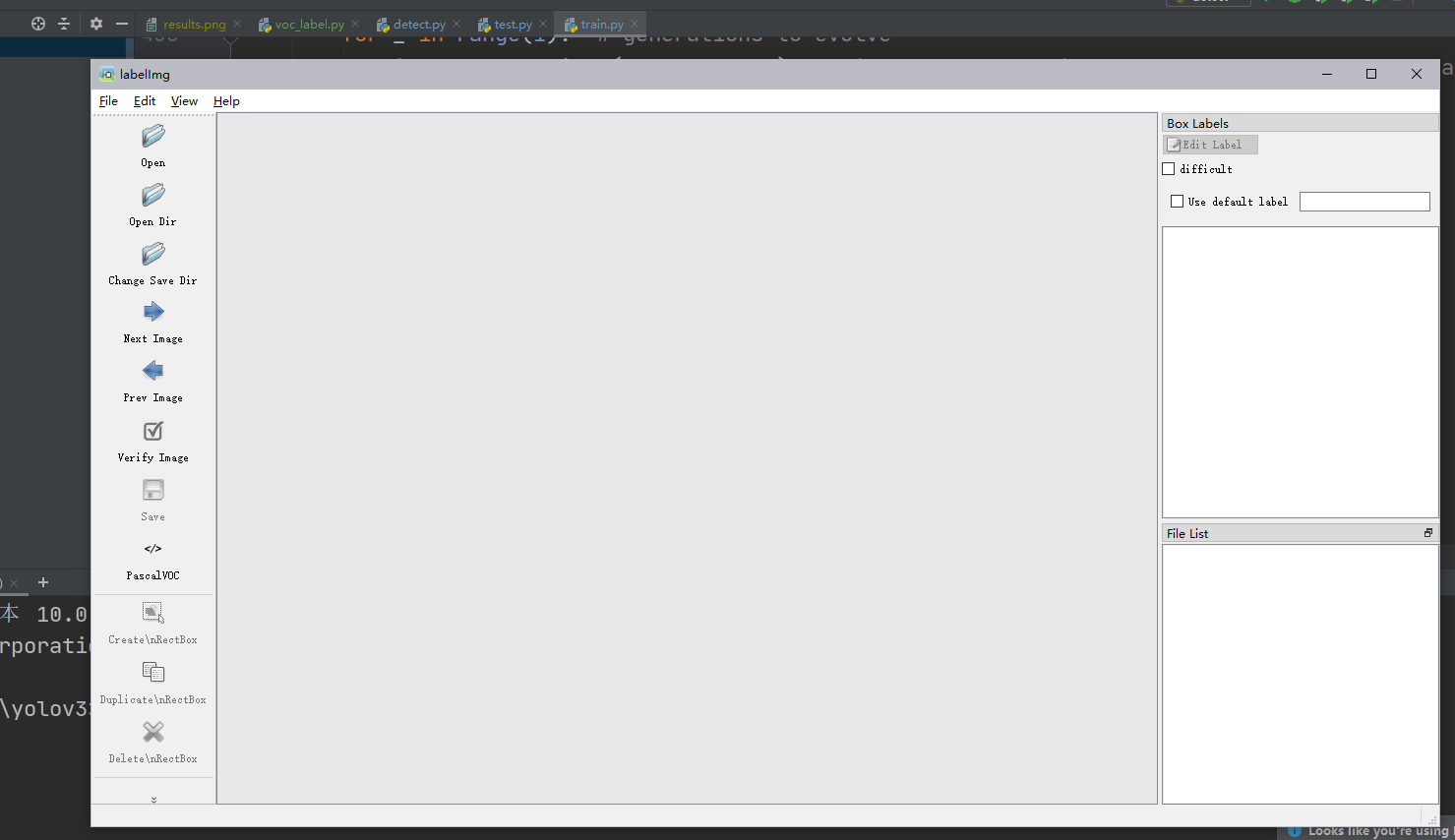
之后,将你的数据集图像所在文件夹设置为Open Dir,新建一个文件夹作为存在Annotation的文件夹,设置为Change Save Dir,标注得到的xml文件格式如下所示。
<annotation> <folder>Desktop</folder> <filename>BloodImage_00000.jpg</filename> <path>/Users/xxx/Desktop/BloodImage_00000.jpg</path> <source> <database>Unknown</database> </source> <size> <width>640</width> <height>480</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>cell</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>200</xmin> <ymin>337</ymin> <xmax>304</xmax> <ymax>446</ymax> </bndbox> </object> </annotation>
其中,最主要的部分就是bndbox内的,就是我们所标记的人工标注框。
注:在标记数据之前,最好先把图片数据的文件名修改一下,这里放一个我的文件批量重命名代码链接:https://gitee.com/alexbd/rename_file_all
虽然写的文件名是视频文件批量重命名,但是,只要对文件后缀进行修改,就可以对任何文件夹内的同一格式文件进行批量重命名。
二、训练代码
YOLO有官方的代码,我们这里采用的是github上的链接:https://github.com/ultralytics/yolov3,git下来。之后建议创建一个专门用于yolo的conda环境,安装pytorch等需要的包,详细见requirements文件。
另外,为了更好的训练,需要安装apex。
安装apex方法:
1、从该链接:https://github.com/NVIDIA/apex 链接上git到你的电脑上;
2、从里面的requirements文件中依次安装需要的依赖包。
在你这个yolo的conda环境下,依次执行:
pip install cxxfilt pip install tqdm pip install numpy pip install PyYAML pip install pytest
3、完成后,在apex的根目录下,python运行安装apex命令,
python setup.py install
当看到如下图示时,就说明安装apex成功了。

三、数据预处理
为了能够用clone下来的工程进行训练和预测,我们需要对数据进行处理,以适应相应的接口。
1、将细胞数据Annotations和JPEGImages放入data目录下,并新建文件ImageSets,labels,复制JPEGImages,重命名images,

2、在根目录下新建makeTxt.py,将数据分成训练集,测试集和验证集,其中比例可以在代码设置,代码如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '
'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
在ImageSets得到四个文件,其中我们主要关注的是train.txt,test.txt,val.txt,文件里主要存储图片名称。

3、运行根目录下voc_label.py,得到labels的具体内容以及data目录下的train.txt,test.txt,val.txt,这里的train.txt与之前的区别在于,不仅仅得到文件名,还有文件的具体路径。voc_label.py的代码如下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ["RBC"]#我们只是检测细胞,因此只有一个类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '
')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg
' % (image_id))
convert_annotation(image_id)
list_file.close()
labels文件下的具体labels信息

data目录下train.txt

四、配置文件
1.在data目录下新建rbc.data,配置训练的数据,内容如下
classes=1 train=data/train.txt valid=data/test.txt names=data/rbc.names backup=backup/ eval=coco
2.在data目录下新建rbc.names,配置预测的类别,内容如下

3.网络结构配置,在原工程下cfg目录下有很多的yolov3网络结构,我们本次采用的是yolov3-tiny.cfg

具体参数的意义可以参考博客YOLOV3实战4:Darknet中cfg文件说明和理解和yolo配置文件的参数说明和reorg层的理解!
因为我们只是估计了一个类,所以需要对cfg文件进行修改,yolov3-tiny.cfg
[net] # Testing batch=1 subdivisions=1 # Training # batch=64 # subdivisions=2 width=416 height=416 channels=3 momentum=0.9 decay=0.0005 angle=0 saturation = 1.5 exposure = 1.5 hue=.1 learning_rate=0.001 burn_in=1000 max_batches = 500200 policy=steps steps=400000,450000 scales=.1,.1 [convolutional] batch_normalize=1 filters=16 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=1 [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky ########### [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=18 activation=linear [yolo] mask = 3,4,5 anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 classes=1 num=6 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1 [route] layers = -4 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = -1, 8 [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=18 #3*(class + 4 + 1) activation=linear [yolo] mask = 0,1,2 anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 classes=1 num=6 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1
注:修改的地方主要是filter,因为我们每一个网格就预测3个anchor结果,所以filter =3*(1 + 5)=18
4.获取官网已经训练好的网络参数yolov3-tiny.weights,下载链接https://pjreddie.com/media/files/yolov3-tiny.weights,导入weights目录下,需要自己创建weights文件夹,由于需要进行fine-tune,所以需要对yolov3-tiny.weights进行改造,因而需要下载官网的代码https://github.com/pjreddie/darknet,运行一下脚本,并将得到的yolov3-tiny.conv.15导入weights目录下,脚本如下
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
这里,直接提供yolov3-tiny.conv.15下载地址。
如果是其他结构的网络,那么可以参考download_yolov3_weights.sh中的说明,里面有详细的介绍。
五、训练
一切准备妥当,我们就可以开始训练了,训练脚本如下
python train.py --data data/rbc.data --cfg cfg/yolov3-tiny.cfg --epochs 10 --weights weights/yolov3-tiny.weights
训练时,可能会有报错:SyntaxError:unexpected character after line continuation character。
报错:SyntaxError: unexpected character after line continuation character的解决方法
得到训练好的模型best.pt

训练结果如下(这里只有10次迭代的结果)

六、预测
我们将得到的模型进行预测,这里代预测的图片我们放在data/samples目录下

运行以下脚本
python detect.py --name data/rbc.data --cfg cfg/yolov3-tiny.cfg --weights weights/best.pt
注:代码中用的是pt后缀保存权重文件,用.pth也是可以的,只要代码中所有地方都统一。
得到的结果可以在output目录

可以看出来效果一般,主要我们的网络结构较简单,同时迭代的次数较少。
知识补充:关于 混淆矩阵、准确率(accuracy)、查准率(精度)(Precision)、查全率(召回率)(recall)、Roc、AUC、和MAP
混淆矩阵
对于二分类问题,可将样例根据其真实类别与分类器预测类别的组合划分为:
真正例(true positive):将一个正例正确判断为正例
假正例(false positive):将一个反例错误判断为正例
真反例(true negative):将一个反例正确判断为反例
假反例(false negative):将一个正例错误判断为反例
令TP、FP、TN、FN分别表示对应的样例数,这四个指标构成了分类结果的混淆矩阵:
分类结果混淆矩阵
| 正例(预测结果) | 反例(预测结果) | |
| 正例(真实情况) | TP(真正例) | FN(假反例) |
| 反例(真实情况) | FP(假正例) | TN(真反例) |
样例总数 = TP + FP + TN + FN
准确率(accuracy)
accuracy = (TP+TN)/TP+FP+TN+FN
查准率 = 精度 = precision = TP/(TP+FP) : 模型预测为正类的样本中,真正为正类的样本所占的比例
查全率 = 召回率 = recall = TP/(TP+FN) : 模型正确预测为正类的样本的数量,占总的正类样本数量的比值
一般来说,查准率高时,查全率往往偏低;查全率高时,查准率往往偏低。
P-R曲线:查准率-查全率曲线:precision为纵轴,recall为横轴
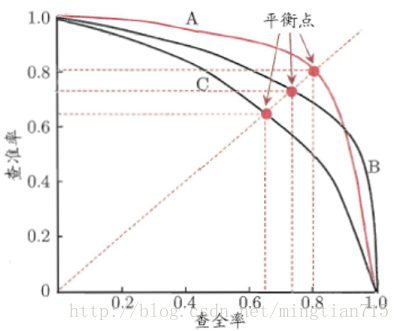
第一种: 若学习器的P-R曲线被另一个学习器完全“包住”,则后者的性能优于前者;
第二种: 若两个学习器的P-R曲线发生了交叉,可以运用平衡点(Break-Even Point,BEP),即根据在“查准率=查全率”时的取值,判断学习器性能的好坏。
第三种: 若两个学习器的P-R曲线发生了交叉,亦可以使用F1/F_eta度量,分别表示查准率和查全率的调和平均和加权调和平均。
其中,F2分数中,召回率的权重高于准确率,而F0.5分数中,准确率的权重高于召回率。
F_eta的物理意义就是将准确率和召回率这两个分值合并为一个分值,在合并的过程中,召回率的权重是准确率的eta倍。
F1分数认为召回率和准确率同等重要,F2分数认为召回率的重要程度是准确率的2倍,而F0.5分数认为召回率的重要程度是准确率的一半。
第四种: 若两个学习器的P-R曲线发生了交叉,亦可以使用APMAP:即计算P-R曲线下的面积
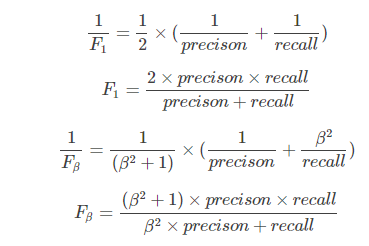
关于mAP转自
链接:https://www.zhihu.com/question/53405779/answer/993913699
来源:知乎
评价指标 mAP
下面用一个例子说明 AP 和 mAP 的计算
先规定两个公式,一个是 Precision,一个是 Recall,这两个公式同上面的一样,我们把它们扩展开来,用另外一种形式进行展示,其中 all detctions 代表所有预测框的数量, all ground truths 代表所有 GT 的数量。
AP 是计算某一类 P-R 曲线下的面积,mAP 则是计算所有类别 P-R 曲线下面积的平均值。
假设我们有 7 张图片(Images1-Image7),这些图片有 15 个目标(绿色的框,GT 的数量,上文提及的 all ground truths)以及 24 个预测边框(红色的框,A-Y 编号表示,并且有一个置信度值)
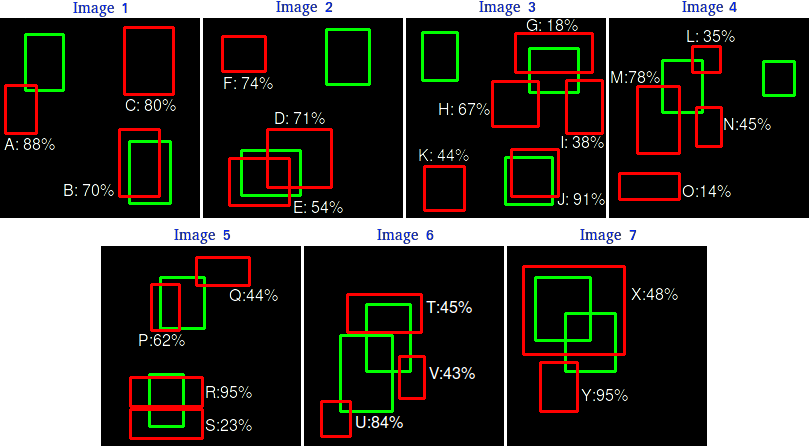
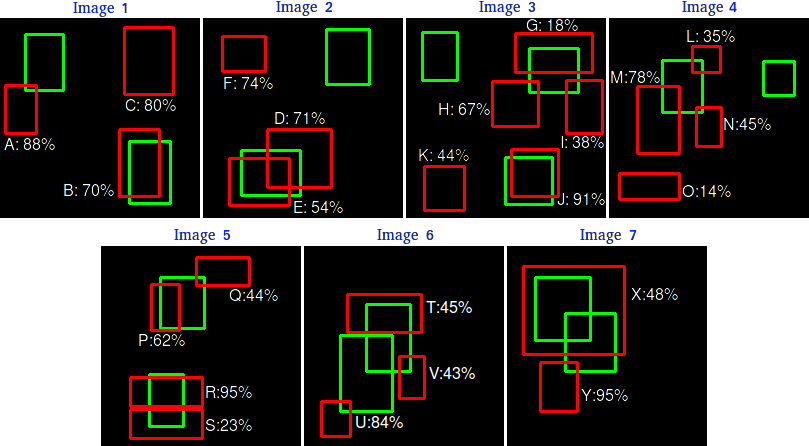
根据上图以及说明,我们可以列出以下表格,其中 Images 代表图片的编号,Detections 代表预测边框的编号,Confidences 代表预测边框的置信度,TP or FP 代表预测的边框是标记为 TP 还是 FP(认为预测边框与 GT 的 IOU 值大于等于 0.3 就标记为 TP;若一个 GT 有多个预测边框,则认为 IOU 最大且大于等于 0.3 的预测框标记为 TP,其他的标记为 FP,即一个 GT 只能有一个预测框标记为 TP),这里的 0.3 是随机取的一个值。


通过上表,我们可以绘制出 P-R 曲线(因为 AP 就是 P-R 曲线下面的面积),但是在此之前我们需要计算出 P-R 曲线上各个点的坐标,根据置信度从大到小排序所有的预测框,然后就可以计算 Precision 和 Recall 的值,见下表。(需要记住一个叫累加的概念,就是下图的 ACC TP 和 ACC FP)
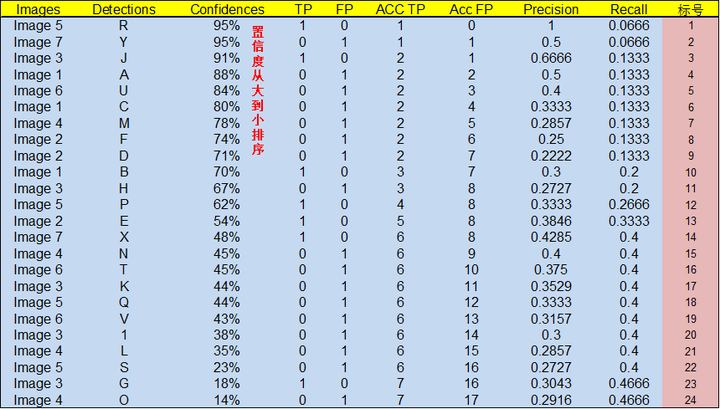
- 标号为 1 的 Precision 和 Recall 的计算方式:Precision=TP/(TP+FP)=1/(1+0)=1,Recall=TP/(TP+FN)=TP/(
all ground truths)=1/15=0.0666 (all ground truths 上面有定义过了) - 标号 2:Precision=TP/(TP+FP)=1/(1+1)=0.5,Recall=TP/(TP+FN)=TP/(
all ground truths)=1/15=0.0666 - 标号 3:Precision=TP/(TP+FP)=2/(2+1)=0.6666,Recall=TP/(TP+FN)=TP/(
all ground truths)=2/15=0.1333 - 其他的依次类推
然后就可以绘制出 P-R 曲线
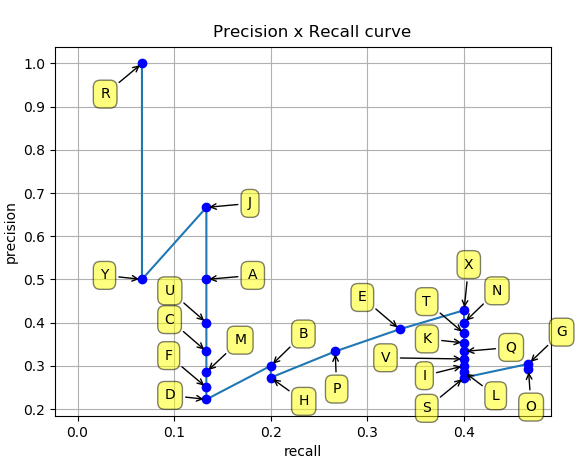
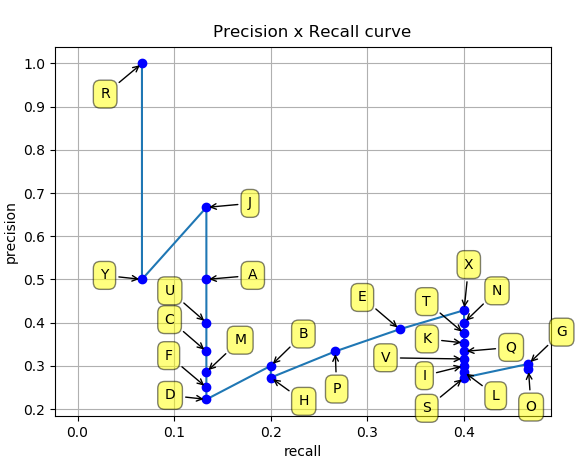
得到 P-R 曲线就可以计算 AP(P-R 曲线下的面积),要计算 P-R 下方的面积,一般使用的是插值的方法,取 11 个点 [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1] 的插值所得
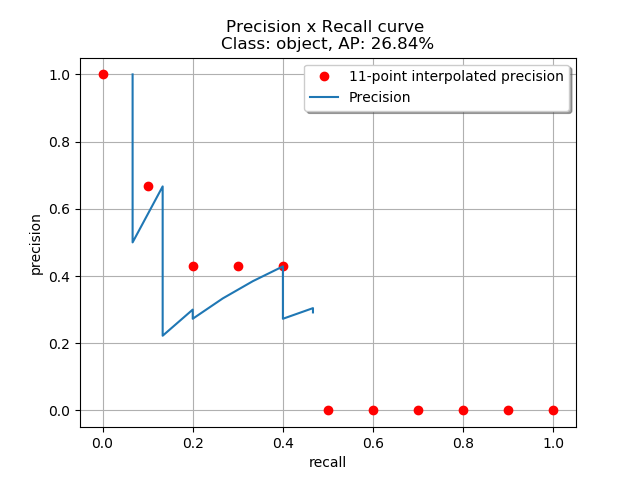
得到一个类别的 AP 结果如下:
要计算 mAP,就把所有类别的 AP 计算出来,然后求取平均即可。