什么是索引?
数据库索引是数据库管理系统中一个排序的数据结构,协助快速排序,更新数据库表的数据,索引在mysql innodb引擎中采用的是B+树(支持B树的,但是基本不用)。
使用B+树会用更多的优点(在查询效率、存储空间等方面都能够超过与B树、二叉搜索树、hash结构存储等)。
普通索引和唯一索引在查询效率上的不同
1、创建索引的时候可以是普通索引也可以是唯一索引,唯一索引是在普通索引上增加了唯一这个约束性,找到了关键字就停止检索。
而普通索引,可能会在用户记录中存在相同的关键字,根据页结构的原理当我们读到一条数据,不是单独读这一条,加载的是一个页
但是这个时候是加载到了内存中,对于CPU的消耗来说是没什么太大的影响。唯一索引和普通索引都可以为null,但是主键索引不行。
创建索引的方式
1、create index on tablename(fieldname)
2、create table t1(
tid int,
tname varchar(20),
index [indexname](finame)
);
3、alter table tableName add unique index indexName (fieldName);
索引设计原则(11条):
1、字段的数值有唯一性的性质,可以创建唯一的索引,可以创建主键索引(唯一索引可以为null值)
业务上具有唯一特性的字段,即使是组合字段,也必须建立唯一索引(alibaba开发手册建议)。
说明:不要以为唯一索引会影响insert的速度,这个速度其实是可以忽略不计,但调高查找速度是很明显的。
2、频繁wehere查询的条件的字段
某个字段在select和where条件中经常使用,那么就应该给该字段建立索引,在数据量大的时候可以大幅提升数据查询效率。
3、经常使用groupby和orderby的列
索引就是让数据按照某种顺序进行存储和检索,因此当我们使用group by或者order by本身就是一种排序,就需要对分组和排序的字段进行索引。
4、Update、Delete的where条件需要加索引
原因是因为先根据where条件检索出这条记录,然后对他更新或者删除。
如果进行更新的时候,更新的字段是非索引字段提升效率更明显,因为非索引字段不需要对其维护。
5、distinct字段需要创建索引
有时候需要对某个字段进行去重,使用distinct,那么对这个创建索引会提升效率。
6、多个表进行join连接操作,创建索引注意思想
连接的表不能超过三张。因为每增加一张表相当于增加了一层嵌套循环,数据量急剧增加,性能会降低很多。
其次对where条件创建索引,因为where才是对数据的过滤,在数据量很大的情况,没有where条件是很可怕的
最后是的连接字段进行建立索引,并且多张表的编码类型,数据类型必须要一致。
7、使用列类型小的创建索引
之所以选择数据量小的的建索引是因为,数据类型更小,索引占用的空间就越少,在一个数据也中就可以存更多的数据记录。减少I/O性能损耗。提高读写性能
8、使用字符串前缀创建索引
根据aliaba开发手册,在字符串上建立索引,必须指定索引长度,没有必要对全字段进行索引创建。如果是二级索引占用的空间会更少。
9、区分度高的列适合作为索引
区分度计算公式:select count(distinct col)/count(*) from table,越接近1越好。
10、使用频繁的列放到联合索引的最左侧
通常说的最左前缀匹配原则,通俗来将就是where后经常使用的放在最左边
11、在多个字段都要创建索引的情况下,联合索引优于单值索引
区分度会更好。
注意:一张表的索引数目不要超过6个,索引数过多,占用的空间也是非常大的,索引在insert等操作时会影响性能,
索引多的时候,优化器 会判定的更久。
不适合建立索引的情况
1、在where中使用不到的字段,不设置索引
2、数据量小的表最好不要使用索引
3、有大量重复数据不要创建索引
4、避免经常更新的字段建立过多的索引
5、不建议用无序的值来索引
6、及时删除不使用或者很少使用的索引
7、不要定义冗余或者重复的索引。
mysql中调优的一个总体决策建议:
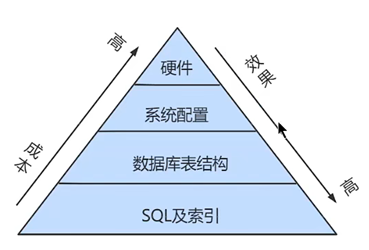
1、 通过查看系统的性能参数 show profile命令可以查看执行的每一步时间,目前开始用information_schema中查看profiling的数据
2、开启慢查询日志,默认没开启,因为会消耗性能。
3、慢查询long_query_time和变量min_examined_row_limit查看最小记录数。
4、通过explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,
字段概述:
id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型(比较的重要)
alibaba开发手册:

possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
1、Innodb与Myisam的区别:
自增、索引、加密、死锁、共享锁、取消查询缓存,多个方面做了改进和优化、支持事物,行锁与外键。
2、索引按照功能划分:
功能:单列索引、组合索引、全文索引、空间索引。
单列索引:普通索引、唯一索引、主键索引(普通索引与唯一索引可以包含null)
总体可以分为:聚簇索引和非聚簇索引(二级索引或辅助索引)

record_type=0是普通用户记录
record_type=1是目录项
record_type=2是最小记录
record_type=3是最大记录
目录页存的是主键值和页码
叶子节点真实的数据记录和record_type
注意:在每个页中还存在一个页目录、页面头部(槽位,对页中的记录进行分组,更容易进行二分法找到单链表中的数据)
面试题:B+树为什么是3层
指针在innodb中指针大小是6字节、主键为4字节(模拟)、innodb默认页大小是16KB
在叶子节点中模拟单条数据记录为100字节。那么单个叶子节点可以有(16KB=(16*1024Byte))/100Byte=163条数据(每页的行数)。
假如是一层那么就只能存放163条数据。
假如是两层那么就能存放16*1024=16384,单个数据页的大小。16384/10=1638条记录(非叶子节点记录数),1638*163=266994
假如是三层那么就能存放1638*1638*163= 4,3733,6172条数据(上亿了)。 (并且IO次数其实只需要最大层数-1,因为根节点是常驻内存的)。
假如是四层那么就能存放1638*1638*1638*163= 716,356,649,736 完全够用了。
面试题:聚簇索引与非聚簇索引的原理和使用的区别:
1、聚簇索引的叶子节点存储的是我们的数据记录,非聚簇索引的叶子节点存储的是数据位置。非聚簇索引不会影响数据表的物理存储顺序。
2、一个表只能有一个聚簇索引,因为只能有一种排序存储方式,但是可以有多个非聚簇索引,也就是多个索引目录提供数据检索
3、使用聚簇索引效率更高,因为会少回表操作。但是如果对数据进行插入、删除、更新等操作,效率会比非聚簇索引更低。因为可能会拆分数据页,聚簇索引中的数据很多,效率会更低。
为什么使用的B树、B+树、采用hash算法进行存储、二叉搜索树?
Mysql执行流程:
1、客户端->词法解析器->语法解析器->生成解析树->优化器->执行器->到存储引擎中取数据。
注意很多人不知道的点:mysql5中在客户端和词法分析器之前会有一个 查询缓存 ,但是在mysql8以后取消了,因为mysql团队
认为这只是一个鸡肋步骤。
(查询缓存效果取决于缓存命中率,而命中缓存才能有所改善,无法估计性能,并不稳定
其次,查询缓存的另一个问题就是受到互斥锁的保护,会导致大量的请求锁竞争)
但是重点:mysql8中不存在查询缓存,但是有缓冲池,它们并不是一个东西,真正能影响sql执行效率的点在缓冲池中。
1、查询缓存是根据查询语句和查询结果,缓存起来,下次直接在客户端输入sql语句后直接获取数据
2、缓冲池在执行器读取数据后写到内存中的缓冲池中,以页(数据页,索引页)的方式存储在缓冲池中。
3、缓冲池默认大小是128M
4、执行器在物理硬盘读取数据后,加载到缓冲池中,然后再从缓冲池中读取数据到引擎中。
5、如果更新了数据update,先更新缓冲池中的数据,然后再以一定的频率刷到硬盘上。
数据库事物
四大特性ACID
原子性Atomicity

一致性Consistency

隔离性Isolation

持久性durability

mysql 并发情况造成的问题
1、脏写
对应两个事务SessionA SessionB,如果事务SessionA修改了另一个未提交事务B修改过的数据,并提交了,就发生了脏写。
2、脏读
对于两个事务SessionA SessionB,SessionA读取了已经被SessionB更新但还没提交的字段。之后若SessionB回滚,SessionA读取的内容临时且无效。
3、不可重复读
对于事务SessionA、SessionB,SessionA读取了一个字段,然后SessionB更新了该字段,并且提交了。之后SessionA再次读取同一字段,值就不同了,那就意味着发生了不可重读。
4、幻读
对于事务A、事务B,SessionA 从一个表中读取了一个字段,然后SessionB在改表中插入了一些行,并提交。之后如果SessionA再次读取同一个表,就会多出几行。意味着幻读。
Mysql 中四大隔离级别(默认是 可重复读 RR Repeatable Read)
1、读未提交read uncommitted
2、读已提交read commited
3、可重复读Repeatble READ
4、可串行化 serializable
主从复制
1、提高吞吐量
2、数据备份
3、高可用性
主从复制原理
步骤:

Slave从master读取binlog来进行数据同步。 (一共有三个线程)
Thread1:主机中的线程将binary log转储到slave节点。
Thread2:从机IO线程写入到relay log中
Thread3:SQLThread读取relay log同步到数据库中。
复制的基本原则:
1、 每个slave只有一个master
2、 每个slave只能有一个唯一的id
3、 每个master可以有多个slave
分布式mysql的数据同步一致性
1、读库和写库的数据一致
2、写数据必须写到写库
3、读数据必须到读库(不一定确定某一台机器)
方法一:异步复制(一致性较差)
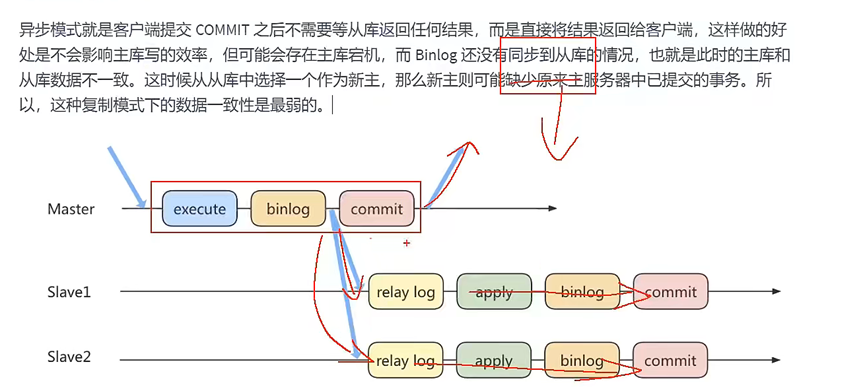
方法二:半同步复制

方法三:Paxos算法

mysql repeatable read可以解决幻读吗?
Innodb存储引擎在Repeatable read级别下通过MVCC和Next-key lock来解决幻读。
1、执行普通的select,此时会 以MVCC快照读的方式读取数据
在快照读的情况下,RR隔离级别只会在事务开启后第一次查询read view,并使用至事物提交后。所以在生成Read view之后其他事物所做的更新、插入
等对当前事物是并不可见的,实现了可重复读下的幻读。
2、执行 select...for update/lock in share mode、insert、update、delete 等当前读
在当前读下读取的最新数据,如果有insert和update等操作,并且刚好在查询范围内,会产生幻读。
innerdb采用间隙锁next-key lock来防止这种情况。当前执行读时,会锁定读取到的记录的同时,锁定他们的间隙,防止其他事务在查询范围内插入数据。只要不让插,就不会发生幻读。
next-key lock本质是一个记录锁+gap锁(前闭后开的锁)的合体,锁定保护该条记录,又组织别的事物将新纪录插入被保护记录的前边的间隙。
(数据库在某一行,加入了X写锁,就不能加其他任何锁了)
MVCC(多版本并发控制)
解决问题:读写或者写读场景
实现原理依赖于:隐藏字段(事物id)、Undo Log(多版本)、Read View
MVCC主要针对Read Committed和Repeatable read两个 隔离级别的事物,保证读到已经提交了的事物修改过的记录。 只有在repeatble read解决了幻读。
这样使InnoDB的事物隔离级别下执行一致性读有了保证。(快照读),不是当前读,当前读是读取最新版本的数据。(不加锁的简单的select都属于快照读)
Mysql中可重复读默认级别,不光解决了不可重复读,同时也解决了幻读的问题。原因就是使用了MVCC+Next-key Lock
隐藏字段、Undolog 版本链
每一条记录:三个隐藏字段(row_id、trx_id、roll_pointer)

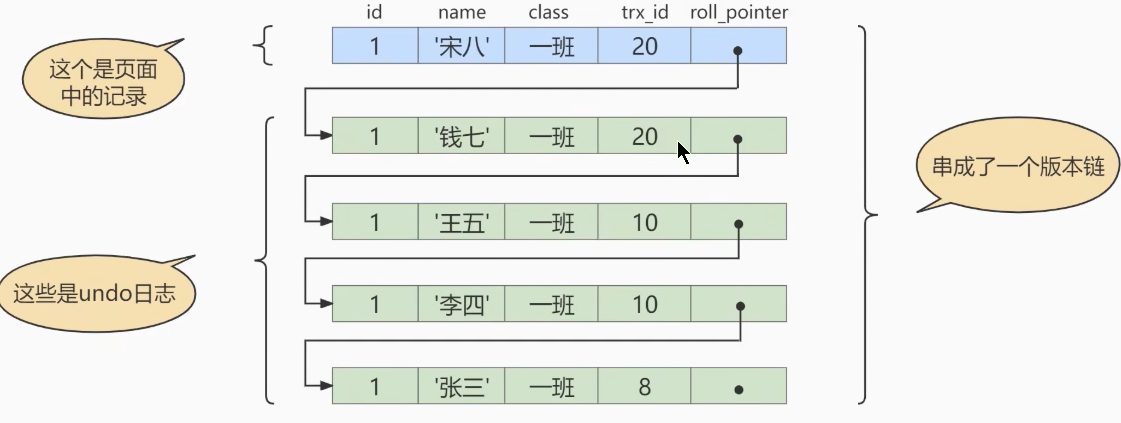
对该记录每次更新后,都会将旧值放到一条undo日志中,所有的版本都被roll_pointer属性连接成一个链表。
Read View

主要四个字段
当前事物id对应一个Read View

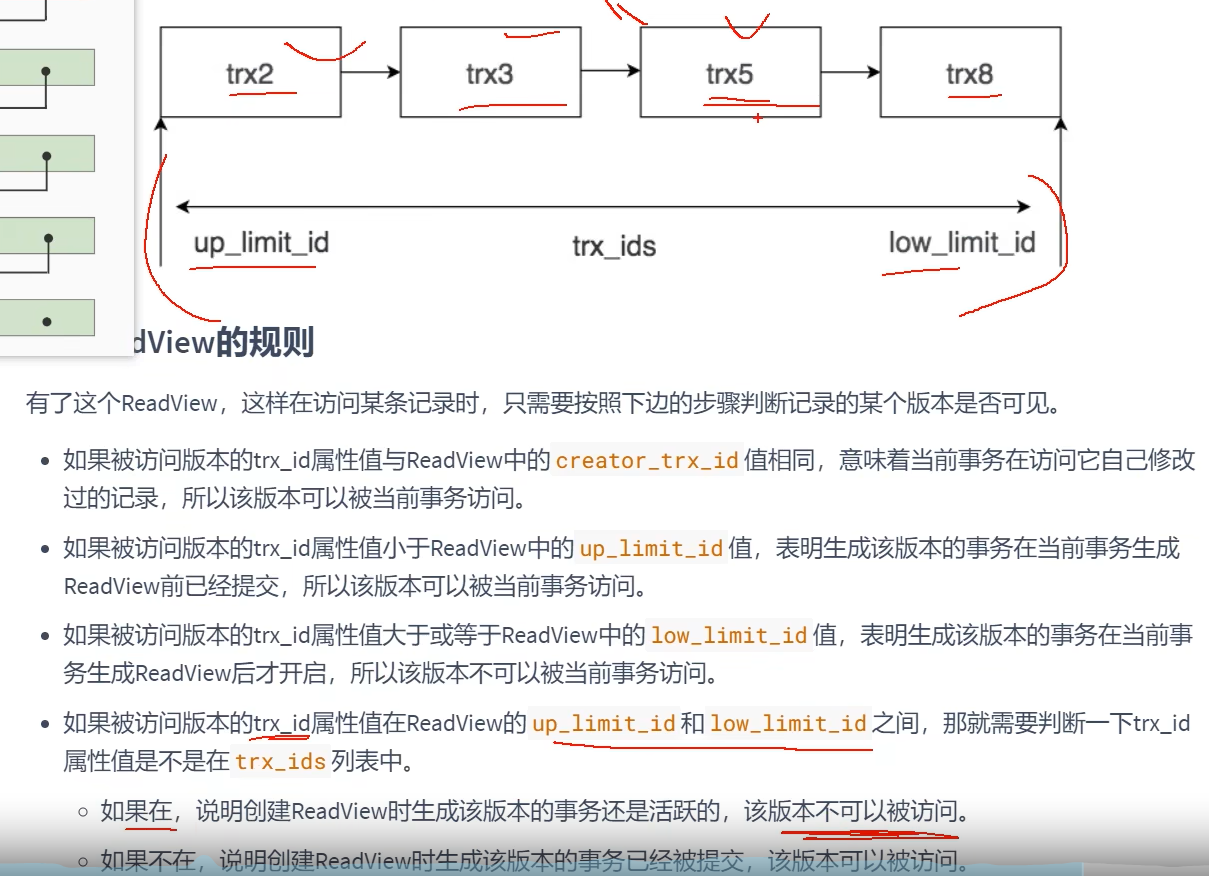
MVCC整体流程

Read Commited一个事物查询都会重新获取一次Read View
Repeatable Read,避免了不可重复读,因为只在第一次获取ReadView
如何解决幻读:(Repeatable Read)
1、MVCC快照读
2、当前度使用Next-key Lock来防止这种情况。