理解并从头搭建redis集群
部分开发人员工作当中只是在应用中使用redis,比如用来做数据结果的缓存。而且现在有很多不错的redis客户端工具(redisson),基本上可以不用关注redis命令就可以完成相当部分的功能。所以可能会对如下这些问题关注点不够:
- 如何容灾?即某个redis节点出了问题如何保证服务的高可用性
- 如何横向扩容?当数据量特别大时,如何解决单个redis的性能问题
- 集群至少需要几台机器?或者几个redis节点
- 集群搭建都利用什么技术,哪些工具?
如何容灾?
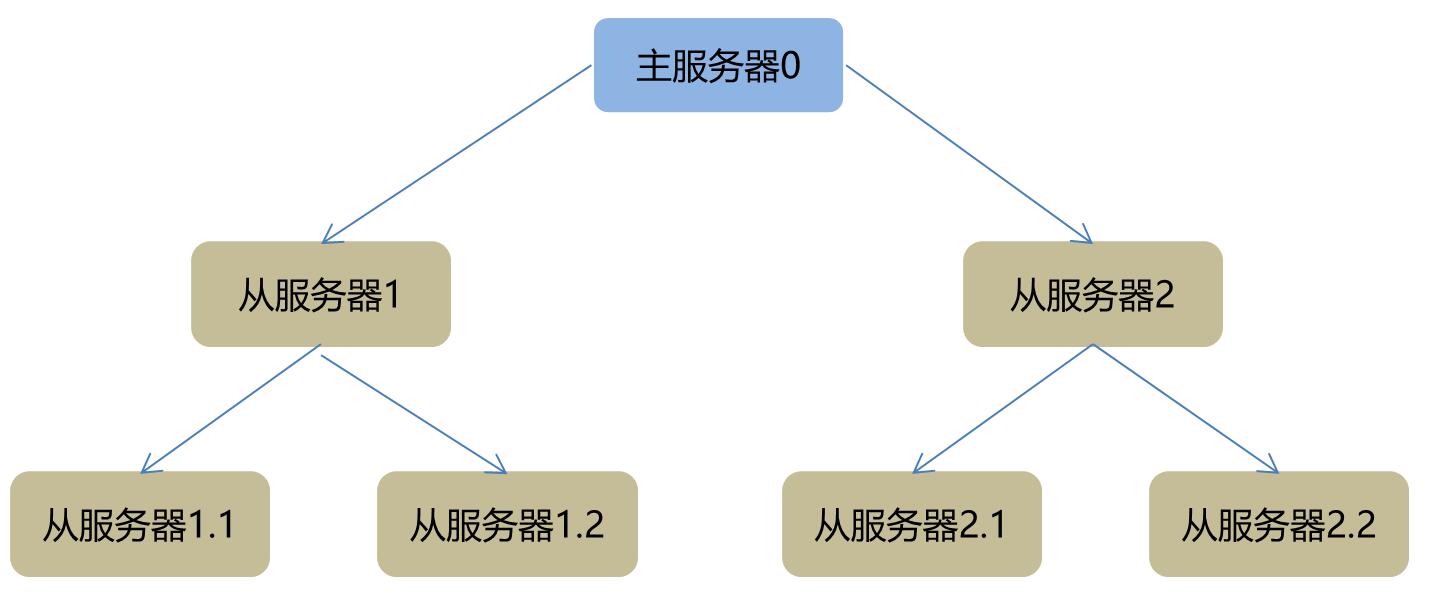
redis提供了主从热备机制,主服务器的数据同步到从服务器,通过哨兵实时监控主服务器状态并负责选举主服务器。当发现主服务器异常时根据一定的算法重新选举主服务器并将问题服务器从可用列表中去除,最后通知客户端。主从是一对多的树型结构,如下图:
哨兵
哨兵是sentinel的中文名称,是redis出的一个高可用架构的工具,自身是一个独立的进程,可以同时监控一个以上的redis集群。
哨兵集群
基于高可用的考虑,哨兵自身也是需要支持集群的,如果只有一个哨兵就会存在单点问题。
哨兵决策
哨兵有一个数量配置,当多少个哨兵同时认为某个主服务不可用时才进行主从切换,比如总共有5个哨兵,当3个哨兵认为服务不可用时才决定做主从切换。这么做可以避免一些误切换,降低切换成本,比如瞬时的网络异常等。
如何横向扩容?
无论是redis还是其它一些数据库之类的产品,当单节点的数据容量达到一定上限后,服务对外提供的能力会越来越弱。redis在高版本中提供了redis-trib.rb来实现集群功能,也可以使用第三方的工具twemproxy。
去中心化,每个节点都是平等的
redis集群从设计上没有考虑中心化,这样可以避免中心节点的单点等问题。每个节点都能掌握整个集群的状态,连接任意的节点都可以访问到所有的key,就像单节点的redis一样。
集群原理图
自己理解画的,如有理解不对的地方可以指出。
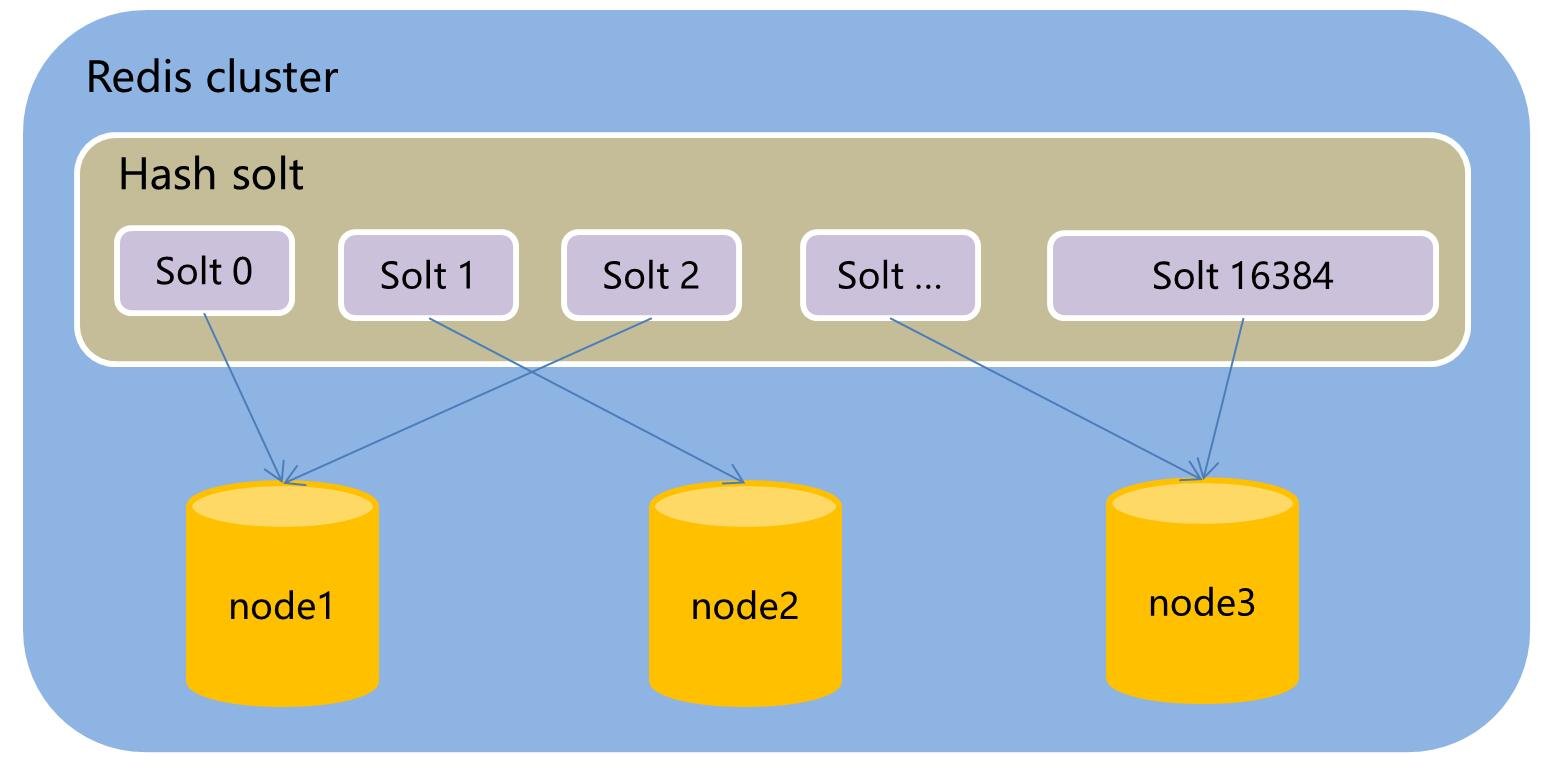
key与redis节点的关系
引入了hasy solt,中文理解为哈希槽。总共16384个,我们操作的key通过取模算法确认key落在哪个槽上。
HASH_SLOT = CRC16(key) mod 16384
哈希槽与节点之间有一定关系,所以我们就可以将key分配到某个具体的redis节点上了。
详细的关系可再研究,简单的比如节点A负责0-5000编号的哈希槽,节点B负责5001-1000
一步一步搭建
开始搭建三主三从的集群,系统是ubuntu,采用redis提供的集群工具redis-trib.rb。
- 安装最新redis
- 创建redis_cluster目录,并且创建7000到7005这6个目录
- 将redis目录下的redis.conf复制到上面创建的6个目录中
- 分别修改redis.conf文件,对6个文件做类似的修改。
port 7000 //端口7000
bind 127.0.0.1 //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip
daemonize yes //后台运行
pidfile /var/run/redis_7000.pid //pidfile文件对应7000
cluster-enabled yes //开启集群
cluster-config-file nodes_7000.conf //集群的配置
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置
bind需要注意的就是需要配置为其它机器可以访问的ip,否则无论是创建集群还是客户端连接都会有问题。
- 启动6个redis
redis-server redis_cluster/7000/redis.conf
redis-server redis_cluster/7001/redis.conf
redis-server redis_cluster/7002/redis.conf
redis-server redis_cluster/7003/redis.conf
redis-server redis_cluster/7004/redis.conf
redis-server redis_cluster/7005/redis.conf
- 创建集群
redis的src目录下有个redis-trib.rb,将它复制到/usr/local/bin中,然后执行如下脚本:
redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
--replicas后面的1代表从服务器的个数,上面可以理解为前面3个为主服务器,后面三个分别做为从服务器,即三对主从。
执行过程中会遇到提示需要安装ruby,安装完成之后又会提示安装 gem redis。
安装gem redis,折腾了好久,最终发现是因为在国内访问不了某些网站导致通过apt-get install安装不成功,最后通过下载源码的方式安装成功。
![]()
再次执行创建集群的脚本,出现如下提示:
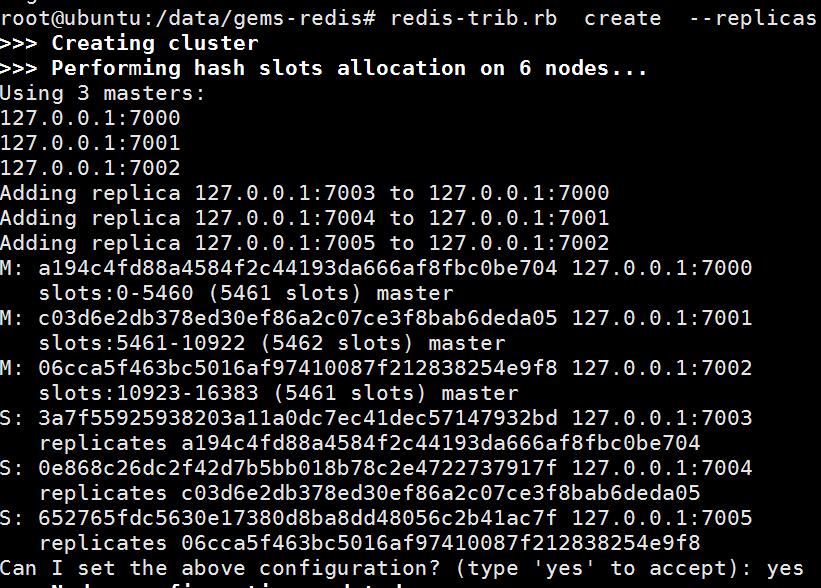
输入yes,继续
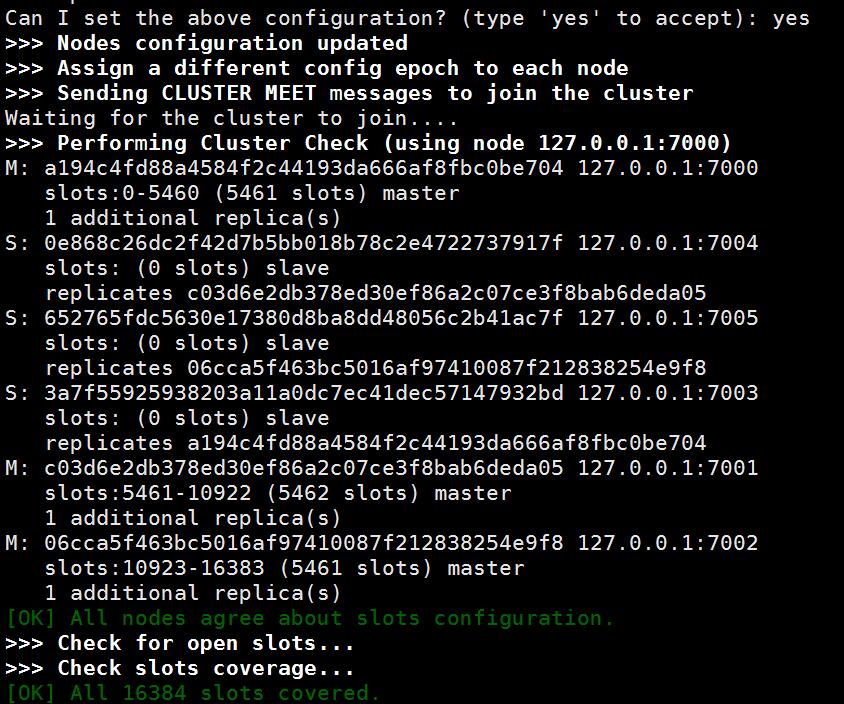
最少需要多少个主服务器?
可能是基于某些约定,集群约定只有当可用节点数大于半数以上时才具备对外提供服务的能力。首先数量一定是奇数,其实必须大于1,所以最少的主服务器数量为3。
- 测试集群
连接客户端,由于我的所有节点都是在本地,所以不需要输入ip,但需要加-c的参数。
redis-cli -c -p 7000
连接成功后,增加一个key
set mykey 123
有一行提示语,指向到端口7002,这说明虽然我们连接的是7000的实例,但通过hash算法最终会将key分配到7002的实例上。

再连接7005端口查询下key,测试下是否任意一个实例都可以查询到key
get mykey
显示指向到端口7002

集群需要注意的地方
这块还未仔细研究,有些命令在集群下是不支持的,待后续求证。
引用
- http://www.cnblogs.com/wuxl360/p/5920330.html
- https://segmentfault.com/a/1190000002680804
- http://blog.csdn.net/lifeiaidajia/article/details/45370377
总结
真实环境的部署与单机部署还是差异比较大的,但也不复杂,尽管部分开发人员可能一辈子都不会有机会在线上搭建redis集群,但了解redis的高可用可扩展的方案对设计大型系统还是有比较大的帮助的,也有助于分析解决线上问题。看了上面的这些,对于本文开头提到的问题就不难理解了。