本文来自公众号“AI大道理”
在YOLOv3中继续改进,提出了一个更深的、借鉴了ResNet和的FPN的网络Darknet-53。

![]() darknet-19
darknet-19
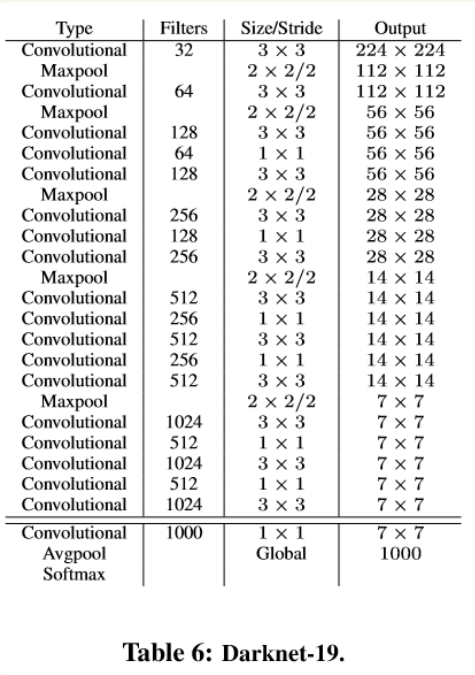
YOLO作者自己写的一个深度学习框架叫darknet,后来在YOLO9000中又提出了一个19层卷积网络作为YOLO9000的主干,称为Darknet-19。
这两者都是用于提取特征的主干网络。
网络使用了较多的3 * 3卷积核,在每一次池化操作后把通道数翻倍。
借鉴了network in network的思想,网络使用了全局平均池化(global average pooling)做预测,把1 * 1的卷积核置于3 * 3的卷积核之间,用来压缩特征。
使用batch normalization稳定模型训练,加速收敛,正则化模型。
最终得出的基础模型就是Darknet-19,包含19个卷积层、5个最大值池化层(max pooling layers )。
Darknet-19处理一张照片需要55.8亿次运算。
![]()
可以看到, Darknet-19 的 stride 为32, 没有 fc 层,而是用了 Avgpool。
![]() darknet-53
darknet-53
![]()
-
主干网络修改为darknet53,其重要特点是使用了残差网络Residual,darknet53中的残差卷积就是进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果, 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
-
darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU。普通的ReLU是将所有的负值都设为零,Leaky ReLU则是给所有负值赋予一个非零斜率。
-
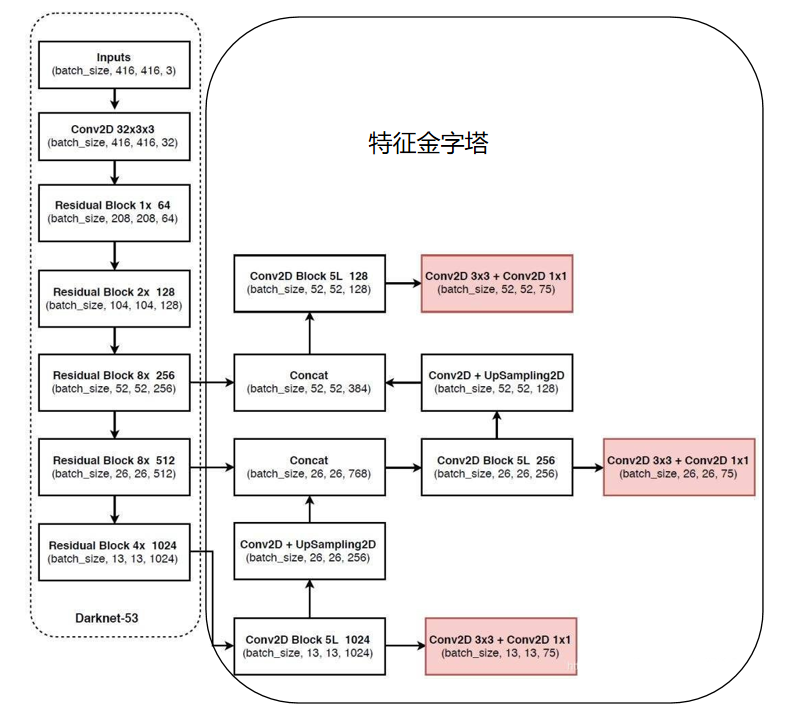
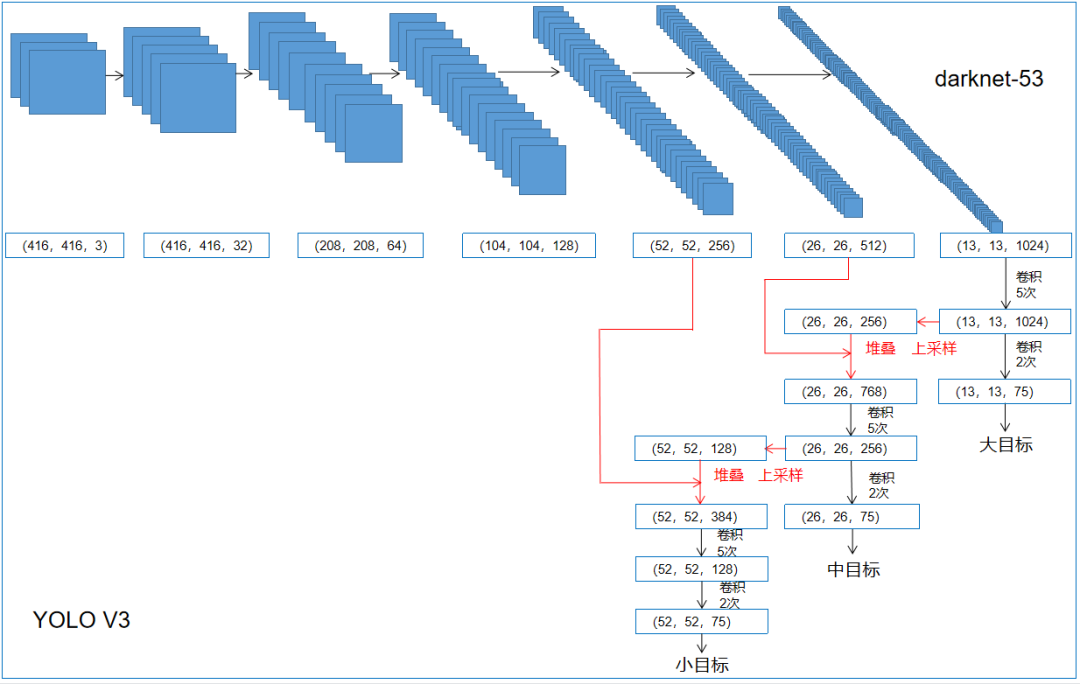
主干特征提取网络进行特征提取,输入一个416*416*3的图片,进行5次下采样,下采样过程中高和宽不断被压缩,通道数不断增加。上采样再进行堆叠的过程就是构建特征金字塔的过程,特征金字塔可以进行多尺度特征融合,提取出更有效的特征。
-
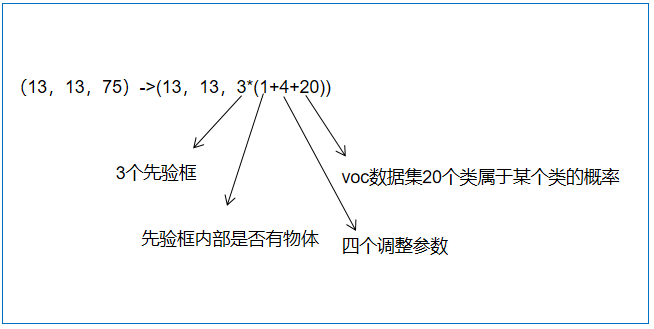
yolo v3的检测过程就是将输入的图片划分成不同的网格,每个网格有3个先验框,判断先验框里面是否有物体,判断物体的种类,然后调整先验框变成预测框。
![]()
![]()
![]() 特征金字塔
特征金字塔
在特征利用部分,yolo3提取多特征层进行目标检测,一共提取三个特征层,三个特征层位于主干部分darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024)。
三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
输出层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,yolo3只有针对每一个特征层存在3个先验框,所以最后维度为3x25;
如果使用的是coco训练集,类则为80种,最后的维度应该为255 = 3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
![]() 代码实现
代码实现
backbone:特征提取
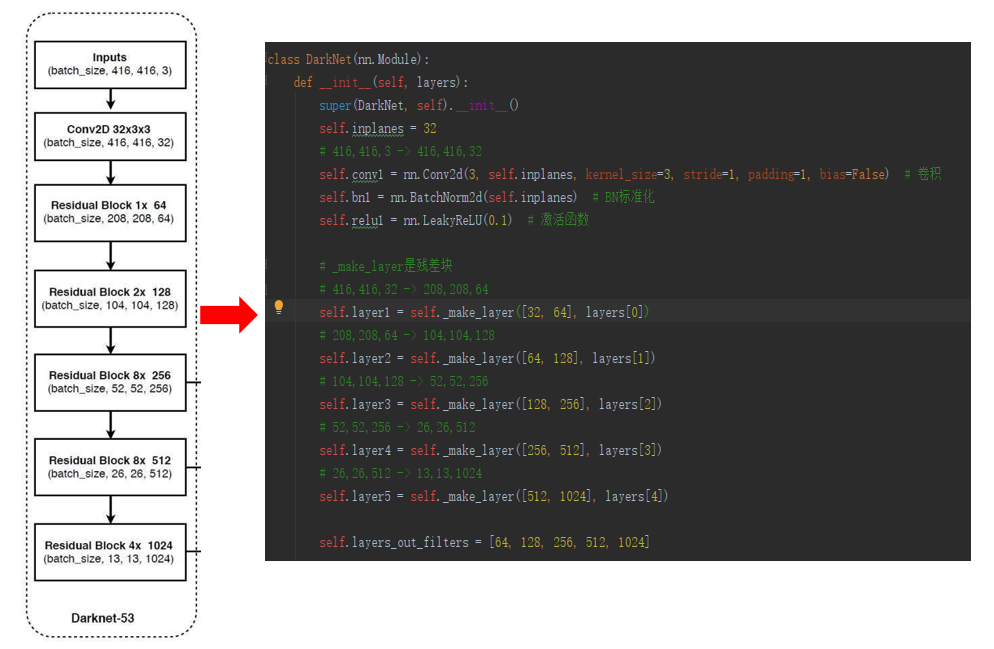
![]()
Residual:残差网络

![]()
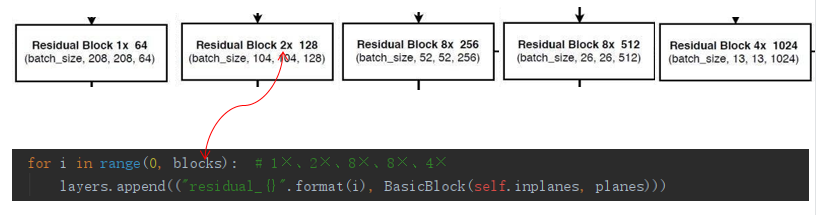
![]()
FPN:特征金字塔
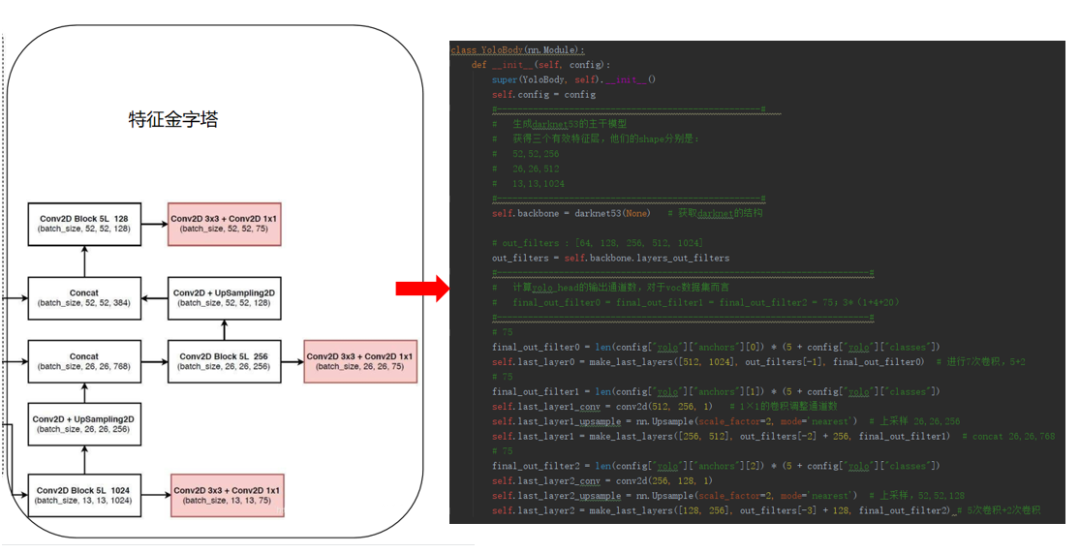
![]()
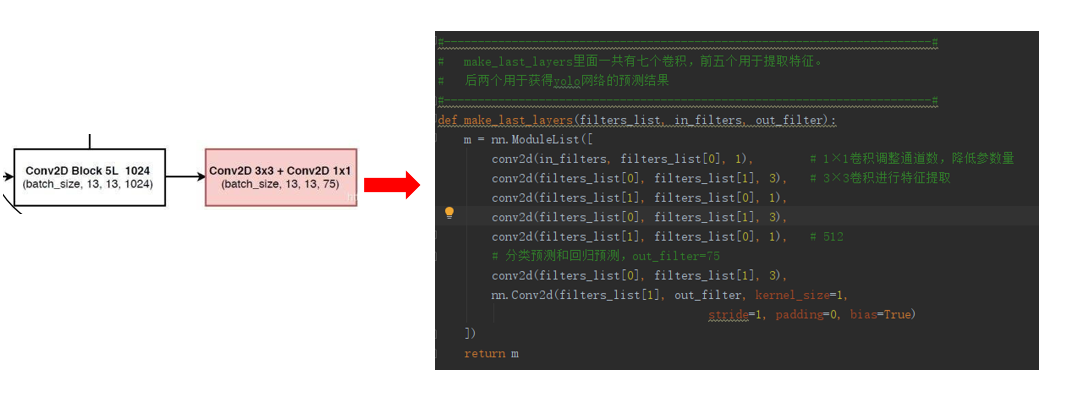
![]()

![]()

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————