本文来自公众号“AI大道理”
目标检测不仅要用算法判断图片中是不是一只鱼,还要在图片中标记出鱼的位置,用边框把鱼框起来,这就是目标检测问题。
其中“定位”的意思是判断鱼在图片中的具体位置。

![]() 滑动窗口分类法(原始)
滑动窗口分类法(原始)
(AI大视觉:撒小渔网,一个小渔网从最旁边的地方撒下去,看有没有鱼,然后移动该渔网继续捕鱼)
首先对输入图像进行不同窗口大小的滑窗进行从左往右、从上到下的滑动。
每次滑动时对当前窗口执行分类器(分类器是事先训练好的)。
如果当前窗口得到较高的分类概率,则认为检测到了物体。
对每个不同窗口大小的滑窗都进行检测后,会得到不同窗口检测到的物体标记,这些窗口大小会存在重复较高的部分,最后采用非极大值抑制(Non-Maximum Suppression, NMS)的方法进行筛选。
最终,经过NMS筛选后获得检测到的物体。
滑窗法简单易于理解,但是不同窗口大小进行图像全局搜索导致效率低下,而且设计窗口大小时候还需要考虑物体的长宽比。
把检测的任务当做是遍历性的分类任务。
对边框的区域进行二分类:属于鱼或者不属于鱼。

![]()
这样不断地滑动,就是遍历性地分类。

![]()
接下来要遍历框的大小:因为刚才是预设一个框的大小,但鱼有大有小,还得遍历框的大小。

![]()
遍历得越精确,检测器的精度就越高。
所以这也就带来一个问题就是:检测的耗时非常大。
分类器的训练:本质上还是训练一个二分类器。这个二分类器的输入是一个框的内容,输出是(前景/背景)。
![]() RCNN
RCNN
那么有必要傻傻的逐一滑动吗?
(AI大视觉:可以用选择性搜索算法提前判断哪些地方可能有鱼(候选区域),然后向这个地方撒一个渔网,看有没有鱼,然后移动到下一个可能的地方继续撒一个渔网捕鱼)

![]()
(打叉的地方不是候选区域就不用判断了)
这就是R-CNN(全称Regions with CNN features)的思想。
RCNN选取了2000个候选区域,预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上提取特征,进行判断。
Region Proposal(候选区域),就是预先找出图中目标可能出现的位置,通过利用图像中的纹理、边缘、颜色等信息,保证在选取较少窗口(几千个甚至几百个)的情况下保持较高的召回率。

![]()
过程:候选框-->CNN-->得到每个候选框的特征-->分类+回归
RCNN算法分为4个步骤
-
一张图像生成1K~2K个候选区域
-
对每个候选区域,使用深度网络提取特征
-
特征送入每一类的SVM 分类器,判别是否属于该类
-
使用回归器精细修正候选框位置
候选区域生成:
选择性搜索。
使用了Selective Search1方法从一张图像生成约2000-3000个候选区域。
基本思路如下:
使用一种过分割手段,将图像分割成小区域,查看现有小区域,合并可能性最高的两个区域。
重复直到整张图像合并成一个区域位置,输出所有曾经存在过的区域,所谓候选区域。
候选区域生成和后续步骤相对独立,实际可以使用任意算法进行。
![]() Fast RCNN
Fast RCNN
有必要将每个区域都输入CNN进行特征提取和进行判断吗?
(AI大视觉:可以用选择性搜索算法提前判断哪些地方可能有鱼(候选区域),然后向这些地方一起撒很多渔网,看每个渔网里有没有鱼)
RCNN缺点:由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。
Fast RCNN解决:共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征。

![]()
Fast RCNN相对于RCNN的提速原因就在于:不像RCNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。
Fast RCNN算法分为5个步骤
-
在图像中确定约1000-2000个候选框 (使用选择性搜索)
-
对整张图片输进CNN,得到feature map
-
找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
-
对候选框中提取出的特征,使用分类器判别是否属于一个特定类
-
对于属于某一特征的候选框,用回归器进一步调整其位置
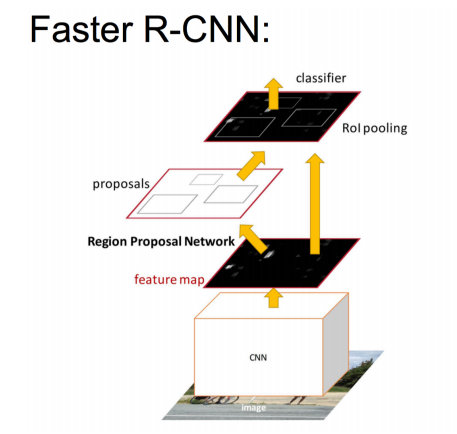
![]() Faster RCNN
Faster RCNN
选择性搜索算法生成候选区域太慢了,有什么方法可以改善吗?
(AI大视觉:可以用神经网络算法学习哪些地方可能有鱼(候选区域),然后向这些地方一起撒很多渔网,看每个渔网里有没有鱼)
Faster RCNN在结构上将特征抽取、region proposal提取, bbox regression,分类都整合到了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。

![]()
加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。
做这样的任务的神经网络叫做Region Proposal Network(RPN)。
具体做法:
• 将RPN放在最后一个卷积层的后面
• RPN直接训练得到候选区域
![]()
Faster RCNN算法分为4个步骤
-
对整张图片输进CNN,得到feature map
-
将feature map输入到RPN,得到候选框的特征信息
-
对候选框中提取出的特征,使用分类器判别是否属于一个特定类
-
对于属于某一特征的候选框,用回归器进一步调整其位置
![]() 总结
总结

![]()
![]()
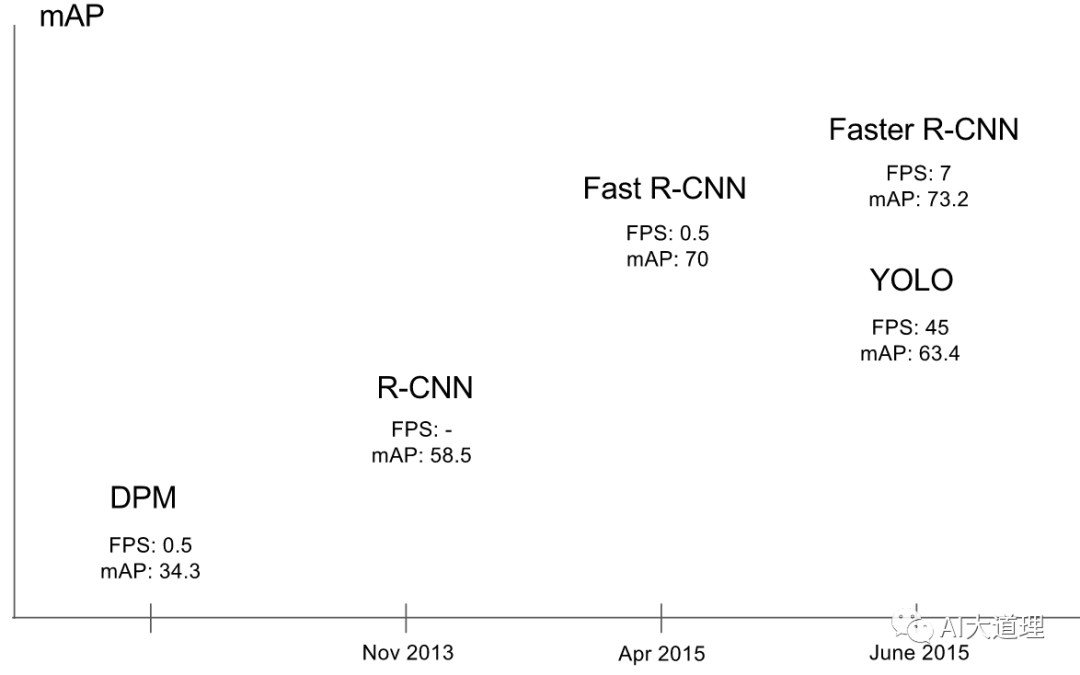
RCNN系列属于候选区域/窗 + 深度学习分类的两步走方法。
即使是该系列最好的模型还是无法达到实时检测目标的效果,获取region proposal, 再对每个proposal分类计算量还是较大。
灵魂的拷问:两步走无法再进一步了,那能否一步到位?
YOLO,you only look once,就是一步到位的算法。
它去掉了获得候选区域的这一步。
那它是怎么去掉的呢?去掉后性能又会有怎么样的影响呢?

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————