哈希算法
如果我们用(用户id)%服务器机器数这样的方法来分配服务器。
虽然我们能保证数据的均匀性,但稳定性差,比如我们增加一个节点,会导致大量的映射失效。
1%3 == 1%4
2%3 == 2%4
3%3 != 3%4
4%3 != 4%4

这就难搞了,3之后的全乱了,直接体验了一把缓存雪崩。
所以哈希算法只适用于节点数比较固定的情况,并不能很好的应对节点的变化。
一致性哈希算法
这个时候一致性算法就来了,你看这个哈希环它是又大又圆,用它来降低映射关系大量失效的可能性刚刚好。
任何一条线段都有无数个点,这个大家应该没什么意见吧?所以理论上这个哈希圈是能存储无限多的东西的。
那数据该如何存储呢?一致性哈希算法也是取模,一般来说落在圆环上的点是顺时针存储在离他最近的那个服务器。
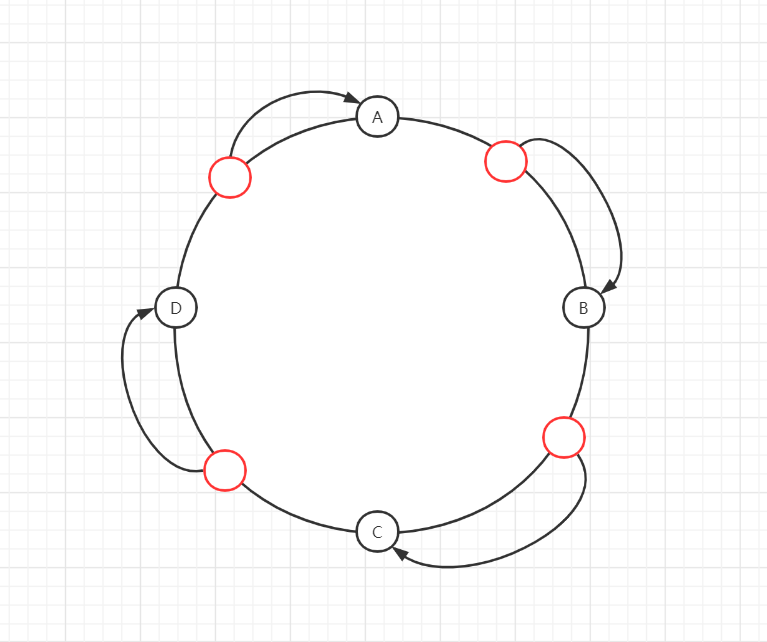
如果此时我们增加一台服务器E在CD之间,那么受影响的只有D。
也就是说当服务器数量发生改变时,受影响的只有顺时针相邻的后续节点,后端不至于短时间内承担大量的压力,不会发生大规模数据迁移。这也是一致性哈希算法的优点。
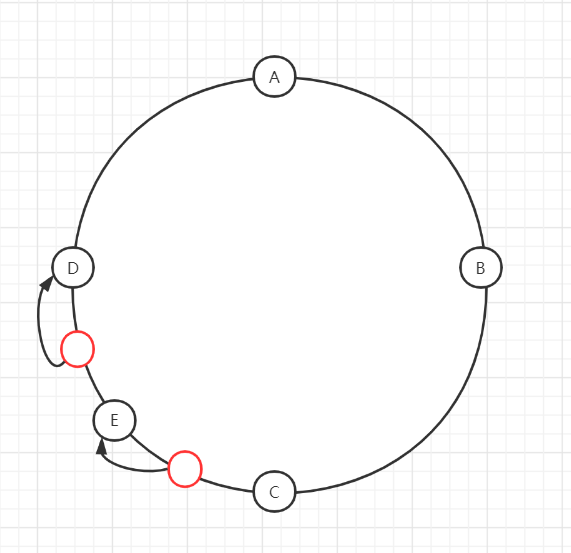
但ABCD一定会在环上均匀分布吗?完全有可能四台服务器的IP hash取模之后出现下图的情况,出现hash环的偏斜。
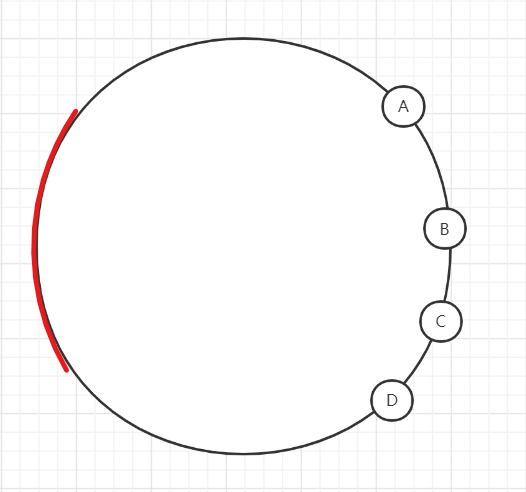
如果运气特别好,请求全集中在左边的圆弧上,A就直接炸了。
设置存储上限
最简单的办法就是根据当前负载情况对所有节点限制一个最大负载,防止某个节点承担大部分的压力。
当要存储数据时,先判断是否已经达到上限。如果已经满了,那么接着顺时针寻找下一个节点。
不过如果各台服务器性能不一的话,这样做也不是太好。
增加虚拟结点
解决办法我相信你也想到了,只是没敢说。如果服务器够多,不就不存在分布不均的问题了吗?
没错,就是这样,但问题是从哪来找那么多服务器呢?
根据你想要要加倍的服务器倍数,搞虚拟节点即可。节点越多,映射到环上就越均匀。比如说你可以由A映射出A^1-A^(2^23),BCD也是如此。这4*2^23个服务器映射到哈希环上,环都直接长成小煤球了。绝对的均匀,偏斜问题得到了极大的解决。
也就是将哈希取模的N进行固定,但多一步虚拟节点映射到物理机上的步骤。这样就可以确保相同的key必然是相同的位置,从而避免之前牵一发而动全身的问题。

并且我们还可以根据各台服务器的性能来设置不同数量的虚拟节点。
引入虚拟节点的另外一个好处就是当某台机器扛不住崩了,可以防止环上的下个机器要扛2倍的流量。
因为当某个节点被移除时,该节点对应的所有虚拟节点也会消失。而这些虚拟节点顺时针对应的下一个节点对应的可能是不同的物理机,等于大家均摊了节点变化的压力。
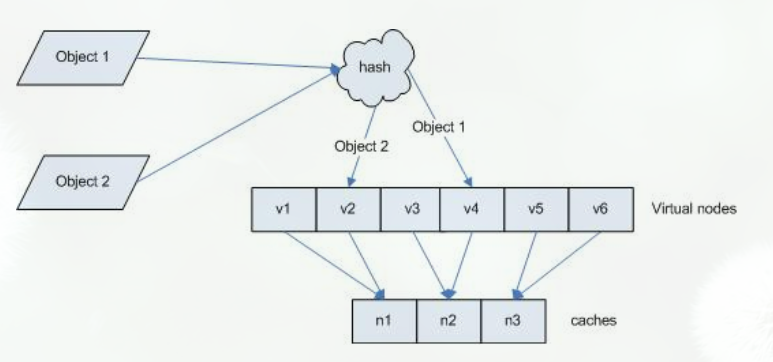
不过虚拟节点的引入在提高了稳定性的同时,也增加了维护和管理的复杂度,也算是有利有弊吧。