vmstat监控工具
一、前言
很显然从名字中我们就可以知道vmstat是一个查看虚拟内存(Virtual Memory)使用状况的工具,但是怎样通过vmstat来发现系统中的瓶颈呢?在回答这个问题前,还是让我们回顾一下Linux中关于虚拟内存相关内容。
二、虚拟内存原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
三、vmstat详解
1.用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
2.使用说明
例子1:每3秒输出一条结果
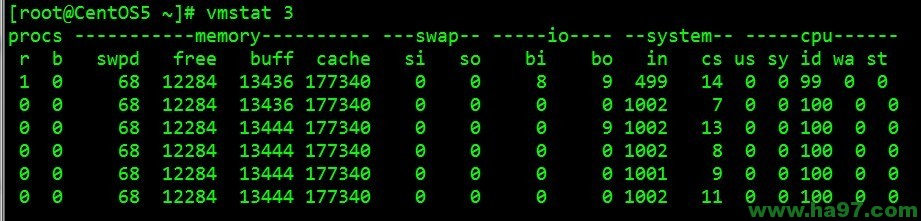
字段说明:
Procs(进程):
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
注意:如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
free: 空闲物理内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
注意:如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap:
si: 每秒从交换区写到内存的大小,由磁盘调入内存
so: 每秒写入交换区的内存大小,由内存调入磁盘
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO:(现在的Linux版本块的大小为1kb)
bi: 每秒读取的块数
bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示):
us: 用户进程执行时间百分比(user time)
注意: us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 内核系统进程执行时间百分比(system time)
注意:sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa: IO等待时间百分比
注意:wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id: 空闲时间百分比
例子2:显示活跃和非活跃内存
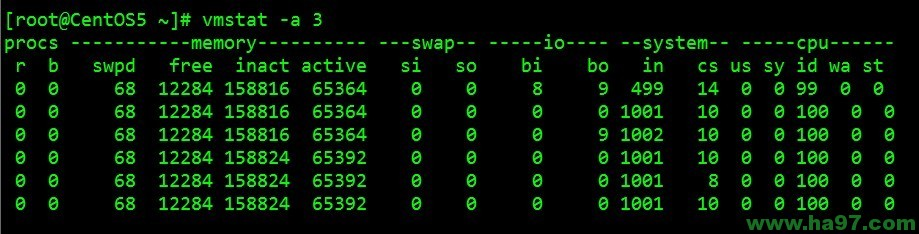
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
字段说明:
Memory(内存):
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
总结:
目前说来,对于服务器监控有用处的度量主要有:
r(运行队列)
pi(页导入)
us(用户CPU)
sy(系统CPU)
id(空闲)
注意:如果r经常大于4 ,且id经常少于40,表示cpu的负荷很重。如果bi,bo 长期不等于0,表示内存不足。
通过VMSTAT识别CPU瓶颈:
r(运行队列)展示了正在执行和等待CPU资源的任务个数。当这个值超过了CPU数目,就会出现CPU瓶颈了。
Linux下查看CPU核心数的命令:
cat /proc/cpuinfo|grep processor|wc -l
当r值超过了CPU个数,就会出现CPU瓶颈,解决办法大体几种:
- 最简单的就是增加CPU个数和核数
- 通过调整任务执行时间,如大任务放到系统不繁忙的情况下进行执行,进尔平衡系统任务
- 调整已有任务的优先级
通过vmstat识别CPU满负荷:
首先需要声明一点的是,vmstat中CPU的度量是百分比的。当us+sy的值接近100的时候,表示CPU正在接近满负荷工作。但要注意的是,CPU 满负荷工作并不能说明什么,Linux总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化。唯一能够确定CPU瓶颈的还是r(运行队列)的值。
通过vmstat识别RAM瓶颈:
数据库服务器都只有有限的RAM,出现内存争用现象是Oracle的常见问题。
首先用free查看RAM的数量:
[oracle@oracle-db02 ~]$ free
total used free shared buffers cached
Mem: 2074924 2071112 3812 0 40616 1598656
-/+ buffers/cache: 431840 1643084
Swap: 3068404 195804 2872600
当内存的需求大于RAM的数量,服务器启动了虚拟内存机制,通过虚拟内存,可以将RAM段移到SWAP DISK的特殊磁盘段上,这样会 出现虚拟内存的页导出和页导入现象,页导出并不能说明RAM瓶颈,虚拟内存系统经常会对内存段进行页导出,但页导入操作就表明了服务器需要更多的内存了, 页导入需要从SWAP DISK上将内存段复制回RAM,导致服务器速度变慢。
解决的办法有几种:
- 最简单的,加大RAM;
- 改小SGA,使得对RAM需求减少;
- 减少RAM的需求。(如:减少PGA)
线段树模板
Trie模板 UVALive 3942 Remember the Word
使用swift写sprite Kit的模仿微信打飞机游戏
Graffiti support page
使用代码控制ScrollView的contentSize
资料整理
pd.to_sql()用法
如何将表格的数据导入到mysql
安装启动MySQL8.0,报错:1053