1.引言
许多网站都喜欢让用户点击“喜欢/不喜欢”,“顶/反对”,也正是这种很简单的信息也可以利用起来对用户进行推荐!这里介绍一种基于网络结构的推荐系统!
由于推荐系统深深植根于互联网,用户与用户之间,商品与商品之间,用户与商品之间都存在某种联系,把用户和商品都看作节点,他(它)们之间的联系看作是边,那么就很自然地构建出一个网络图,所以很多研究者利用这个网络图进行个性化推荐,取得了不错的效果!
2.二部图
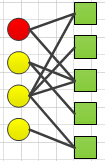
上面就是一个二部图:分为连个部分,圆圈代表的节点为一部分,方块代表的节点为另一部分,二部图的特点:边只存在与不同类之间,同一部分之间的节点之间不存在边连接,正如上图所示,圆圈与圆圈之间没有边,方块与方块之间也没有边,边只存在于圆圈与方块之间.
3.概率传播(probability spreading,ProbS)
本文要实现的基于二部图的推荐系统利用了一种叫做概率传播的机制,这里做一个介绍:
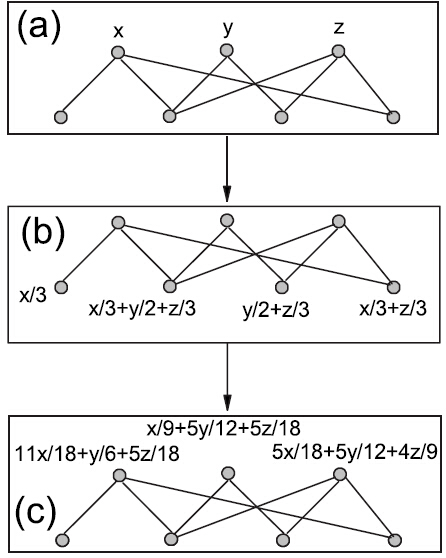
在(a)中,对上面的一部分节点分配初始资源x, y, z, 在(b)中资源以等概率传播的方式,从上面的节点传递给下面的节点,所谓等概率传播,就是每一节点的资源平均传递给它的每一个与它存在边联系的节点,在(c)中资源又以等概率传播的方式传回到上面的节点,可以看出原来三个节点的资源由x, y, z变为11x/18+y/6+5z/18, x/9+5y/12+5z/18, 5x/18+5y/12+4z/9,这样传播的目的是什么呢?
我们知道在二部图中,同一部分节点之间是没有边连接的,那么同一部分之间节点之间的关系就没法直接找到,通过这种二步传播的方式之后,每一个节点的资源都混合有其他节点的资源,把上面三个节点从左到右分别记为A, B, C,A包含了1/6来自于B节点的资源,还包含了5/18来自于C节点的资源,很显然对于A 节点而言, C节点要比B节点重要一些,所以就利用传播后的这些系数来表示同一部分节点之间的关系权重,我们用x', y', z'来表示第二次传播后的资源,则有:
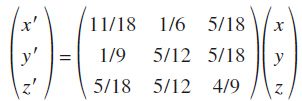
上面的数值矩阵就是节点之间的关系权重矩阵,例如A节点对B节点之间的关系权重为1/6,注意这是一个非对称的:B节点对A节点的关系权重为1/9,怎么理解呢?可以理解为你把一个妹子看作是女神,但是这个妹子心中的Mr Right很可能是另外一个人,这种关系是不对等的. 也正是隐藏的这种不对等关系,正好有利于个性化推荐.
3.利用ProbS产生推荐
还是对未评价过的商品进行预测评分,把评分较高的若干商品推荐给目标用户:
还是以上面的二部图为例,把上面的3个节点看作是商品节点,从左到右分别记作A, B, C,下面的4个节点看作是用户,从左到右分别记作U1, U2, U3, U4, 存在边连接的用户和商品,表示对应的用户喜欢该商品。那么这个二部图用邻接矩阵可以表示为:
| A | B | C | |
| U1 | 1 | 0 | 0 |
| U2 | 1 | 1 | 1 |
| U3 | 0 | 1 | 1 |
| U4 | 1 | 0 | 1 |
现在我们想预测U3对A商品的喜欢程度会如何,已知U3喜欢商品B和C,写出上面推导出的关系权重矩阵:
由此可以知道A商品与B, C商品的关系权重分别为1/6, 5/18,那么预测喜欢程度:
1*1/6 + 1*5/18 = 4/9,
如果有更多未知喜欢程度的商品,都是以这种方式:根据用户已经喜欢的商品与未知喜欢程度商品之间的关系权重来预测这个用户对要预测商品的喜欢程度的评分,根据评分高低,优先向用户推荐高分商品!
关于更多详细的介绍请参考:Bipartite_network_projection_and_personal_recommendation.pdf
4.C++实现
由于程序没有优化,在较大数据上运行较慢,所以这里自己随便造了一个数据集,对其为0的地方进行评分预测,但是由于没有测试集,所以就没有测命中率,有兴趣的读者可以自己优化一下程序,然后在movielens.rar数据上运行并测试命中率,这里主要注重原理,如果有读者根据此原理编出更高效得代码欢迎与我交流,多谢!
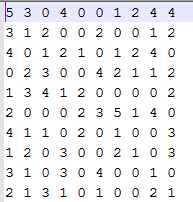
由于该数据集是1-5的评分数据,在程序读取的时候将其处理为喜欢/不喜欢(1/0)的数据集:评分大于等于3的视为喜欢,置为1,否则置为0.
1 #include <iostream>
2 #include <fstream>
3 #include <vector>
4 #include <string>
5 #include <vector>
6 #include <algorithm>
7 #include <iomanip>
8 using namespace std;
9
10 //从TXT中读入数据到矩阵(二维数组)
11 template <typename T>
12 vector<vector<T> > txtRead(string FilePath,int row,int col)
13 {
14 ifstream input(FilePath);
15 if (!input.is_open())
16 {
17 cerr << "File is not existing, check the path:
" << FilePath << endl;
18 exit(1);
19 }
20 vector<vector<T> > data(row, vector<T>(col,0));
21 for (int i = 0; i < row; ++i)
22 {
23 for (int j = 0; j < col; ++j)
24 {
25 //因为这里针对的情况是用户只给出对items的喜欢与不喜欢的情况,而movielens
26 //是一个1-5的评分数据,所以把分数达到3的看作是喜欢,标记为1,小于3的视为
27 // 不喜欢,置为0
28 input >> data[i][j];
29 if (data[i][j] >= 3)
30 data[i][j] = 1;
31 else
32 data[i][j] = 0;
33 }
34 }
35 return data;
36 }
37
38 //把矩阵中的数据写入TXT文件
39 template<typename T>
40 void txtWrite(vector<vector<T> > Matrix, string dest)
41 {
42 ofstream output(dest);
43 vector<vector<T> >::size_type row = Matrix.size();
44 vector<T>::size_type col = Matrix[0].size();
45 for (vector<vector<T> >::size_type i = 0; i < row; ++i)
46 {
47 for (vector<T>::size_type j = 0; j < col; ++j)
48 {
49
50 output << setprecision(3)<< Matrix[i][j] << " ";
51 }
52 output << endl;
53 }
54 }
55
56 // 求两个向量的内积
57 double InnerProduct(std::vector<double> A, std::vector<double> B)
58 {
59 double res = 0;
60 for(std::vector<double>::size_type i = 0; i < A.size(); ++i)
61 {
62 res += A[i] * B[i];
63 }
64 return res;
65 }
66
67 //矩阵转置操作
68 template<typename T>//
69 vector<vector<T> > Transpose(vector<vector<T> > Matrix)
70 {
71 unsigned row = Matrix.size();
72 unsigned col = Matrix[0].size();
73 vector<vector<T> > Trans(col,vector<T>(row,0));
74 for (unsigned i = 0; i < col; ++i)
75 {
76 for (unsigned j = 0; j < row; ++j)
77 {
78 Trans[i][j] = Matrix[j][i];
79 }
80 }
81 return Trans;
82 }
83
84 //求一个向量中所有元素的和
85 template<typename T>
86 T SumVector(vector<T> vec)
87 {
88 T res = 0;
89
90 for (vector<T>::size_type i = 0; i < vec.size(); ++i)
91 res += vec[i];
92 return res;
93 }
94
95 //对一个向量中的元素进行降序排列,返回重排后的元素在原来
96 //向量中的索引
97 bool IsBigger(double a, double b)
98 {
99 return a >= b;
100 }
101 vector<unsigned> DescendVector(vector<double> vec)
102 {
103 vector<double> tmpVec = vec;
104 sort(tmpVec.begin(), tmpVec.end(), IsBigger);
105 vector<unsigned> idx;
106 for (vector<double>::size_type i = 0; i < tmpVec.size(); ++i)
107 {
108 for (vector<double>::size_type j = 0; j < vec.size(); ++j)
109 {
110 if (tmpVec[i] == vec[j])
111 idx.push_back(j);
112 }
113 }
114 return idx;
115 }
116
117
118 //基于概率传播(ProbS)的二部图的推荐函数,data是训练数据
119 vector<vector<double> > ProbS(vector<vector<double> > data)
120 {
121 auto row = data.size();
122 auto col = data[0].size();
123 vector<vector<double> > transData = Transpose(data);
124
125 //第一步利用概率传播机制计算权重矩阵
126 vector<vector<double> > weights(col, vector<double>(col, 0));
127 for (vector<double>::size_type i = 0; i < col; ++i)
128 {
129 for (vector<double>::size_type j = 0; j < col; ++j)
130 {
131 double degree = SumVector<double>(transData[j]);
132 double sum = 0;
133 for (vector<double>::size_type k = 0; k < row; ++k)
134 {
135 sum += transData[i][k] * transData[j][k] / SumVector<double>(data[k]);
136 }
137 if (degree)
138 weights[i][j] = sum / degree;
139 }
140 }
141
142 //第二步利用权重矩阵和训练数据集针对每个用户对每一个item评分
143 vector<vector<double> > scores(row, vector<double>(col, 0));
144 for (vector<double>::size_type i = 0; i < row; ++i)
145 {
146 for (vector<double>::size_type j = 0; j < col; ++j)
147 {
148 //等于0的地方代表user i 还木有评价过item j,需要预测
149 if (0 == data[i][j])
150 scores[i][j] = InnerProduct(weights[j],data[i]);
151 }
152 }
153 return scores;
154 }
155
156 //计算推荐结果的命中率:推荐的items中用户确实喜欢的items数量/推荐的items数量
157 //用户确实喜欢的items是由测试集给出,length表示推荐列表最长为多少,这里将测出
158 //推荐列表长度由1已知增加到length过程中,推荐命中率的变化
159 vector<vector<double> > ComputeHitRate(vector<vector<double> > scores, vector<vector<double> > test,
160 unsigned length)
161 {
162 auto usersNum = test.size();
163 auto itemsNum = test[0].size();
164
165 vector<vector<unsigned> > sortedIndex;
166 //因为只是对测试集中的用户和items进行测试,于是选取与测试集大小一样的预测数据
167 vector<vector<double> > selectedScores(usersNum, vector<double>(itemsNum,0));
168 vector<double> line;
169 for (unsigned i = 0; i < usersNum; ++i)
170 {
171 for (unsigned j = 0; j < itemsNum; ++j)
172 {
173 line.push_back(scores[i][j]);
174 }
175 sortedIndex.push_back(DescendVector(line));
176 line.clear();
177 }
178 //hitRate的第一列存储推荐列表的长度,第二列存储对应的命中率
179 vector<vector<double> > hitRate(length);
180 for (unsigned k = 1; k <= length; ++k)
181 {
182 hitRate[k-1].push_back(k);
183 double Counter = 0;
184 for (unsigned i = 0; i < usersNum; ++i)
185 {
186 for (unsigned j = 0; j < k; ++j)
187 {
188 unsigned itemIndex = sortedIndex[i][j];
189 if (test[i][itemIndex])
190 ++Counter;
191 }
192 }
193 hitRate[k-1].push_back(Counter / (k * usersNum));
194 }
195 return hitRate;
196 }
197 int main()
198 {
199 string FilePath1("data.txt");
200 //string FilePath2("E:\Matlab code\recommendation system\data\movielens\test.txt");
201
202 int row = 10;
203 int col = 10;
204 cout << "数据读取中..." << endl;
205 vector<vector<double> > train = txtRead<double>(FilePath1, row, col);
206 //vector<vector<double> > test = txtRead<double>(FilePath2, 462, 1591);
207
208 cout << "利用二部图网络进行评分预测..." << endl;
209 vector<vector<double> > predictScores = ProbS(train);
210 txtWrite(predictScores, "predictScores.txt");
211 /*
212 cout << "计算命中率..." << endl;
213 vector<vector<double> > hitRate = ComputeHitRate(predictScores, test, 1591);
214
215 txtWrite(hitRate, "hitRate.txt");
216 cout << "命中率结果保存完毕!" << endl;
217 */
218 return 0;
219 }
5.运行
预测结果:
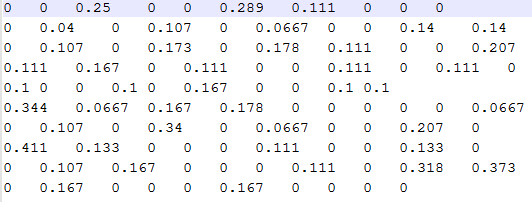
说明:预测为0的地方是在训练集中已经标记为1的地方,即明确了用户喜欢对应的商品,所以就没有必要对其进行预测,由于初始化预测评分的时候,全部初始化为0,所以没有必要预测的的元素为0.用户已经喜欢的是商品就没有必要再推荐给他(她)了,为了增加销售额,必须向用户尽可能推荐他(她)曾经不太注意的新商品,有了这些评分,系统就可以按照评分高低对用户推荐相应的商品了!比如上面的预测结果,对于第一个用户就要优先推荐第6个商品,其次推荐第3个商品,以此类推。