#银行家代码:
import pandas as pd import numpy as np #导入划分数据集函数 from sklearn.model_selection import train_test_split #读取数据 datafile = r'F:\python\Python Scripts\data\bankloan.xls'#文件路径 data = pd.read_excel(datafile) x = data.iloc[:,:8] y = data.iloc[:,8] #划分数据集 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100) #导入模型和函数 from keras.models import Sequential from keras.layers import Dense,Dropout #导入指标 from keras.metrics import BinaryAccuracy #导入时间库计时 import time start_time = time.time() #-------------------------------------------------------# model = Sequential() model.add(Dense(input_dim=8,units=800,activation='relu'))#激活函数relu model.add(Dropout(0.5))#防止过拟合的掉落函数 model.add(Dense(input_dim=800,units=400,activation='relu')) model.add(Dropout(0.5)) model.add(Dense(input_dim=400,units=1,activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam',metrics=[BinaryAccuracy()]) model.fit(x_train,y_train,epochs=100,batch_size=128) loss,binary_accuracy = model.evaluate(x,y,batch_size=128) #--------------------------------------------------------# end_time = time.time() run_time = end_time-start_time#运行时间 print('模型运行时间:{}'.format(run_time)) print('模型损失值:{}'.format(loss)) print('模型精度:{}'.format(binary_accuracy)) yp = model.predict(x).reshape(len(y)) yp = np.around(yp,0).astype(int) #转换为整型 from cm_plot import * # 导入自行编写的混淆矩阵可视化函数 cm_plot(y,yp).show() # 显示混淆矩阵可视化结果
cm_plot.py函数
def cm_plot(y, yp): from sklearn.metrics import confusion_matrix #导入混淆矩阵函数 cm = confusion_matrix(y, yp) #混淆矩阵 import matplotlib.pyplot as plt #导入作图库 plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 plt.colorbar() #颜色标签 for x in range(len(cm)): #数据标签 for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐标轴标签 plt.xlabel('Predicted label') #坐标轴标签 return plt
训练结果:
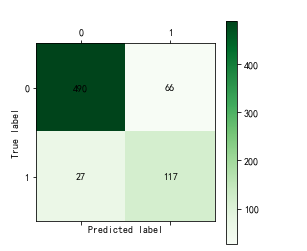

决策树:
import pandas as pd # 参数初始化 filename = r'F:/python/Python Scripts/data/bankloan.xls' data = pd.read_excel(filename) # 导入数据 # 数据是类别标签,要将它转换为数据 # 用1来表示“好”“是”“高”这三个属性,用-1来表示“坏”“否”“低” x = data.iloc[:,:8].astype(int) y = data.iloc[:,8].astype(int) from sklearn.tree import DecisionTreeClassifier as DTC dtc = DTC(criterion='entropy') # 建立决策树模型,基于信息熵 dtc.fit(x, y) # 训练模型 # 导入相关函数,可视化决策树。 # 导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。 from sklearn.tree import export_graphviz x = pd.DataFrame(x) """ string1 = ''' edge [fontname="NSimSun"]; node [ fontname="NSimSun" size="15,15"]; { ''' string2 = '}' """ with open("F:/python/Python Scripts/data/tree.dot", 'w') as f: export_graphviz(dtc, feature_names = x.columns, out_file = f) f.close() from IPython.display import Image from sklearn import tree import pydotplus dot_data = tree.export_graphviz(dtc, out_file=None, #regr_1 是对应分类器 feature_names=data.columns[:8], #对应特征的名字 class_names=data.columns[8], #对应类别的名字 filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data) graph.write_png('F:/python/Python Scripts/data/example.png') #保存图像 Image(graph.create_png())
结果:
混淆矩阵:
