K_means算法的具体过程
1、从数据集{X} 中任意选取k个赋给初始的聚类中心c1, c2, …, ck;
2、对数据集中的每个样本点xi,计算其与各个聚类中心cj的欧氏距离并获取其类别标号:
![]()
3、按下式重新计算k个聚类中心;
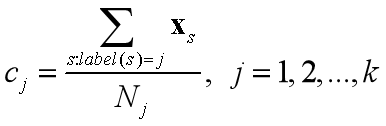
4、重复步骤2和步骤3,直到达到最大迭代次数、聚类目标函数达到最优值或者两次迭代得到的目标函数变化小于给定的较小值为止
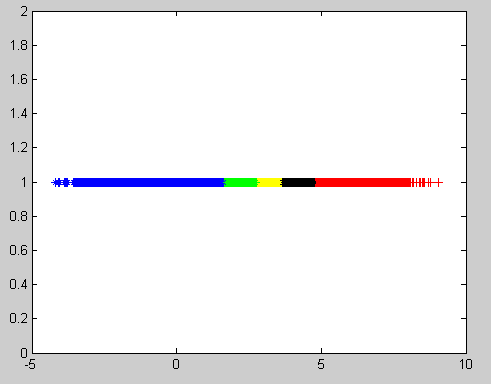
将令k=5聚类的结果如下


%行5000,列22的数据以矩阵形式保存 M=dlmread('waveform.txt',','); [m,n]=size(M); %随机的选取矩阵中的k个元素作为聚类中心 k=5; c=zeros(1,k); for i=1:k c(1,i)=M(round(rand()*5000)+1,round(rand()*22)+1); end %获取每个样本到聚类中心的距离 label_u=zeros(m,n); maxgn=60; label=zeros(m,n); mindis=20; iter=1; while(iter<maxgn) for i=1:m for j=1:n for t=1:k dis=(M(i,j)-c(1,t))^2; if(dis<mindis || label(i,j)==0) label(i,j)=t; mindis=dis; label_u(i,j)=t; end end end end for t=1:k sum=0; new_u=0; for i=1:m for j=1:n if(label_u(i,j)==t) sum=sum+1; new_u=new_u+M(i,j); end end end c(1,t)=new_u/(sum+eps); end iter=iter+1; end for i=1:m for j=1:n if(label_u(i,j)==1) plot(M(i,j),1,'r+') hold on; else if(label_u(i,j)==2) plot(M(i,j),1,'b*') hold on; else if(label_u(i,j)==3) plot(M(i,j),1,'g*') hold on; else if(label_u(i,j)==4) plot(M(i,j),1,'y*') hold on; else if(label_u(i,j)==5) plot(M(i,j),1,'k*') hold on; end end end end end end end