本文内容:
1、 搜索引擎的发展史
2、 Lucene入门
3、 Lucene的API详解
4、 索引调优
5、 Lucene搜索结果排名规则
1 搜索引擎的发展史
1.1 搜索引擎的发展史
萌芽:Archie、Gopher
起步:Robot(网络机器人)和spider(网络爬虫)
1、 Robot:网络机器人,自动在网络中运行,完成特定任务的程序,如刷票器、抢票软件等。
2、 spider:网络爬虫,是一中特殊的机器人,抓取(下载)并分析网络资源,包括网页里面的超链接、图片、数据库、音频、视频等资源信息。
发展:excite、galaxy、yahoo
繁荣:infoseek、altavista、Google、百度
1.2 搜索引擎的原理
1.2.1 信息检索过程
1、 构建文本库
2、 建立索引
3、 进行搜索
4、 对结果进行排序
1.2.2 原理
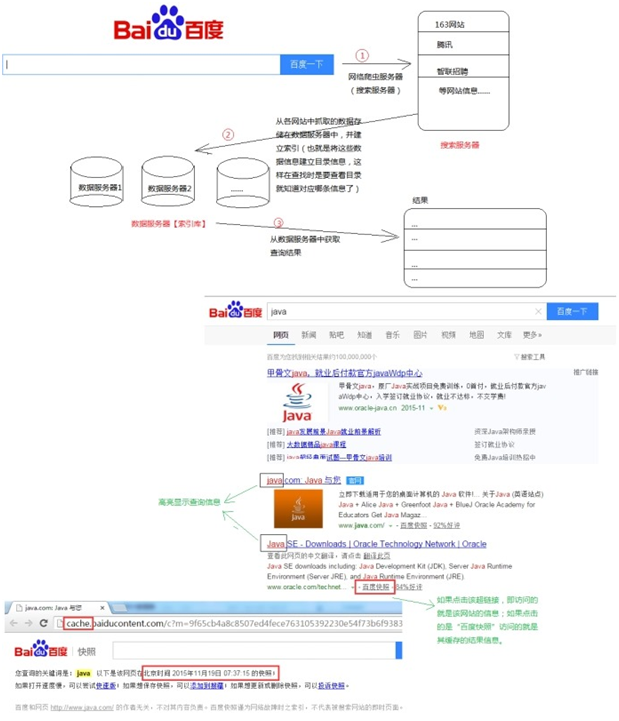
搜索引擎的工作原理,通过用户输入的信息,通过网络爬虫即搜索服务器,将各与之相关的网站信息抓取并存放到自己的数据服务器中,在存入数据服务器的过程中将这些数据信息需要创建索引库,用户查询的结果信息都是来源与索引库信息,如果点击该结果超链接则访问的是该网站信息,如果选择“快照”则访问的是缓存信息。
那为什么要建立索引库呢?
建立索引库的过程就是将该结果建立索引,通俗一点的理解就是建立目录的过程。
1.3 搜索引擎的使用场景
1.3.1 使用场景
1、 电商网站的搜索,如京东、天猫等
2、 论坛、BBS等站内搜索
3、 垂直领域的搜索,垂直领域:即专门做一件事。如818工作网、拉勾网等都属于垂直领域。
4、 Windows的资源管理器中的搜索
5、 Word中的Ctrl+F、eclipse中的Ctrl+shift+T等单机软件的搜索
这些都是属于信息检索的范围。
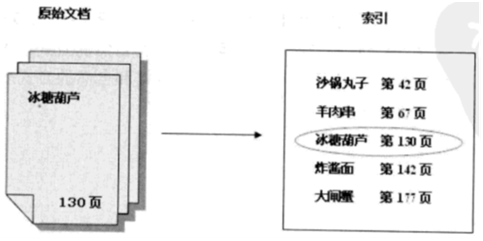
1.3.2 倒排索引
倒排索引,就是提取信息并建立索引(目录)的过程中,搜索时,根据关键字找到资源的具体位置。如:
2 Lucene入门
2.1 什么是Lucene
2.1.1 概念
Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能。
2.1.2 Lucene与搜索引擎的区别
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。全文检索系统是一个可以运行的系统,包括建立索引、处理查询返回结果集、增加索引、优化索引结构等功能。例如:百度搜索、eclipse帮助搜索、淘宝网商品搜索。
搜索引擎是全文检索技术最主要的一个应用,例如百度。
搜索引擎起源于传统的信息全文检索理论,即计算机程序通过扫描每一篇文章中的每一个词,建立以词为单位的倒排文件,检索程序根据检索词在每一篇文章中出现的频率和每一个检索词在一篇文章中出现的概率,对包含这些检索词的文章进行排序,最后输出排序的结果。全文检索技术是搜索引擎的核心支撑技术。
Lucene和搜索引擎不同,Lucene是一套用java或其它语言写的全文检索的工具包,为应用程序提供了很多个api接口去调用,可以简单理解为是一套实现全文检索的类库,搜索引擎是一个全文检索系统,它是一个单独运行的软件系统。
Lucene开源免费,它既不是搜索引擎,也不是可直接运行的软件,它只是一套API,可以根据该API开发自己的搜索系统。
2.2 掌握什么
这里我们使用的是Lucene4.x版本,我们需要知道是如何创建索引的,并根据输入的信息将我们的结果查询出来这样的一套流程。
2.3 企业中如何使用Lucene
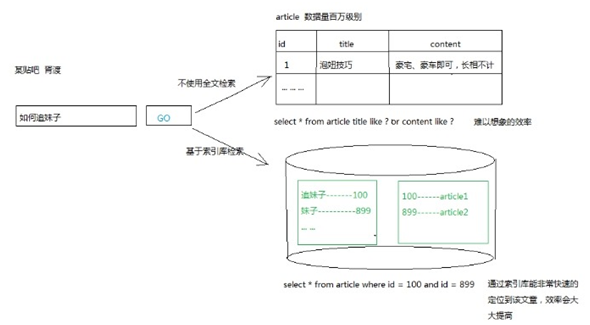
例如BBS贴吧的站内搜索,它是如何完成的呢?难道是查询数据库的信息并将结果返回的么?
2.4 入门程序
2.4.1 下载Lucene
官网,http://lucene.apache.org/,我们通过官网下载我们需要的jar包。目前最新的版本5.3.1,那这里我们使用的是4.10.2这个版本。
2.4.2 创建索引
2.4.2.1 导入jar包
解压我们的zip压缩文件,导入我们需要的jar包。这里我们需要分词器的包、Lucene的核心包、高亮显示的包和查询需要的包。
2.4.2.2 创建索引
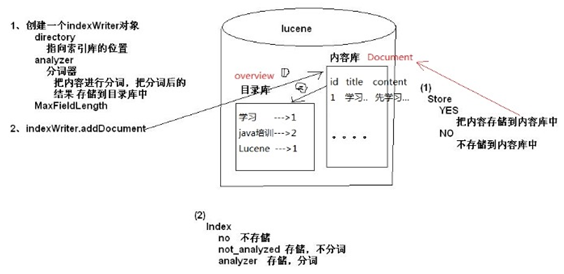
在发帖并提交时,我们创建帖子的索引库。
创建索引库的过程:将文本内容-à转换成Document对象(该对象中有很多Field,可以把该Document对象当做是一个帖子),然后在通过IndexWriter创建我们的索引。
2.4.2.2.1 代码
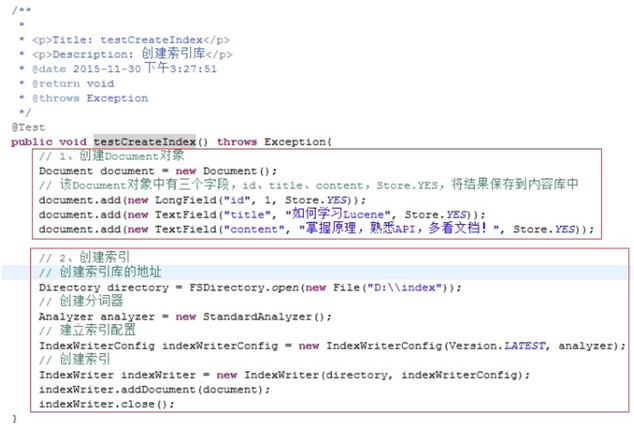
代码里提到了分词器的概念,这个再将API的时候在细说
2.4.2.2.2 索引库
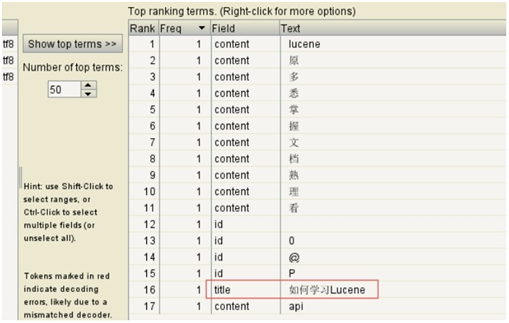
2.4.2.3 查看索引库
我们通过lukeall工具查看创建的索引库中的内容。我们通过java –jar xxx.jar的方式运行我们的lukeall工具,并通过该工具查看我们创建的索引库的内部结构。
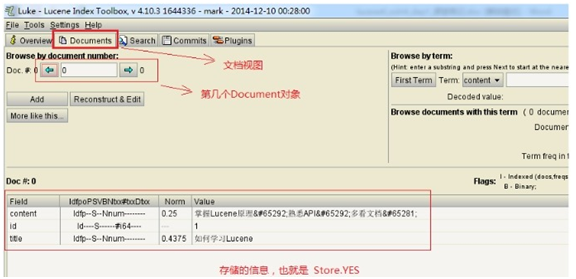
2.4.2.3.1 overview
目录库,分词后的词条信息。
2.4.2.3.2 document
也就是内容库。存放数据的。
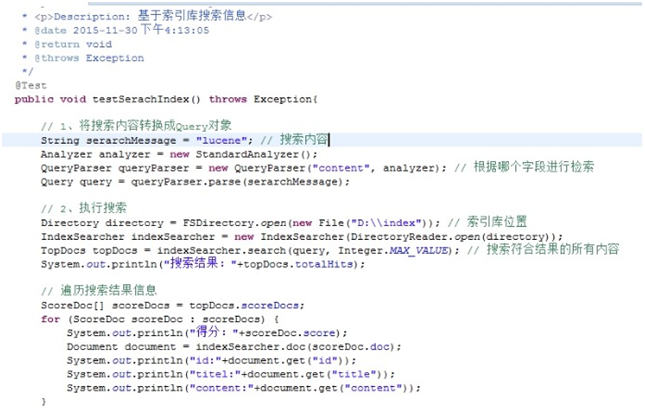
2.4.3 基于索引搜索
2.4.3.1 检索过程

2.4.3.2 代码
3 Lucene API详解
3.1 创建索引API

3.1.1 Directory
l Directory,指的是文件磁盘的索引路径
l RAMDirectory,指的是内存中的索引路径
3.1.2 Analyzer
3.1.2.1 原理
Analyzer是一个抽象类,在Lucene的lucene-analyzers-common包中提供了很多分析器,比如:org.apache.lucene.analysis.standard.standardAnalyzer标准分词器,它是Lucene的核心分词器,它对分析文本进行分词、大写转成小写、去除停用词、去除标点符号等操作过程。
什么是停用词?停用词是为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。比如语气助词、副词、介词、连接词等,通常自身并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的”、“在”、“是”、“啊”等。
如下是org.apache.lucene.analysis.standard.standardAnalyzer的部分源码:
final StandardTokenizer src = new StandardTokenizer(getVersion(), reader);//创建分词器
src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new StandardFilter(getVersion(), src);//创建标准分词过滤器
tok = new LowerCaseFilter(getVersion(), tok);//在标准分词过滤器的基础上加大小写转换过滤
tok = new StopFilter(getVersion(), tok, stopwords);//在上边过滤器基础上加停用词过滤
3.1.2.2 中文分词器
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。而中文则以字为单位,字又组成词,字和词再组成句子。所以对于英文,我们可以简单以空格判断某个字符串是否为一个单词,比如I love China,love 和 China很容易被程序区分开来;但中文“我爱中国”就不一样了,电脑不知道“中国”是一个词语还是“爱中”是一个词语。把中文的句子切分成有意义的词,就是中文分词,也称切词。我爱中国,分词的结果是:我 爱 中国。
3.1.2.3 Lucene自带分词器
l StandardAnalyzer:
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
l CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上面两个分词器无法满足需求。
l SmartChineseAnalyzer
对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理
3.1.2.4 第三方产品
|
名称 |
最近更新 |
速度 ( 网上情报 ) |
扩展性支持、其它 |
|
mmseg4j |
2013 |
complex 60W 字 /s (1200 KB/s) simple 100W 字 /s (1900 KB/s) |
使用 sougou 词库,也可自定义 (complexsimple MaxWord) |
|
IKAnalyzer |
2012 |
IK2012 160W 字 /s (3000KB/s) |
支持用户词典扩展定义、支持自定义停止词 ( 智能 细粒度 ) |
|
Ansj |
2014 |
BaseAnalysis 300W 字 /s hlAnalysis 40W 字 /s |
支持用户自定义词典,可以分析出词性,有新词发现功能 |
|
paoding |
2008 |
100W 字 /s |
支持不限制个数的用户自定义词库 |
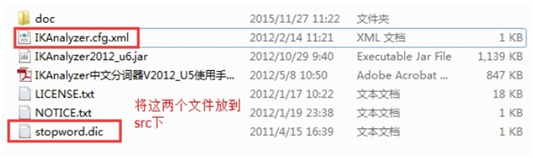
这里我们使用IK分词器。那如何使用IK分词器呢?
1、 解压压缩文件,并将该两个配置文件放入src中。
2、 导入jar包

导入FF_u1的jar包,该版本支持4.x,而u6仅仅支持4.x之前的版本。
3、 使用该分词器的前后对比
standardanalyzer:

IKanalyzer :

3.1.3 IndexableFiled

l LongField,分词,有多个词条
l StringField,建立索引时不分词,将该内容作为一个完整的词条Term
l TextField,建立索引时分词,有多个词条
l Store:YES或NO不影响是否分词;YES,会在Document中存储,NO,不会在Document中存储


3.1.4 IndexWriter
Lucene3.5之后,IndexWriter的初始化有了一个IndexConfig来作为其初始化的参数,当我们在使用IndexWrier的时候一定要注意在最后把writer关闭,否则抛出异常。其实这个异常是因为lucene进入到索引目录中,发现里面就是一个write.lock。而IndexWriter的构造函数在试图获取另外一个IndexWriter已经加锁的索引目录时就会抛出一个LockObtainFailedException。
当IndexWriter在初始化索引的时候会为这个索引加锁,等到初始化完成之后会调用其close()方法关闭IndexWriter,在close()这个方法的内部其实也是调用了unlock()来释放锁,当程序结束后IndexWriter没有正常关闭的时候这个锁也就没有被释放,等待下次对同样的索引文件创建IndexWriter的时候就会抛出该异常。

执行上面代码,就会报如下错误。

编写工具类,在使用完IndexWriter后自动关闭。
通俗一点讲:就是该对象销毁后才释放锁对象,因为都是将信息放入同一个索引库中。如果指定不是同一索引库是没有问题的,但是需要执行commit方法,因为close方法中包含了commit方法。

3.2 基于索引库检索API

检索最重要的就是根据你的Query去搜索信息,因此我们Lucene的API中提供了很多的Query对象,我们根据不同的Query对象独有的特性去检索我们需要的信息。
3.2.1 QueryParser
针对单一字段,解析查询信息并分词进行搜索。

3.2.2 MultiFiledQueryParser
针对多字段,解析查询信息并分词进行搜索。

3.2.3 TermQuery
根据词条搜索,使用该对象不会在去解析查询信息并分词。词条就是索引库的最小单位,不可再继续分词。

3.2.4 WildcardQuery
模糊搜索:*代表0个或多个字符;?代表一个字符

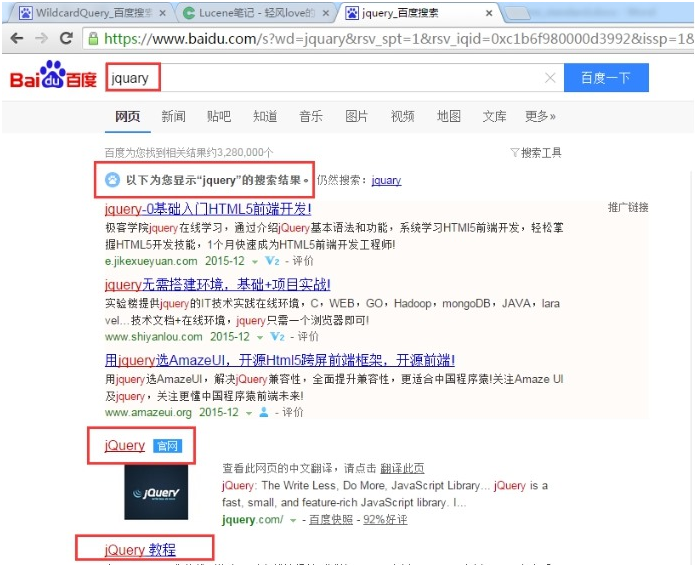
3.2.5 FuzzyQuery
相似度搜索,例如,我们想搜JQuery,但是在输入框输入jquary。
FuzzyQuery的构造方法:
FuzzyQuery(Term term):默认支持模糊字数为2;
FuzzyQuery(Term term, int maxEdits):maxEdits:模糊字数,[0,2]之间,若为0,相当于TermQuery。
FuzzyQuery(Term term, int maxEdits, int prefixLength):prefixLength,指定要有多个前缀字母必须完全匹配。
3.2.6 NumericRangeQuery
数字范围搜索(演示:略),最后两个参数的含义是:minInclusive,是否最小包含,maxInclusive,是否最大包含

3.2.7 MatchAllDocsQuery
查询所有的结果。
3.2.8 小结
使用Query对象的优先顺序
1、 TermQuery,词条搜索
2、 若输入内容太长,可用:QueryParser,将输入内容解析并切词
3、 若输入内容太短,可用:WildcardQuery,模糊查询
4、 若输入内容有误,可用:FuzzyQuery,相似度查询
3.3 BooleanQuery
BooleanQuery,组合查询,通过该Query对象可以将上面各种Query进行任意组合。
构造方法:

add(Query query, BooleanClause.Occur occur):
query,各种其他的query;
occur,该变量的取值有三种,分别为:MUST(必须满足)、MUST_NOT(必须不满足)、SHOULD(可以满足)。
MUST+MUST:两个Query查询对象的交集
MUST+MUST_NOT:两个Query查询对象的补集
SHOULD+SHOULD:两个Query查询对象的并集。
3.4 结论
词条:就是将查询的信息通过指定的各种Query对象的本身特有的属性去匹配词条;
Document:就是将匹配后的结果返回。
4 索引调优
4.1 概念
索引调优:
就是在创建索引时,将我们的创建的索引库的内容和磁盘内容加载到内存中,执行完之后,并将内存中的索引库的内容加载到磁盘上。
RAMDirectory是内存的一个区域,当虚拟机退出后,里面的内容也会随之消失
RAMDirectory的性能要好于FSDirectory, 因此可以结合使用,在虚拟机退出时,将RAM内容转到FSDirectory。
4.2 代码
索引调优代码:

CREATE:会写到索引库并覆盖原索引库
CREATE_OR_APPEND:将内存库信息追加到索引库中。
5 Lucene搜索结果排名规则
5.1 结果得分
5.1.1 Lucene文档的得分算法

df举例:
有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。
5.1.2 改变boost值来改变文档得分
boost,激励因子,默认值是1,可以手动更改。我们可以设置boost值来改变搜索结果排名。而且设置boost值后,该信息保存在Document文档的norm中。

5.1.2.1 在索引库中创建100个索引

查询的结果
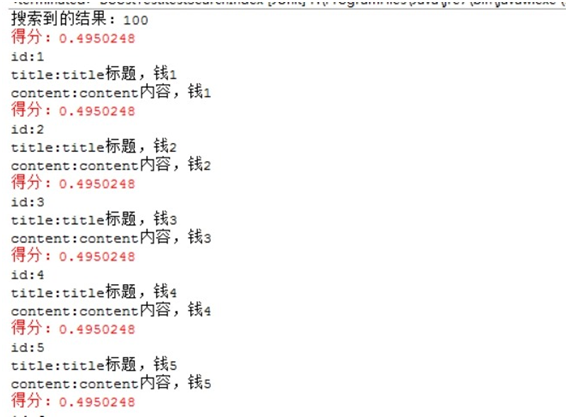
而且所有的Document中的NORM的值都是一样。
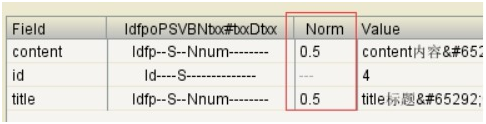
得分一样。那么我想让第88条记录排在第一位怎么办?我们只有设置它的激励因子(boost)值即可
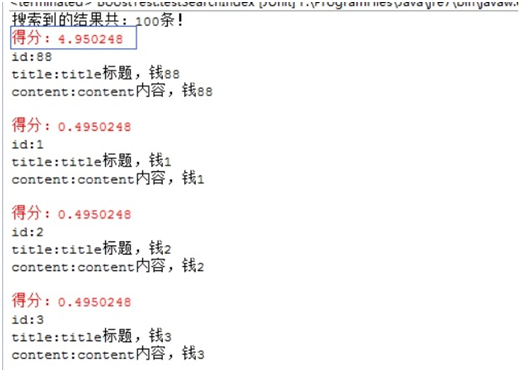
1、 设置得分

2、 结果
3、 NORM值
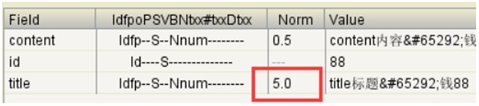
设置boost(激励因子),可以改变得分以及Norm值。
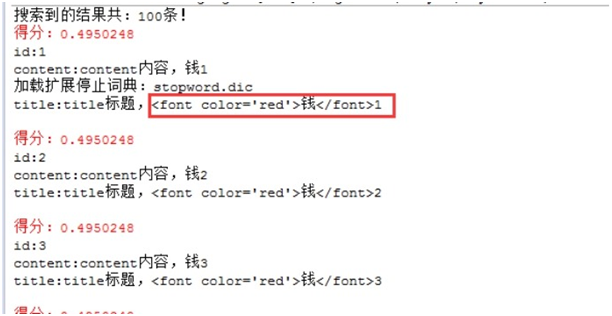
5.2 结果高亮显示
结果高亮显示,也就是将搜索内容进行了高亮显示。例如,百度,查询java

所以说高亮显示就是将搜索的信息结果通过HTML标签进行样式的处理。可以对标题也可以对文本进行高亮显示。
5.2.1 定义高亮器
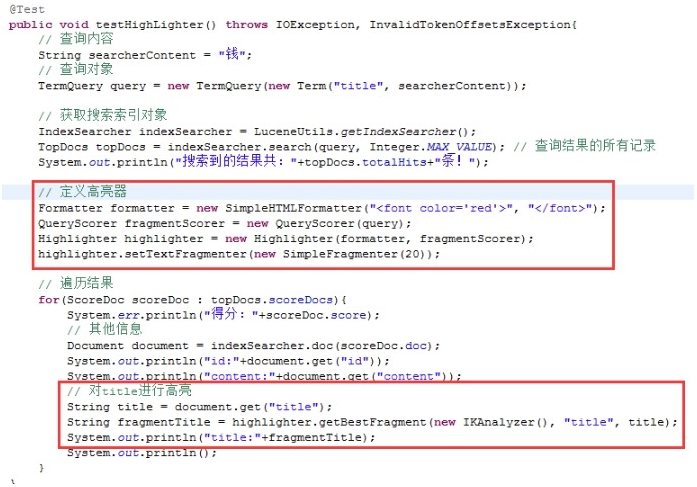
5.2.2 使用高亮
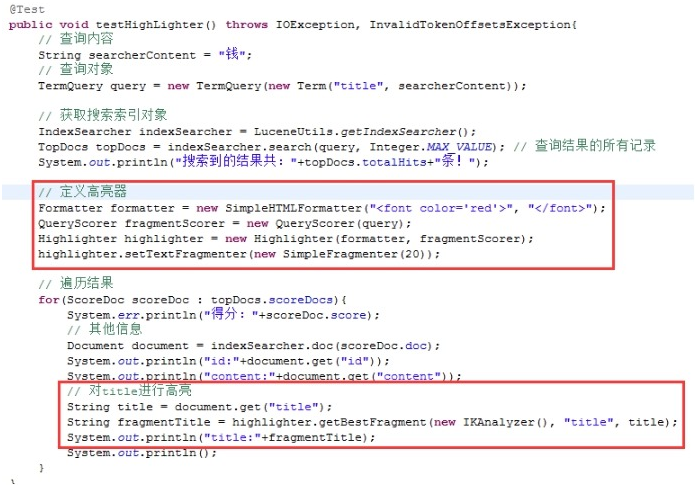
5.2.3 结果显示