在面试过程中,经常会涉及到一些算法问题,下面说介绍一下冒泡排序算法及优化.
冒泡排序分为从大到小和从小到大两种排序方式,唯一区别在于两个数交换的条件不同,
从大到小排序是前面的数比后面的小时交换,而从小到大排序是前面的数比后面的数大的时候交换.
假设有N个数据放在数组nums中,现将数组nums中的N个数据从小到大进行排序
假设使用冒泡排序算法对5个整数{8,3,-2,7,6}进行从小到大的排序
冒泡排序的基本思想:
在a[0] 到a[n-1]的范围内,依次比较两个相邻元素的值,若a[j]>a[j+1] 则交换a[j] 和a[j+1]
否则不作交换, 直至完成最后一次循环比较.
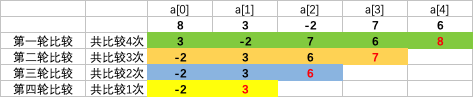
如图可知:数组长度为n, 外层共循环n-1次, 外层循环增加一次 对应的内层循环就减少一次
外层循环控制比较的轮数, 内层循环控制的比较的次数
外层循环: for(int i=0; i<nums.length-1; i++)
内层循环: for(int j=0; j<nums.length-1-i; j++)
交换两个相邻元素的值:
int temp = nums[j];
nums[j] = nums[j+1];
nums[j+1] = temp;
代码实现:
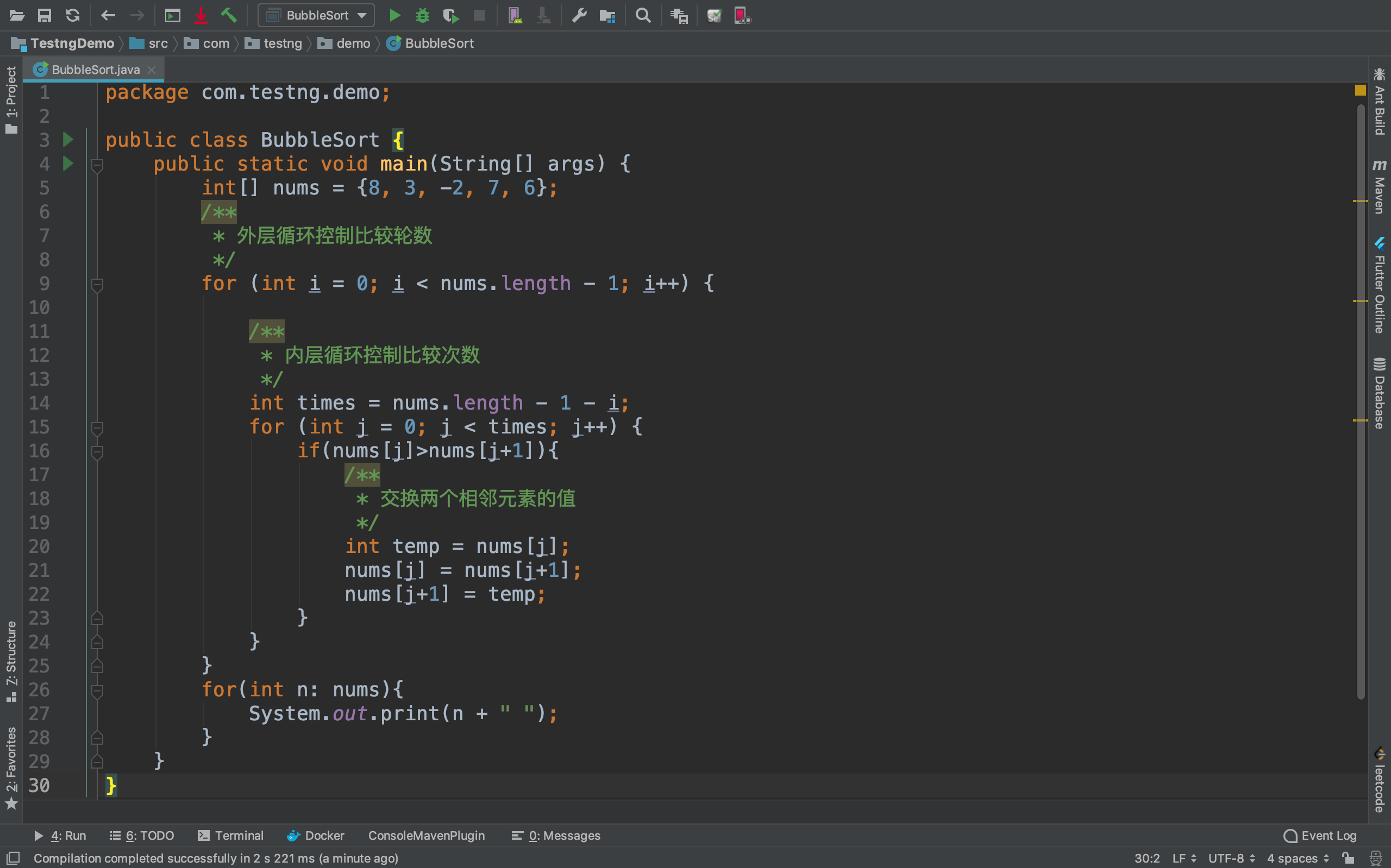
运行效果:

冒泡排序算法优化:
回顾一下刚刚描述的排序细节,仍以8,3,-2,7,6这个数组为例
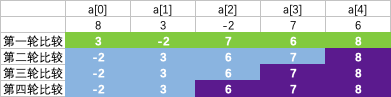
经过第二轮排序后,整个数组已经是有序的了,但是我们的排序算法仍然继续执行第三轮,第四轮
这种情况下,如果我们能判断出数组已经有序,并作出标记,剩下的几轮排序就可以不执行了,提前结束工作.
代码实现:
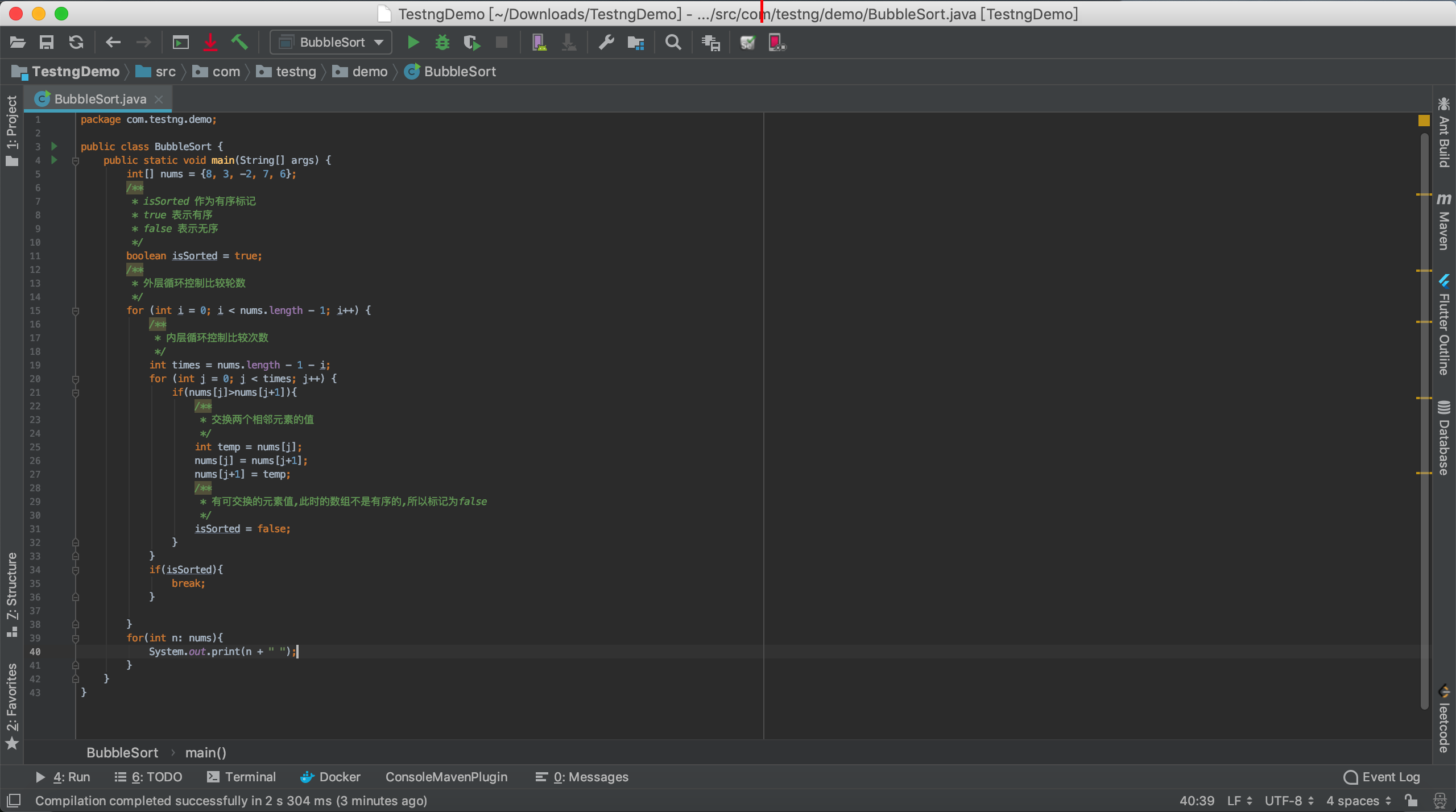
运行效果:

除此之外,我们还可以进一步优化冒泡排序算法.
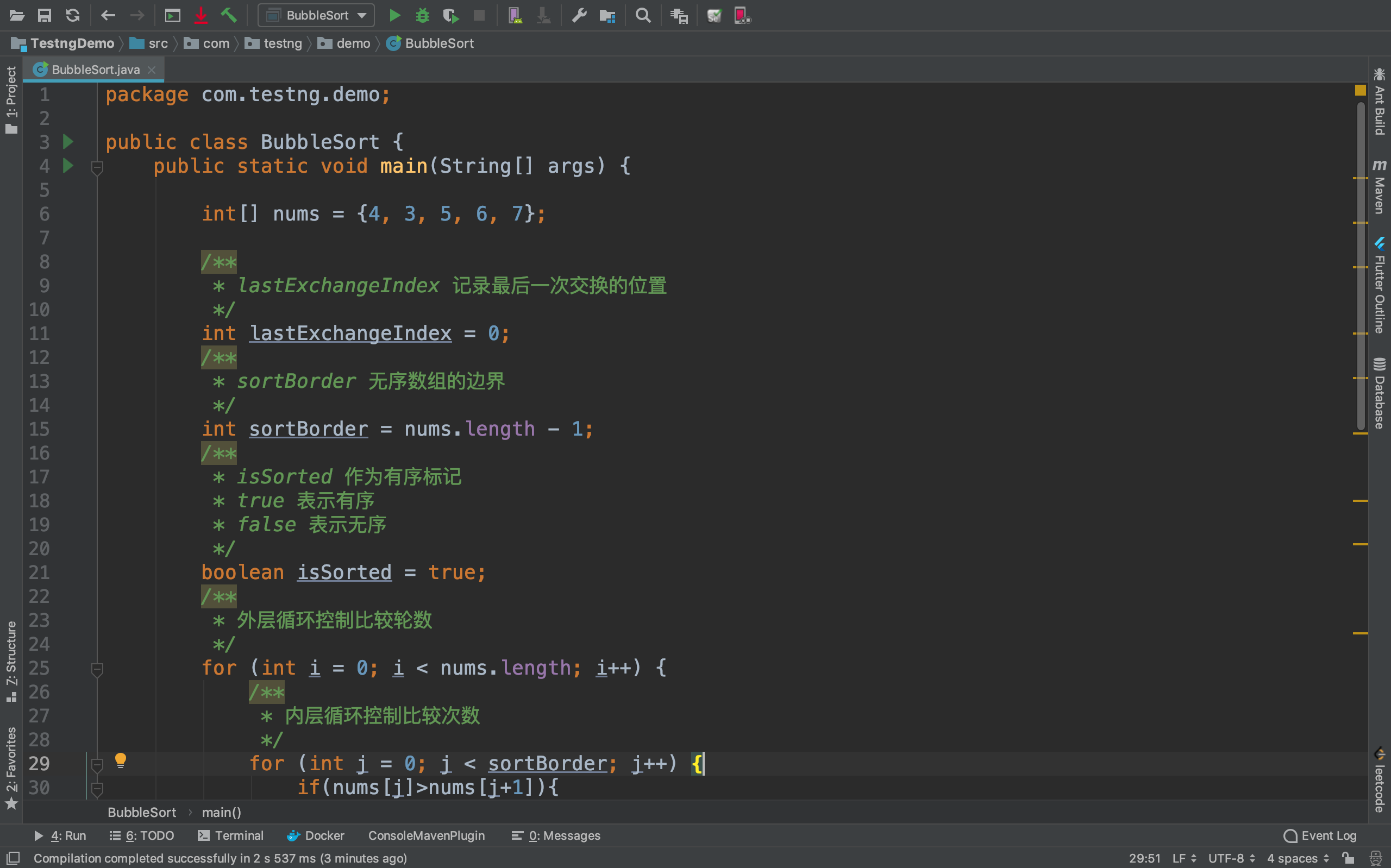
假设使用冒泡排序算法对数组{4, 3, 5, 6, 7} 按照从小到大顺序进行排序,那么我们应该如何对此进行优化呢?
分析:
该数组的特点是前半部分{4,3}无序,后半部分{5, 6, 7} 升序,并且后半部分的元素值已经是数组最大值
按照冒泡排序的思路进行排序
第一轮
元素4和3比较, 发现4大于3 所以4和3交换位置
元素4和5比较, 发现4小于5 所以4和5的位置不变
元素5和6比较, 发现5小于6 所以5和6的位置不变
元素6和7比较, 发现6小于7 所以6和7的位置不变
第一轮结束, 数组有序区包含元素值7

第二轮
元素3和4比较, 发现3小于4 所以3和4的位置不变
元素4和5比较, 发现4小于5 所以4和5的位置不变
元素5和6比较, 发现5小于6 所以5和6的位置不变
第二轮结束,数组有序区包含元素值6

其实数组中后半部分元素值已经是有序的了, 可是每一轮还是需要比较很多次
如果能对数组中有序区进行界定,那么每一轮中在有序区的元素值就可以不用再比较了,这样就可以进一步
提高冒泡排序算法的性能.
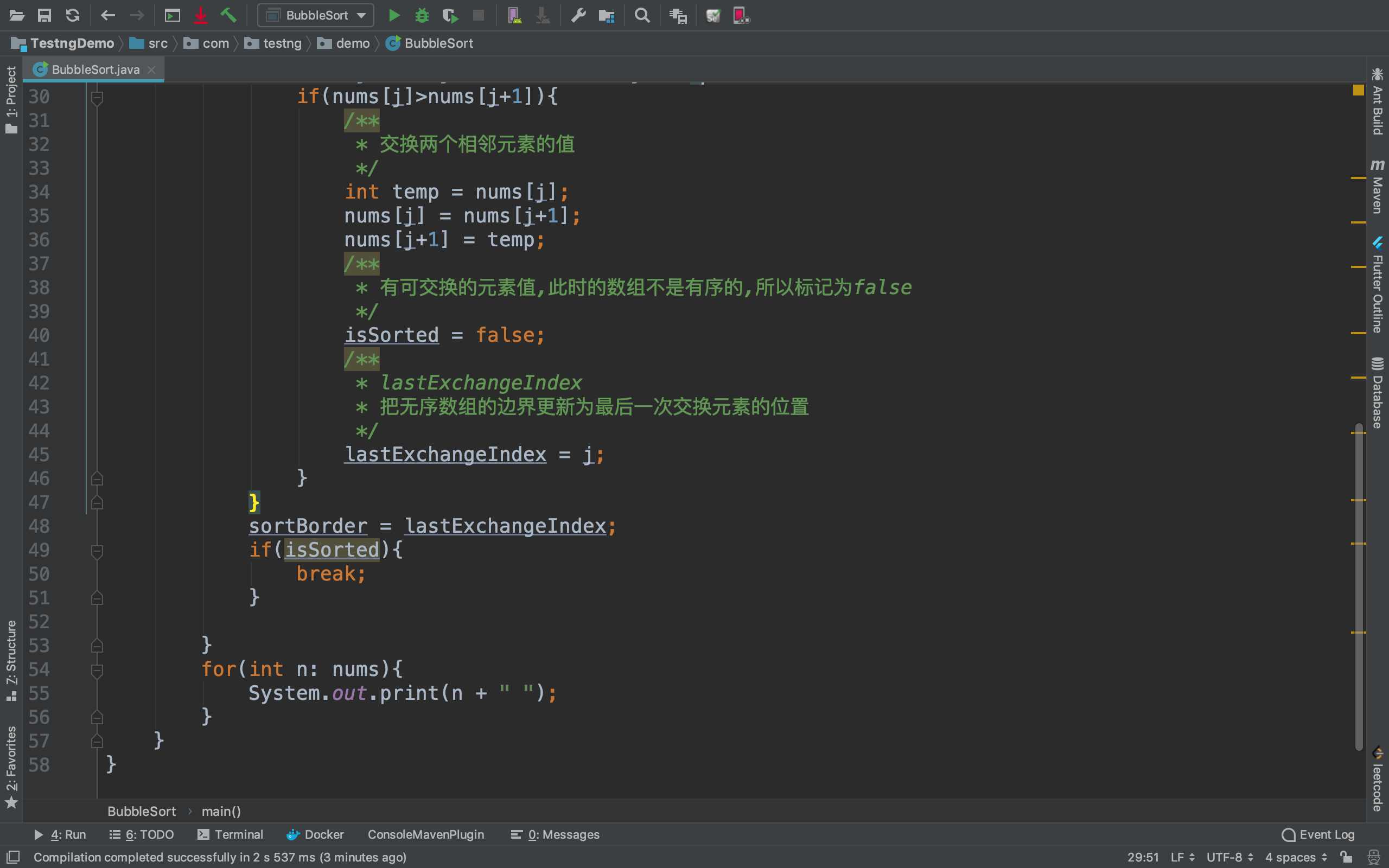
我们可以在每一轮排序的最后,记录下最后一次元素交换的位置,这个位置也就是无序数组的边界,之后的就是
有序区了.
代码实现:
运行效果
