本文基于Windows平台Eclipse,以使用MapReduce编程模型统计文本文件中相同单词的个数来详述了整个编程流程及需要注意的地方。不当之处还请留言指出。
前期准备
编写map阶段的map函数
package com.cnblogs._52mm;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 第一个参数:默认情况下是mapreduce框架所读文件的起始偏移量,类型为Long,在mr框架中类型为LongWritable
* 第二个参数:默认情况下是框架所读到的内容,类型为String,在mr框架中为Text
* 第三个参数:框架输出数据的key,在该单词统计的编程模型中输出的是单词,类型为String,在mr框架中为Text
* 第四个参数:框架输出数据的value,在此是每个所对应单词的个数,类型为Integer,在mr框架中为IntWritable
* @author Administrator
*
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
// map阶段的逻辑
// 对每一行输入数据调用一次我们自定义的map()方法
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
// 将传入的每一行数据转为String
String line = value.toString();
// 根据空格将单词划分
String[] words = line.split(" ");
for(String word: words){
//将word作为输出的key,1作为输出的value <word,1>
context.write(new Text(word), new IntWritable(1));
}
// mr框架不会在map处理完一行数据就发给reduce,会先将结果收集
}
}
编写reduce阶段的reduce函数
package com.cnblogs._52mm;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* reduce的输入是map的输出
* 第一个和第二个参数分别是map的输出类型
* 第三个参数是reduce程序处理完后的输出值key的类型,单词,为Text类型
* 第四个参数是输出的value的类型,每个单词所对应的总数,为IntWritable类型
* @author Administrator
*
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* map输出的内容相当于:
* <i,1><i,1><i,1><i,1><i,1><i,1>...
* <am,1><am,1><am,1><am,1><am,1><am,1>...
* <you,1><you,1><you,1><you,1><you,1><you,1>...
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
// Iterator<IntWritable> iterator = values.iterator();
// while(iterator.hasNext()){
// count += iterator.next().get();
// }
for(IntWritable value: values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
编写驱动类
package com.cnblogs._52mm;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相当于yarn集群的客户端,封装mapreduce的相关运行参数,指定jar包,提交给yarn
* @author Administrator
*
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 将默认配置文件传给job
Job job = Job.getInstance(conf);
// 告诉yarn jar包在哪
job.setJarByClass(WordCountDriver.class);
//指定job要使用的map和reduce
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 指定map的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定最终输出的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job的输入数据所在的目录
// 第一个参数:给哪个job设置
// 第二个参数:输入数据的目录,多个目录用逗号分隔
FileInputFormat.setInputPaths(job, new Path(args[0]));
// job的数据输出在哪个目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将jar包和配置文件提交给yarn
// submit方法提交作业就退出该程序
// job.submit();
// waitForCompletion方法提交作业并等待作业执行
// true表示将作业信息打印出来,该方法会返回一个boolean值,表示是否成功运行
boolean result = job.waitForCompletion(true);
// mr运行成功返回true,输出0表示运行成功,1表示失败
System.exit(result?0:1);
}
}
运行MapReduce程序
1、打jar包(鼠标右键工程-->Export)

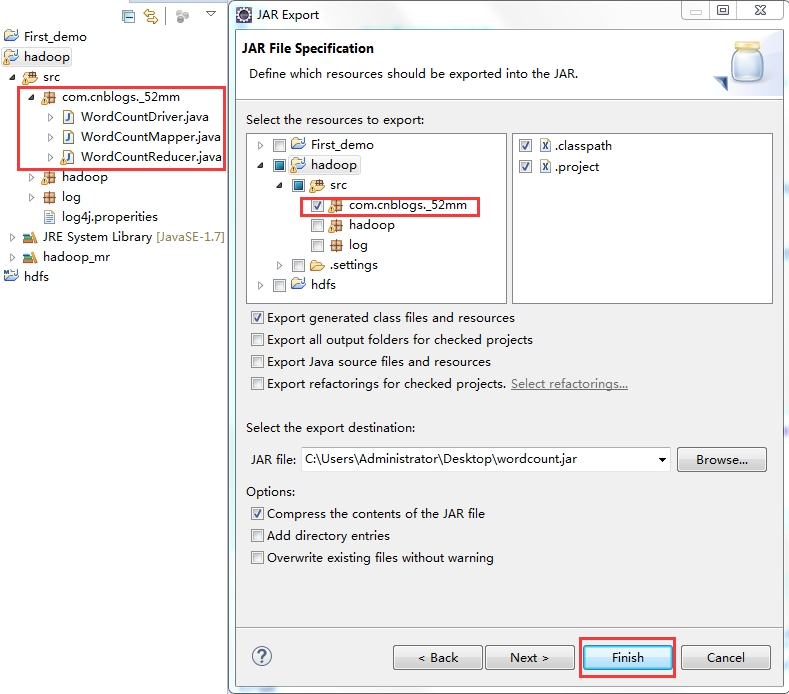
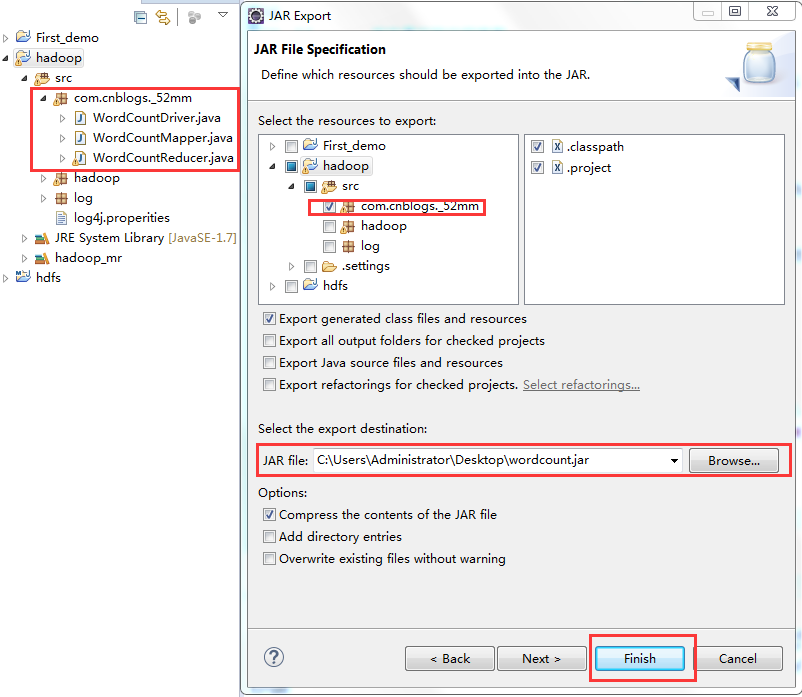
2、上传到hadoop集群上(集群中的任何一台都行),运行
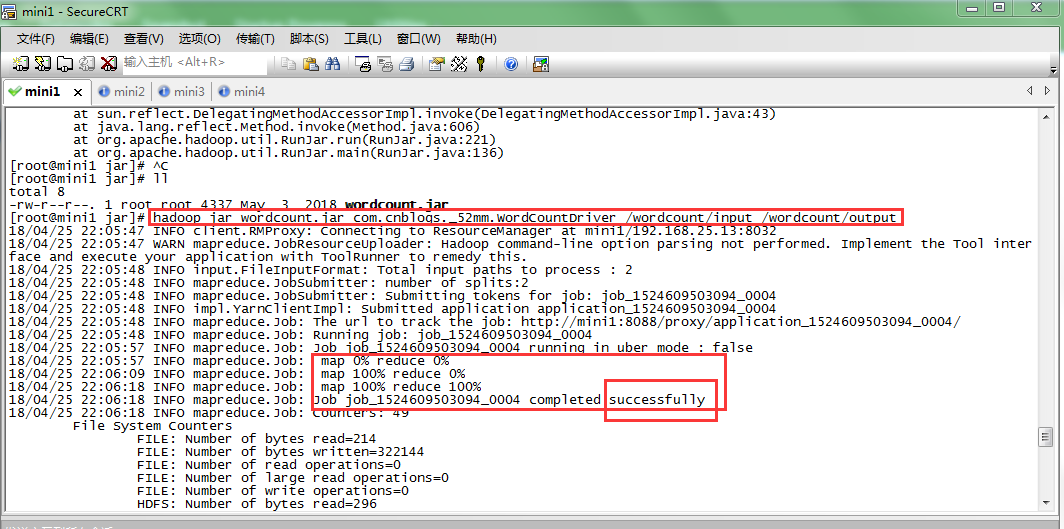
#wordcounrt.jar是刚刚从eclipse打包上传到linux的jar包
#com.cnblogs._52mm.WordCountDriver是驱动类的全名
#hdfs的/wordcount/input目录下是需要统计单词的文本
#程序输出结果保存在hdfs的/wordcount/output目录下(该目录必须不存在,由hadoop程序自己创建)
hadoop jar wordcount.jar com.cnblogs._52mm.WordCountDriver /wordcount/input /wordcount/output
3、也可用yarn的web界面查看作业信息
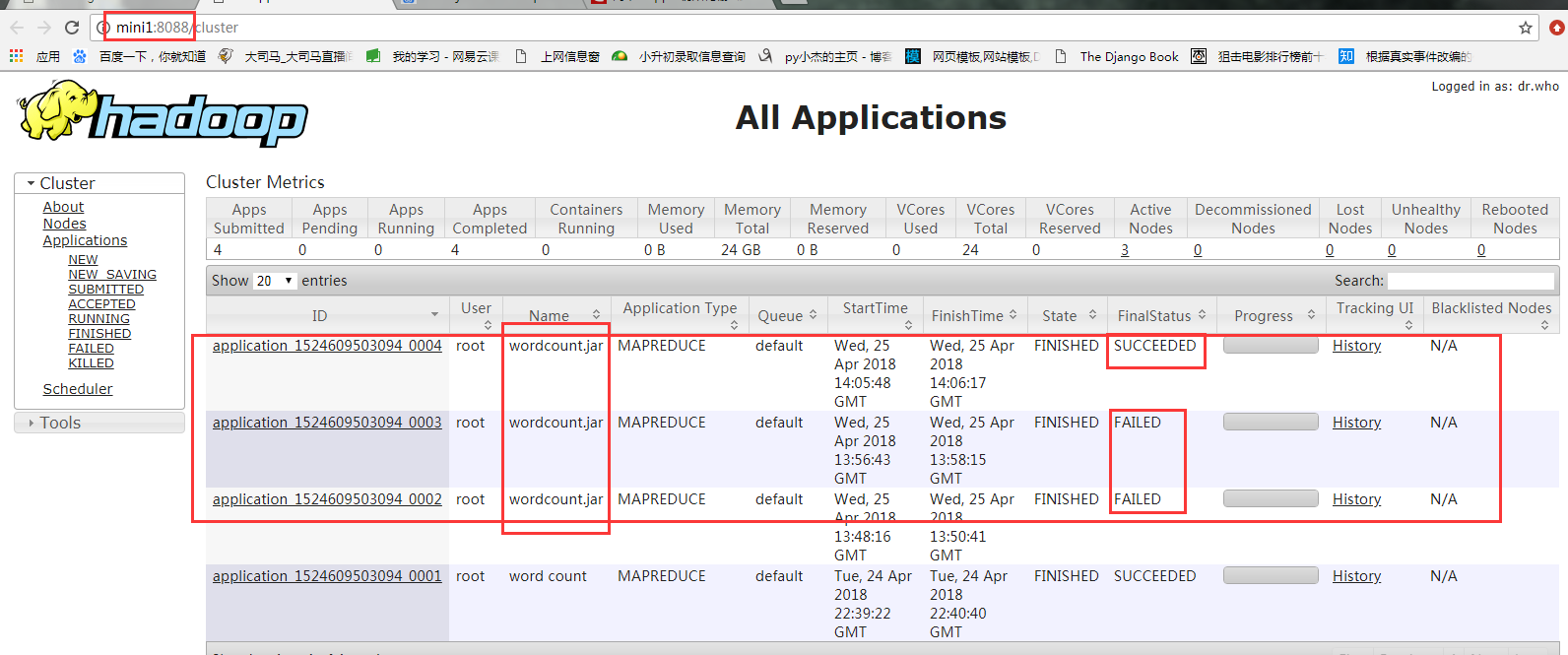
ps:在这里可以看到作业的详细信息,失败还是成功一目了然
4、查看输出结果
hadoop fs -cat /wordcount/output/part-r-00000
也可查看hdfs的web界面

报错解决
Error: java.io.IOException: Unable to initialize any output collector
at org.apache.hadoop.mapred.MapTask.createSortingCollector(MapTask.java:412)
at org.apache.hadoop.mapred.MapTask.access$100(MapTask.java:81)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.<init>(MapTask.java:695)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:767)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
该错误是由于编写代码时impor了错误的包导致的(我错在Text包导错了),仔细检查一下,改正后重新打jar包上传。
Output directory hdfs://mini1:9000/wordcount/output already exists
显然,该错误是由于reduce的输出目录必须是不存在才行,不能自己在hdfs上手动创建输出目录。
总结
- map函数和reduce函数的输入输出类型要用hadoop提供的基本类型(可优化网络序列化传输)
- LongWritable类型相当于java的Long类型,IntWritable类型相当于java的Integer类型,Text类型相当于java的String类型
- reduce函数的输入类型等于map函数的输出类型
- Job对象控制整个作业的执行。
- job对象的setJarByClass()方法传递一个类,hadoop利用这个类来找到相应的jar文件
- 运行作业前,输出目录不应该存在,否则hadoop会报错(为了防止覆盖了之前该目录下已有的数据)
- setOutputKeyClass()和setOutputValueClass()控制map和reduce函数的输出类型,这两个函数的输出类型一般相同,如果不同,则通过setMapOutputKeyClass()和setMapOutputValueClass()来设置map函数的输出类型。
- 输入数据的类型默认是TextInputFormat(文本),可通过InputFormat类来改变。
- Job中的waitForCompletion()方法提交作业并等待执行完成,传入true作为参数则会将作业的详细信息打印出来。作业执行成功返回true,执行失败返回false。
产品-订单统计(map端join)
原始数据
#订单信息(id,订单日期,商品id,商品数量)
1001,20150710,p0001,2
1002,20150710,p0001,3
1003,20150710,p0002,4
1004,20150710,p0002,5
#产品信息(商品id,商品名,商品类型id,单价)
p0001,小米5,1000,2000
p0002,锤子,1000,3000
结果数据
order_id=1002, dateString=20150710, p_id=p0001, amount=3, pname=小米5, category_id=1000, price=2000.0
order_id=1001, dateString=20150710, p_id=p0001, amount=2, pname=小米5, category_id=1000, price=2000.0
order_id=1004, dateString=20150710, p_id=p0002, amount=5, pname=锤子, category_id=1000, price=3000.0
order_id=1003, dateString=20150710, p_id=p0002, amount=4, pname=锤子, category_id=1000, price=3000.0
自定义bean
package com.xiaojie.join;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
//不将其当做key时只要实现writable即可,否则要用另一个还要实现比较大小,相同和hash三个方法
public class InfoBean implements Writable{
private int order_id;
private String dateString;
private String p_id;
private int amount;
private String pname;
private int category_id;
private float price;
//flag为0表示封装的是订单表的信息
//flag为1表示封装的为商品信息
private String flag;
public InfoBean() {
}
public void set(int order_id, String dateString, String p_id, int amount, String pname, int category_id, float price, String flag) {
this.order_id = order_id;
this.dateString = dateString;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.category_id = category_id;
this.price = price;
this.flag = flag;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public String getDateString() {
return dateString;
}
public void setDateString(String dateString) {
this.dateString = dateString;
}
public String getP_id() {
return p_id;
}
public void setP_id(String p_id) {
this.p_id = p_id;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public int getCategory_id() {
return category_id;
}
public void setCategory_id(int category_id) {
this.category_id = category_id;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeUTF(dateString);
out.writeUTF(p_id);
out.writeInt(amount);
out.writeUTF(pname);
out.writeInt(category_id);
out.writeFloat(price);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.order_id = in.readInt();
this.dateString = in.readUTF();
this.p_id = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.category_id = in.readInt();
this.price = in.readFloat();
this.flag = in.readUTF();
}
@Override
public String toString() {
return "order_id=" + order_id + ", dateString=" + dateString + ", p_id=" + p_id + ", amount=" + amount
+ ", pname=" + pname + ", category_id=" + category_id + ", price=" + price + ", flag=" + flag ;
}
}
mapreduce代码
package com.xiaojie.join;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Join {
static class JoinMapper extends Mapper<LongWritable, Text, Text, InfoBean>{
InfoBean bean = new InfoBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String pid = "";
FileSplit inputSplit =(FileSplit) context.getInputSplit();
//获取文件名
String name = inputSplit.getPath().getName();
if(name.startsWith("order")) {
String[] split = line.split(",");
//id date pid amount pname category_id price
pid = split[2];
bean.set(Integer.parseInt(split[0]), split[1], split[2], Integer.parseInt(split[3]), "", 0, (float) 0.0, "0");
}else {
String[] split = line.split(",");
//pid pname category price
pid = split[0];
bean.set(0, "", pid, 0, split[1], Integer.parseInt(split[2]), Float.parseFloat(split[3]), "1");
}
k.set(pid);
context.write(k, bean);
}
}
//reduce不用传value出去,用NullWritable
static class JoinReducer extends Reducer<Text, InfoBean, InfoBean, NullWritable>{
// key是商品的id,一个商品id对应一个商品信息,多个订单信息。
@Override
protected void reduce(Text key, Iterable<InfoBean> beans,Context context) throws IOException, InterruptedException {
InfoBean bean = new InfoBean();
ArrayList<InfoBean> orderBeans = new ArrayList<InfoBean>();
for(InfoBean obj:beans) {
//falg为“1”表示商品信息,为“0”表示订单信息
if("1".equals(obj.getFlag())) {
try {
//将obj对象里的数据拷贝到另一个对象
BeanUtils.copyProperties(bean, obj);
} catch (Exception e) {
e.printStackTrace();
}
}else {
InfoBean orderbean = new InfoBean();
try {
BeanUtils.copyProperties(orderbean, obj);
} catch (IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
orderBeans.add(orderbean);
}
}
//每个订单信息里都封装上商品名,商品分类id,商品价格
for(InfoBean orderbean: orderBeans) {
orderbean.setPname(bean.getPname());
orderbean.setCategory_id(bean.getCategory_id());
orderbean.setPrice(bean.getPrice());
//输出key,没有value
context.write(orderbean, NullWritable.get());
}
}
}
//驱动类
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 将默认配置文件传给job
Job job = Job.getInstance(conf);
//指定自定义的map数据分区器
// job.setPartitionerClass(ProvincePartitioner.class);
//根据partitioner里的分区数量,设置reduce的数量
// job.setNumReduceTasks(5);
// 告诉yarn jar包在哪
job.setJarByClass(Join.class);
//指定job要使用的map和reduce
job.setMapperClass(JoinMapper.class);
job.setReducerClass(JoinReducer.class);
// 指定map的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(InfoBean.class);
// 指定最终输出的类型
job.setOutputKeyClass(InfoBean.class);
job.setOutputValueClass(NullWritable.class);
// job的输入数据所在的目录
// 第一个参数:给哪个job设置
// 第二个参数:输入数据的目录,多个目录用逗号分隔
FileInputFormat.setInputPaths(job, new Path("/home/miao/test/input/product/");
// job的数据输出在哪个目录
FileOutputFormat.setOutputPath(job, new Path("/home/miao/test/output/product/");
//将jar包和配置文件提交给yarn
// submit方法提交作业就退出该程序
// job.submit();
// waitForCompletion方法提交作业并等待作业执行
// true表示将作业信息打印出来,该方法会返回一个boolean值,表示是否成功运行
boolean result = job.waitForCompletion(true);
// mr运行成功返回true,输出0表示运行成功,1表示失败
// System.exit(result?0:1);
System.out.println(result?0:1);
}
}
map端join
当两张表的数据差距很大,有一张小表的情况下,可以将小表分发到所有的map节点,这样map节点就可以在本地对自己所读到的大表数据进行join并输出最终结果,可以大大提高join操作的并发度,加快处理速度。这个案例里订单表是大表,而产品表是小表。
package com.xiaojie.join;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.math3.stat.descriptive.summary.Product;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MapSideJoin {
//这种方式可以避免reduce端数据量差距大
static class MapSideJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
// 存放产品信息
Map<String, String> productInfo_map = new HashMap<String, String>();
Text k = new Text();
//在调用map方法前会先调用setup方法一次 用来做一些初始化工作
//在进行map方法前先获取到商品信息
@Override
protected void setup(Context context) throws IOException, InterruptedException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("product.txt")));
String line;
//读入一行数据看是否为空
while(StringUtils.isNotEmpty(line = br.readLine())) {
String[] fields = line.split(",");
// 商品id和商品名
productInfo_map.put(fields[0], fields[1]);
}
br.close();
}
//由于已经有了完整的产品信息表,所以在map方法中就能完成join逻辑 传入map的数据是订单信息
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String order_info = value.toString();
String[] fields = order_info.split(",");
//根据商品id获取商品的名称 将名称加入到订单信息,即可完成任务
String pname = productInfo_map.get(fields[1]);
k.set(order_info + "," + pname);
context.write(k, NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(MapSideJoin.class);
job.setMapperClass(MapSideJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("/home/miao/test/input/mapsideJoin/order2"));
FileOutputFormat.setOutputPath(job, new Path("/home/miao/test/output/product2"));
// job.addArchiveToClassPath(archive); 缓存jar包到task运行节点的classpath中
// job.addFileToClassPath(file);//缓存普通文件到task运行节点的classpath中
// job.addCacheArchive(uri);//缓存压缩文件到task运行节点的工作目录
// job.addCacheFile(uri);//缓存普通文件到task运行节点的工作目录
//将产品信息表文件缓存到task工作节点的工作目录中
job.addCacheFile(new URI("file:///home/miao/test/input/mapsideJoin/product.txt"));
//map端就能完成任务,不需要reduce,将reduce数量设为0
job.setNumReduceTasks(0);
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
GroupingComparator(bean作为key,实现bean成组)
原始数据(订单号,价格)
Order_0000001 222.8
Order_0000001 25.8
Order_0000002 522.8
Order_0000002 122.4
Order_0000002 722.4
Order_0000003 222.8
要求:
每个相同的订单中消费价格最高的
方法:
在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值。
结果数据:
Order_0000001 222.8
Order_0000002 722.4
Order_0000003 222.8
自定义bean
package com.xiaojie.bean_key;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
/**
* 订单信息bean,实现hadoop的序列化机制
*/
public class OrderBean implements WritableComparable<OrderBean>{
private Text itemid;
private DoubleWritable amount;
public OrderBean() {
}
public OrderBean(Text itemid, DoubleWritable amount) {
set(itemid, amount);
}
public void set(Text itemid, DoubleWritable amount) {
this.itemid = itemid;
this.amount = amount;
}
public Text getItemid() {
return itemid;
}
public DoubleWritable getAmount() {
return amount;
}
@Override
public int compareTo(OrderBean o) {
int cmp = this.itemid.compareTo(o.getItemid());
if (cmp == 0) {
//根据价格倒叙排序,为了得到价钱最大的哪个key
cmp = -this.amount.compareTo(o.getAmount());
}
return cmp;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(itemid.toString());
out.writeDouble(amount.get());
}
@Override
public void readFields(DataInput in) throws IOException {
String readUTF = in.readUTF();
double readDouble = in.readDouble();
this.itemid = new Text(readUTF);
this.amount= new DoubleWritable(readDouble);
}
@Override
public String toString() {
return itemid.toString() + " " + amount.get();
}
}
自定义groupingcomparator
package com.xiaojie.bean_key;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class ItemidGroupingComparator extends WritableComparator{
//传入作为key的bean的class
protected ItemidGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean abean = (OrderBean) a;
OrderBean bbean = (OrderBean) b;
//将item_id相同的bean都视为相同,从而聚合为一组
//OrderBean对象的id是Text的类型,所以这里使用的是Text的compareTo方法
//返回0表示两个bean对象相同
return abean.getItemid().compareTo(bbean.getItemid());
}
}
自定义分区逻辑
package com.xiaojie.bean_key;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class ItemIdPartitioner extends Partitioner<OrderBean,NullWritable> {
// partitionr的输入是map的输出
@Override
public int getPartition(OrderBean bean, NullWritable value, int numReduceTasks) {
// 根据id使用hash分区,id相同的被分到同一个区
return (bean.getItemid().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
mapreduce代码
package com.xiaojie.bean_key;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Bean_key {
static class SecondarySortMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
OrderBean bean = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, " ");
bean.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[1])));
context.write(bean, NullWritable.get());
}
}
static class SecondarySortReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
//在设置了groupingcomparator以后,这里收到的kv数据 就是: <1001 87.6>,null <1001 76.5>,null ....
//此时,reduce方法中的参数key就是上述kv组中的第一个kv的key:<1001 87.6>
//要输出同一个item的所有订单中最大金额的那一个,就只要输出这个key
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Bean_key.class);
job.setMapperClass(SecondarySortMapper.class);
job.setReducerClass(SecondarySortReducer.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("/home/miao/test/input/bean_key"));
FileOutputFormat.setOutputPath(job, new Path("/home/miao/test/output/bean_key"));
//指定shuffle所使用的GroupingComparator类
job.setGroupingComparatorClass(ItemidGroupingComparator.class);
//指定shuffle所使用的partitioner类
// job.setPartitionerClass(ItemIdPartitioner.class);
// job.setNumReduceTasks(3);
job.waitForCompletion(true);
}
}
自定义OutputFormat
工作描述:
数据是一批日志数据,里面有浏览网页的信息,还有一个数据是前期通过爬虫等技术爬取到的网页数据(保存在数据库里),要对日志数据做的处理是,从每条日志记录里获取到url信息,根据这条url信息对比数据库里已经保存的信息,如果数据库里有这个url,则将数据库中这个url所对应的信息添加到这条日志数据的后面,保存到一个新的日志文件里;如果数据库里没有这个url,就将这个url保存到另一个文件里作为等待爬取的url。
自定义从数据库读数据的类
package com.xiaojie.logenhance;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashMap;
import java.util.Map;
public class DBLoader {
public static void dbLoader(Map<String, String> rule_map) {
//从数据库中加载规则数据到Map里
Connection conn = null;
Statement st = null;
ResultSet res = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/hadoop", "test", "123456");
st = conn.createStatement();
res = st.executeQuery("select url,content from url_rule");
while (res.next()) {
rule_map.put(res.getString(1), res.getString(2));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try{
if(res!=null){
res.close();
}
if(st!=null){
st.close();
}
if(conn!=null){
conn.close();
}
}catch(Exception e){
e.printStackTrace();
}
}
}
// public static void main(String[] args) {
// DBLoader db = new DBLoader();
// HashMap<String, String> map = new HashMap<String,String>();
// db.dbLoader(map);
// System.out.println(map.size());
// }
}
mapreduce程序
package com.xiaojie.logenhance;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogEnhance {
static class LogEnhanceMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Map<String, String> tag = new HashMap<String,String>();
Text k = new Text();
NullWritable v = NullWritable.get();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 从数据库中读取出数据加载到内存里
// maptask在初始化时会先调用setup方法一次 利用这个机制,将外部的知识库加载到maptask执行的机器内存中
DBLoader.dbLoader(tag);
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//计数器 第一个参数组号 第二个参数计数器名 全局的,所有map都能在这一个计数器上累加
Counter counter = context.getCounter("err","err_line");
String line = value.toString();
String[] fields = line.split(" ");
try {
// 获取日志信息的url
String url = fields[26];
if (!url.startsWith("http")) {
counter.increment(1);
}
String content = tag.get(url);
//判断内容标签是否为空,如果是空则只输出url和标记(标记信息表示数据库里还没有这个url所对应的信息,需要输出到另外的文件夹另做处理)
//否则输出原来的那行日志数据+标签内容
if(content==null) {
k.set(url+" "+"tocrawl"+"
");
}else {
k.set(line+" "+content+"
");
}
context.write(k, v);
}catch (Exception e) {
// 计数器,遇到一条错误的数据(字段不完整)就加1
counter.increment(1);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogEnhance.class);
job.setMapperClass(LogEnhanceMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 要将自定义的输出格式组件设置到job中 默认是FileOutputFormat
job.setOutputFormatClass(LogEnhanceOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("/home/miao/test/input/log_enhance/"));
// 虽然我们自定义了outputformat(自定义的里面已经有了数据的输出位置),但是因为我们的outputformat继承自fileoutputformat
// 而fileoutputformat要输出一个_SUCCESS文件,所以,在这还得指定一个输出目录,这个输出目录下只会有一个_SUCCESS文件
FileOutputFormat.setOutputPath(job, new Path("/home/miao/test/output/log_enhance2/"));
job.waitForCompletion(true);
System.exit(0);
}
}
自定义OutputFormat
package com.xiaojie.logenhance;
import java.io.IOException;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogEnhanceOutputFormat extends FileOutputFormat<Text, NullWritable> {
//maptask或reducetask在输出数据时,先调用OutputFormat的getRecordWriter方法获取RecordWriter
//再使用RecordWriter对象调用write(k,v)方法将数据写出
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext context)
throws IOException, InterruptedException {
// 获取hdfs客户端
FileSystem fs = FileSystem.get(context.getConfiguration());
// Path logenhance = new Path("hdfs://mini1:9000/output/logenhance/log.data");
// Path todosomething = new Path("hdfs://mini1:9000/output/todosomeing/log.data");
Path logenhance = new Path("/home/miao/test/output/logenhance/log.data");
Path todosomething = new Path("/home/miao/test/output/logenhance/url.data");
// 打开文件
FSDataOutputStream enhanceString = fs.create(logenhance);
FSDataOutputStream todosomething_String = fs.create(todosomething);
//构造方法传入两个输出流作为参数
return new LogEnhanceRecordWriter(enhanceString,todosomething_String);
}
static class LogEnhanceRecordWriter extends RecordWriter<Text, NullWritable>{
FSDataOutputStream enhanceString = null;
FSDataOutputStream todosomething_String = null;
public LogEnhanceRecordWriter(FSDataOutputStream enhanceOut, FSDataOutputStream toCrawlOut) {
super();
this.enhanceString = enhanceOut;
this.todosomething_String = toCrawlOut;
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
String result = key.toString();
//如果要写出的数据是带爬取的位置url,则写出到/home/miao/test/output/logenhance/url.data
if(result.contains("tocrawl")) {
todosomething_String.write(result.getBytes());
}else {
//没有标记的数据 写出到log日志里 /home/miao/test/output/logenhance/log.data
enhanceString.write(result.getBytes());
}
}
//关闭输出流
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
if(todosomething_String != null) {
todosomething_String.close();
}
if(enhanceString != null) {
enhanceString.close();
}
}
}
}
多job串联
复杂的作业往往需要多个mapreduce串联执行,可再驱动类中创建好多个job并为多个job配置好相应的信息,再利用mapreduce框架的JobControl实现。
//这个驱动类的前面已经创建并配置好了三个job
ControlledJob cJob1 = new ControlledJob(job1.getConfiguration());
ControlledJob cJob2 = new ControlledJob(job2.getConfiguration());
ControlledJob cJob3 = new ControlledJob(job3.getConfiguration());
cJob1.setJob(job1);
cJob2.setJob(job2);
cJob3.setJob(job3);
// 设置作业依赖关系
cJob2.addDependingJob(cJob1);
cJob3.addDependingJob(cJob2);
JobControl jobControl = new JobControl("RecommendationJob");
jobControl.addJob(cJob1);
jobControl.addJob(cJob2);
jobControl.addJob(cJob3);
// 新建一个线程来运行已加入JobControl中的作业,开始进程并等待结束
Thread jobControlThread = new Thread(jobControl);
jobControlThread.start();
while (!jobControl.allFinished()) {
Thread.sleep(500);
}
jobControl.stop();
return 0;
实际工作中不建议用joncontrol的方式将多个job串联来执行,因为这种方式会使得多个job打在了一个jar包里,只需要执行其中一部分job时无法解耦出来。更加建议的是使用shell脚本等方式将多个mapreduce程序串联起来执行,这样多个mapreduce程序完全解耦,更加方便控制。