hadoop简介
Hadoop 是一个由 Apache 基金会所开发的开源分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。适合处理非结构化数据,包括 HDFS,MapReduce等基本组件。
Hadoop应用场景
(1)hadoop采用分布式集群的方式处理海量数据(存储和分析);
(2)可以把hadoop理解为一个编程框架(比如structs、spring),有着自己特定的API封装和用户编程规范,用户可借助这些API来实现数据处理逻辑;
(3)从另一个角度,hadoop又可以理解为一个提供服务的软件(比如数据库服务oracle/mysql、索引服务solr,缓存服务redis等),用户程序的功能都是通过客户端向hadoop集群请求服务来实现;
(4)具体来说,hadoop两个大的功能:海量数据的存储;海量数据的分析;
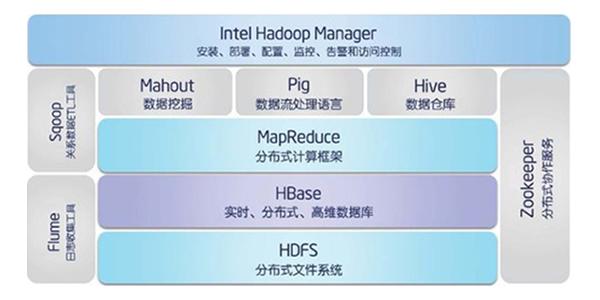
(5)Hadoop有3大核心组件:
- HDFS:
hadoop分布式文件系统海量数据的存储集群。 - MapReduce:
运算框架,海量数据运算分析(替代品:storm /spark/tez等 )。 - Yarn:
资源调度管理集群。
(6)Hadoop产生的历史
- 最早来自于google的三大论文(为什么google会需要这么一种技术)
- Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP
- 经过演化,hadoop的组件又多出一个yarn(mapreduce+ yarn + hdfs),而且,hadoop外围产生了越来越多的工具组件,形成一个庞大的hadoop生态体系。
hadoop版本
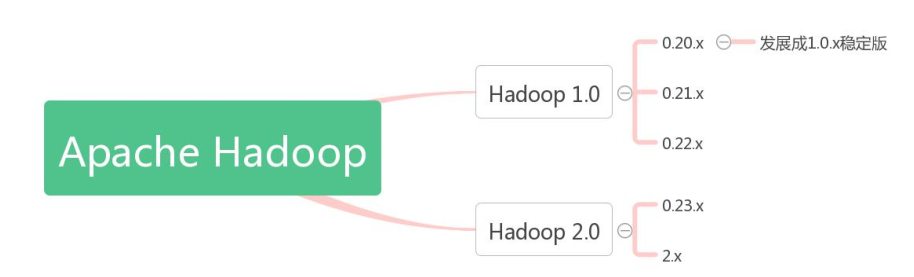
第一代 Hadoop 包含三个大版本 , 分别是 0.20.x ,0.21.x 和 和 0.22.x,其中,0.20.x 最后演化成 1.0.x,变成了稳定版。
第二代 Hadoop 包含两个版本,分别是 0.23.x 和 和 2.x,它们完全不同于 Hadoop 1.0,是一套全新的架构,均包含 HDFS Federation 和 YARN 两个系统,相比于 0.23.x,2.x 增加了NameNode HA 和 Wire-compatibility 两个重大特性。
hadoop生态圈
对于一些人来说,Hadoop 是一个数据管理系统。他们认为 Hadoop 是数据分析的核心,汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。
对于其他人,Hadoop 是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。
还有一些人认为 Hadoop 作为一个开源社区,主要为解决大数据的问题提供工具和软件。因为 Hadoop 可以用来解决很多问题,所以很多人认为 Hadoop 是一个基本框架。
虽然 Hadoop 提供了这么多的功能,但是仍然应该把它归类为多个组件组成的 Hadoop生态圈,这些组件包括数据存储、数据集成、数据处理和其它进行数据分析的专门工具。
-
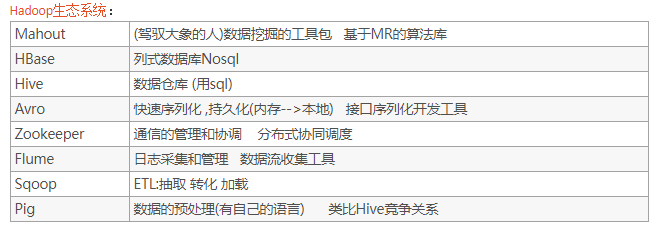
HDFS:Hadoop 生态圈的基本组成部分是 Hadoop 分布式文件系统(HDFS)。HDFS 是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS为 HBase 等工具提供了基础。
-
MapReduce:Hadoop 的主要执行框架是 MapReduce,它是一个分布式、并行处理的编程模型。MapReduce 把任务分为 map(映射)阶段和 reduce(化简)。开发人员使用存储在HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务。由于 MapReduce工作原理的特性, Hadoop 能以并行的方式访问数据,从而实现快速访问数据。
-
Hbase:HBase 是一个建立在 HDFS 之上,面向列的 NoSQL 数据库,用于快速读/写大量数据。HBase 使用Zookeeper 进行管理,确保所有组件都正常运行。
-
ZooKeeper:用于 Hadoop 的分布式协调服务。Hadoop 的许多组件依赖于 Zookeeper,它运行在计算机集群上面,用于管理 Hadoop 操作。
-
Hive:Hive 类似于 SQL 高级语言,用于运行存储在 Hadoop 上的查询语句,Hive 让不熟悉 MapReduce 开发人员也能编写数据查询语句,然后这些语句被翻译为 Hadoop 上面的 MapReduce 任务。像 Pig 一样,Hive 作为一个抽象层工具,吸引了很多熟悉 SQL 而不是 Java 编程的数据分析师。
-
Pig:它是 MapReduce 编程的复杂性的抽象。Pig 平台包括运行环境和用于分析 Hadoop数据集的脚本语言(Pig Latin)。其编译器将 Pig Latin 翻译成 MapReduce 程序序列。
-
Sqoop:是一个连接工具,用于在关系数据库、数据仓库和 Hadoop 之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用 MapReduce 实现并行化运行和容错技术。
8)Flume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移Hadoop。
9)Whirr——Whirr是一组用来运行云服务的Java类库,使用户能够轻松地将Hadoop集群运行于Amazon EC2、Rackspace等虚拟云计算平台。
10)Mahout——Mahout是一个机器学习和数据挖掘库,它提供的MapReduce包含很多实现,包括聚类算法、回归测试、统计建模。通过使用 Apache Hadoop 库,可以将Mahout有效地扩展到云中。
11)BigTop —— BigTop作为Hadoop子项目和相关组件,是一个用于打包和互用性测试的程序和框架。
12)Ambari——Ambar为配置、管理和监控Hadoop集群提供支持,简化了Hadoop的管理。