IPFS 和区块链有着非常紧密的联系, 随着区块链的不断发展,对数据的存储需求也越来越高。本文从IPFS 的底层设计出发, 结合源代码, 分析了IPFS 的一些技术细节。
一、概述
IPFS 和区块链有着非常紧密的联系, 随着区块链的不断发展,对数据的存储需求也越来越高, 由于性能和成本的限制,现有的区块链设计方案大部分都选择了把较大的数据存储在链外,通过对数据进行加密, 哈希运算等手段来防止数据被篡改, 在区块链上只引用所存数据的hash 值, 从而满足业务对数据的存储需求。 本文从IPFS 的底层设计出发, 结合源代码, 分析了IPFS 的一些技术细节。 由于IPFS还在不断更新中, 文中引用的部分可能和最新代码有所出入。
阅读本文需要读者
- 了解网络编程
- 了解分布式存储
- 了解基本的区块链知识
二、什么是IPFS?
维基百科上是这样解释的:是一个旨在创建持久且分布式存储和共享文件的网络传输协议。
上面的解释稍显晦涩, 我的理解是:
1. 首先它是一个FS(文件系统)
2. 其次它支持点对点传输
既然是文件系统, 那它和普通的文件系统有什么区别呢? 有以下几点区别:
- 存储方式: 它是分布式存储的, 为了方便传输,文件被切分成多个block, 每个block 通过hash运算得到唯一的ID, 方便在网络中进行识别和去重。 考虑到传输效率, 同一个block 可能有多个copy, 分别存储在不同的网络节点上。
- 内容寻址方式: 每个block都有唯一的ID,我们只需要根据节点的ID 就可以获取到它所对应的block。
那么问题来了, 既然文件被切分成了多个block,如何组织这些block 数据,组成逻辑上的文件呢? 在IFPS中采用的merkledag, 下面是 merkledag的一个示意图:

简单来说, 就是2种数据结构merkle 和DAG(有向无环图)的结合, 通过这种逻辑结构, 可以满足:
- 内容寻址: 使用hash ID来唯一识别一个数据块的内容
- 防篡改: 可以方便的检查哈希值来确认数据是否被篡改
- 去重: 由于内容相同的数据块哈希是相同的,可以很容去掉重复的数据,节省存储空间
确定了数据模型后, 接下来要做的事: 如何把数据分发到不同的网络节点上, 达到分布式存储和共享的目的? 我们先思考一下, 通过网络,比如HTTP, 访问某个文件的步骤,首先我们要知道存储这个文件的服务器地址, 然后我们需要知道这个文件对应的ID, 比如文件名。前者我们可以抽象成网络节点寻址, 后者我们抽象成文件对象寻址; 在IPFS中, 这两种寻址方式使用了相同的算法, KAD, 介绍KAD算法的文章很多,这里不赘述, 只简单说明一下核心思想:
KAD 最精妙之处就是使用XOR 来计算ID 之间的距离,并且统一了节点ID 和 对象ID的寻址方式。 采用 XOR(按比特异或操作)算法计算 key 之间的“距离”。
这种做法使得它具备了类似于“几何距离”的某些特性(下面用 ⊕ 表示 XOR)
- (A ⊕ B) == (B ⊕ A) XOR 符合“交换律”,具备对称性。
- (A ⊕ A) == 0 反身性,自身距离为零
- (A ⊕ B) > 0 【不同】的两个 key 之间的距离必大于零
- (A ⊕ B) + (B ⊕ C) >= (A ⊕ C) 三角不等式
通过KAD算法,IPFS 把不同ID的数据块分发到与之距离较近的网络节点中,达到分布式存储的目的。
通过IPFS获取文件时,只需要根据merkledag, 按图索骥,根据每个block的ID, 通过KAD算法从相应网络节点中下载block数据, 最后验证是否数据完整, 完成拼接即可。
下面我们再从技术实现的角度做更深入的介绍。
三、IPFS的系统架构
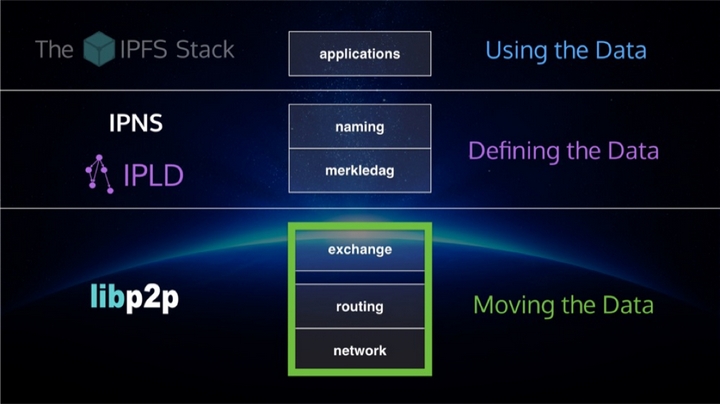
我们先看一下IPFS的系统架构图, 分为5层:
- 一层为naming, 基于PKI的一个命名空间;
- 第二层为merkledag, IPFS 内部的逻辑数据结构;
- 第三层为exchange, 节点之间block data的交换协议;
- 第四层为routing, 主要实现节点寻址和对象寻址;
- 第五层为network, 封装了P2P通讯的连接和传输部分。
站在数据的角度来看, 又可以分为2个大的模块:
- IPLD( InterPlanetary Linked Data) 主要用来定义数据, 给数据建模;
- libp2p解决的是数据如何传输的问题。
下面分别介绍IFPS 中的2个主要部分IPLD 和 libP2P。
1.IPLD
通过hash 值来实现内容寻址的方式在分布式计算领域得到了广泛的应用, 比如区块链, 再比如git repo。 虽然使用hash 连接数据的方式有相似之处, 但是底层数据结构并不能通用, IPFS 是个极具野心的项目, 为了让这些不同领域之间的数据可互操作, 它定义了统一的数据模型IPLD, 通过它, 可以方便地访问来自不同领域的数据。
前面已经介绍数据的逻辑结构是用merkledag表示的, 那么它是如何实现的呢? 围绕merkledag作为核心, 它定义了以下几个概念:
- merkle link 代表dag 中的边
- merkel-dag 有向无环图
- merkle-path 访问dag节点的类似unix path的路径
- IPLD data model 基于json 的数据模型
- IPLD serialized format 序列化格式
- canonical 格式: 为了保证同样的logic object 总是序列化为一个同样的输出, 而制定的确定性规则
围绕这些定义它实现了下面几个components
- CID 内容ID
- data model 数据模型
- serialization format 序列化格式
- tools & libraries 工具和库
- IPLD selector 类似CSS 选择器, 方便选取dag中的节点
- IPLD transformation 对dag 进行转换计算
我们知道,数据是多样性的,为了给不同的数据建模, 我们需要一种通用的数据格式, 通过它可以最大程度地兼容不同的数据, IPFS 中定义了一个抽象的集合, multiformat, 包含multihash、multiaddr、multibase、multicodec、multistream几个部分。
(一)multihash
自识别hash, 由3个部分组成,分别是:hash函数编码、hash值的长度和hash内容, 下面是个简单的例子:
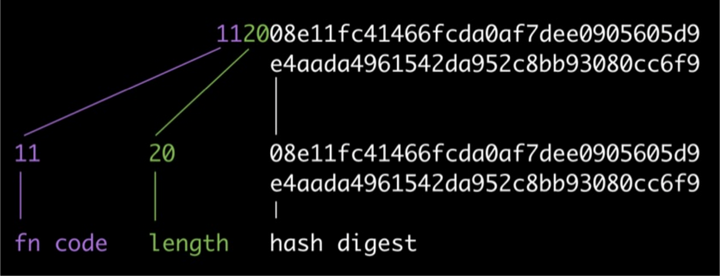
这种设计的最大好处是非常方便升级,一旦有一天我们使用的hash 函数不再安全了, 或者发现了更好的hash 函数,我们可以很方便的升级系统。
(二)multiaddr
自描述地址格式,可以描述各种不同的地址

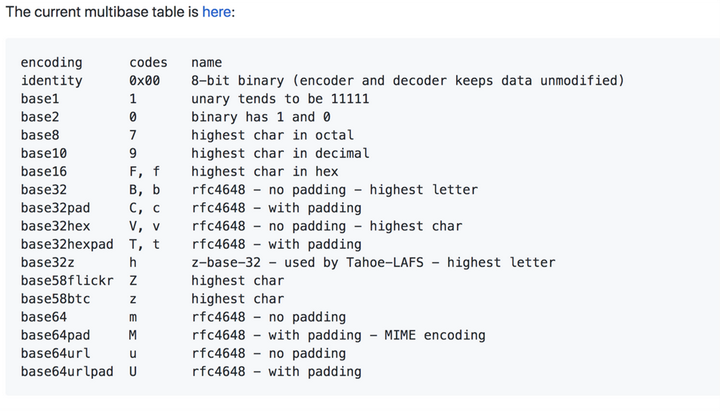
(三)multibase
multibase 代表的是一种编码格式, 方便把CID 编码成不同的格式, 比如这里定义了2进制、8进制、10进制、16进制、也有我们熟悉的base58btc 和 base64编码。
(四)multicodec
mulcodec 代表的是自描述的编解码, 其实是个table, 用1到2个字节定了数据内容的格式, 比如用字母z表示base58btc编码, 0x50表示protobuf 等等。

五)multistream
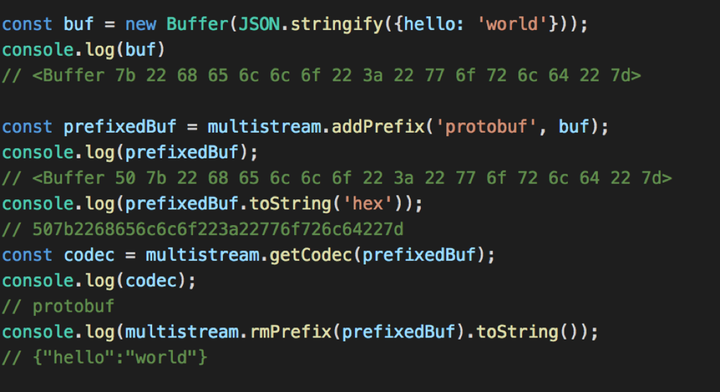
multistream 首先是个stream, 它利用multicodec,实现了自描述的功能, 下面是基于一个javascript 的例子; 先new 一个buffer 对象, 里面是json对象, 然后给它加一个前缀protobuf, 这样这个multistream 就构造好了, 可以通过网络传输。在解析时可以先取codec 前缀,然后移除前缀, 得到具体的数据内容。
结合上面的部分, 我们重点介绍一下CID。
CID 是IPFS分布式文件系统中标准的文件寻址格式,它集合了内容寻址、加密散列算法和自我描述的格式, 是IPLD 内部核心的识别符。目前有2个版本,CIDv0 和CIDv1。
CIDv0是一个向后兼容的版本,其中:
- multibase 一直为 base58btc
- multicodec 一直为 protobuf-mdag
- version 一直为 CIDv0
- multihash 表示为cidv0 ::= <multihash-content-address>
为了更灵活的表述ID数据, 支持更多的格式, IPLD 定义了CIDv1,CIDv1由4个部分组成:

- multibase
- version
- multicodec
- multihash
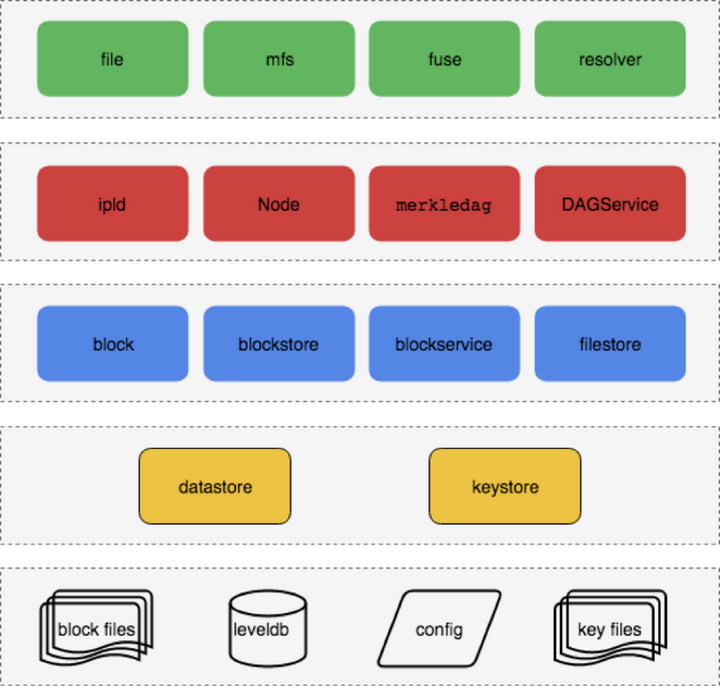
IPLD 是IPFS 的数据描述格式, 解决了如何定义数据的问题, 下面这张图是结合源代码整理的一份逻辑图,我们可以看到上面是一些高级的接口, 比如file, mfs, fuse 等。 下面是数据结构的持久化部分,节点之间交换的内容是以block 为基础的, 最下面就是物理存储了。比如block 存储在blocks 目录, 其他节点之间的信息存储在leveldb, 还有keystore, config 等。
2.数据如何传输呢?
接下来我们介绍libP2P, 看看数据是如何传输的。libP2P 是个模块化的网络协议栈。

做过socket编程的小伙伴应该都知道, 使用raw socket 编程传输数据的过程,无非就是以下几个步骤:
- 获取目标服务器地址
- 和目标服务器建立连接
- 握手协议
- 传输数据
- 关闭连接
libP2P 也是这样,不过区别在于它把各个部分都模块化了, 定义了通用的接口, 可以很方便的进行扩展。
(一)架构图
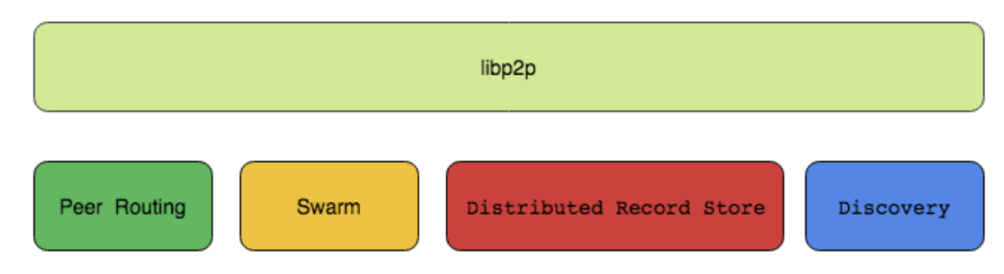
由以下几个部分组成,分别是:
- Peer Routing
- Swarm (传输和连接)
- Distributed Record Store
- Discovery
下面我们对它们做分别介绍, 我们先看关键的路由部分。
(二)Peer Routing
libP2P定义了routing 接口,目前有2个实现,分别是KAD routing 和 MDNS routing, 扩展很容易, 只要按照接口实现相应的方法即可。
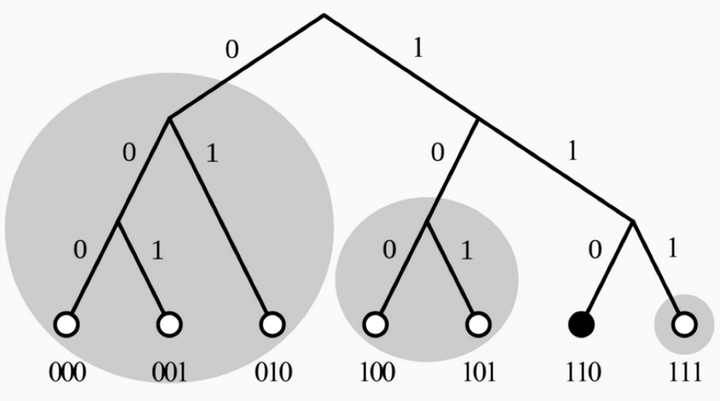
ipfs 中的节点路由表是通过维护多个K-BUCKET来实现的, 每次新增节点, 会计算节点ID 和自身节点ID 之间的common prefix, 根据这个公共前缀把节点加到对应的KBUCKET 中, KBUCKET 最大值为20, 当超出时,再进行拆分。
更新路由表的流程如下:
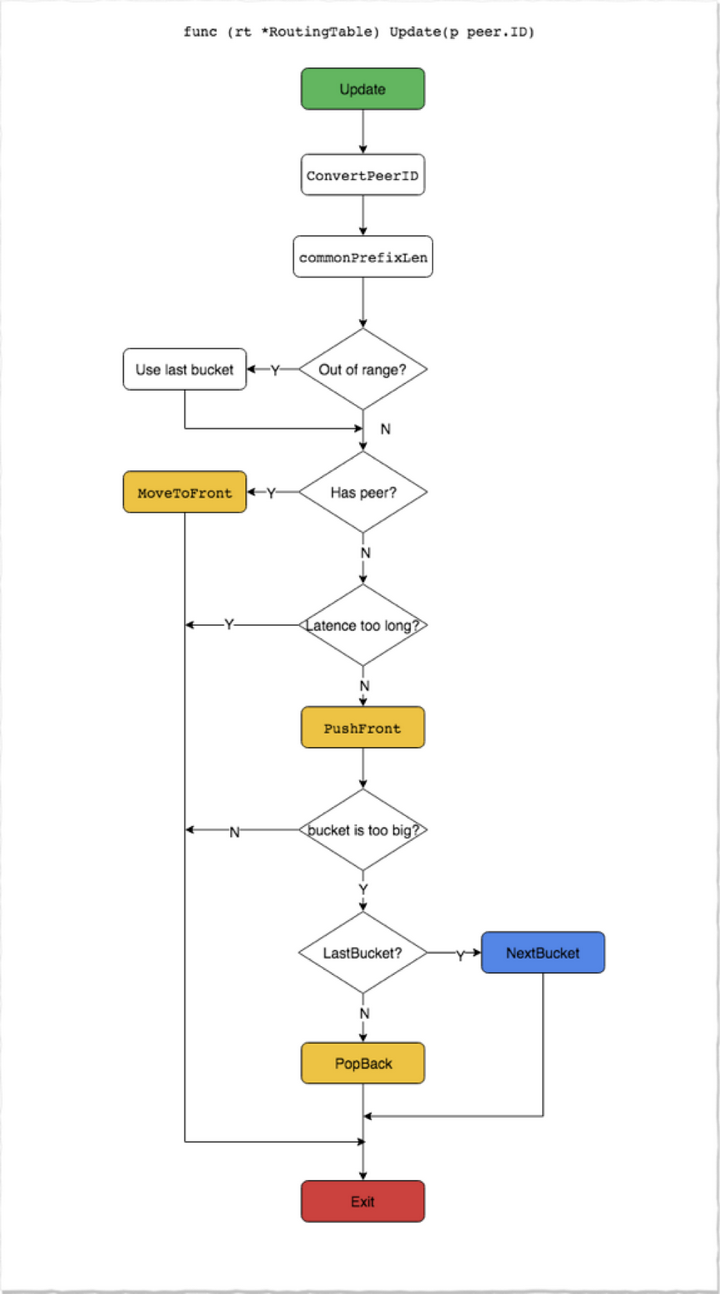
除了KAD routing 之外, IPFS 也实现了MDNS routing, 主要用来在局域网内发现节点, 这个功能相对比较独立, 由于用到了多播地址, 在一些公有云部署环境中可能无法工作。
(三)Swarm(传输和连接)
swarm 定义了以下接口:
- transport 网络传输层的接口
- connection 处理网络连接的接口
- stream multiplex 同一connection 复用多个stream的接口
下面我们重点看下是如何动态协商stream protocol 的,整个流程如下:
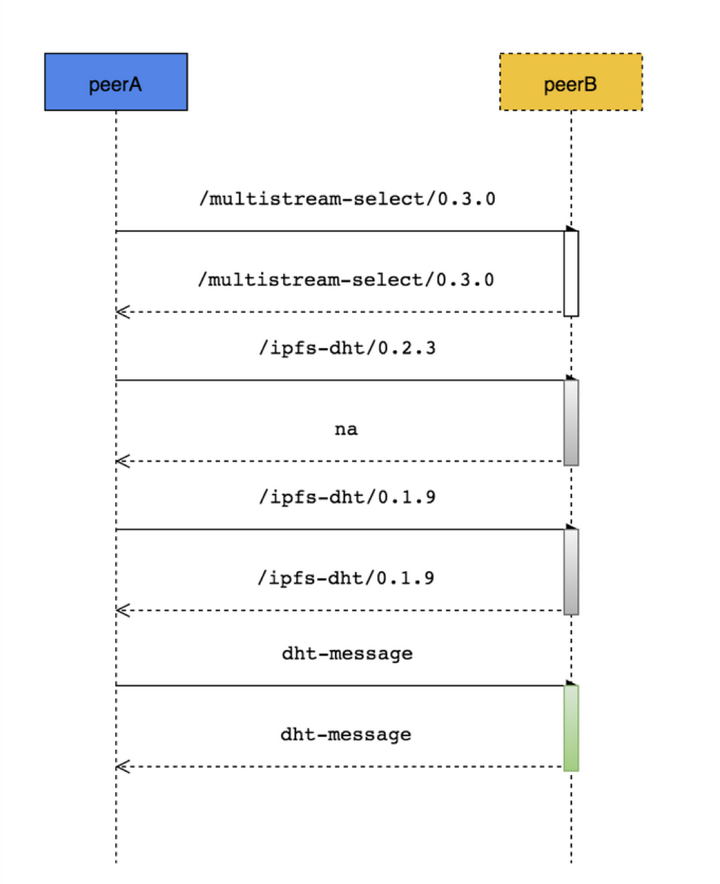
- 默认先通过multistream-select 完成握手
- 发起方尝试使用某个协议, 接收方如果不接受, 再尝试其他协议, 直到找到双方都支持的协议或者协商失败。
另外为了提高协商效率, 也提供了一个ls 消息, 用来查询目标节点支持的全部协议。
(四)Distributed Record Store
record 表示一个记录, 可以用来存储一个键值对,比如ipns name publish 就是发布一个objectId 绑定指定 node id 的record 到ipfs 网络中, 这样通过ipns 寻址时就会查找对应的record, 再解析到objectId, 实现寻址的功能。
(五)Discovery
目前系统支持3种发现方式, 分别是:
- bootstrap 通过配置的启动节点发现其他的节点
- random walk 通过查询随机生成的peerID, 从而发现新的节点
- mdns 通过multicast 发现局域网内的节点
最后总结一下源代码中的逻辑模块:
从下到上分为5个层次:
- 最底层为传输层, 主要封装各种协议, 比如TCP,SCTP, BLE, TOR 等网络协议
- 传输层上面封装了连接层,实现连接管理和通知等功能
- 连接层上面是stream 层, 实现了stream的多路复用
- stream层上面是路由层
- 最上层是discovery, messaging以及record store 等
四、总结
本文从定义数据和传输数据的角度分别介绍了IPFS的2个主要模块IPLD 和 libP2P:
- IPLD 主要用来定义数据, 给数据建模
- libP2P 解决数据传输问题
这两部分相辅相成, 虽然都源自于IPFS项目,但是也可以独立使用在其他项目中。
IPFS的远景目标就是替换现在浏览器使用的 HTTP 协议, 目前项目还在迭代开发中, 一些功能也在不断完善。为了解决数据的持久化问题, 引入了filecoin 激励机制, 通过token激励,让更多的节点加入到网络中来,从而提供更稳定的服务。