1. 进程标识符
在前面进程描述一章节里已经介绍过进程的两个基本标识符pid和ppid,现在将详细介绍进程的其他标识符。每个进程都有非负的整形表示唯一的进程ID。一个进程终止后,其进程ID就可以再次使用了。如下是一个典型进程的ID及其类型和功能。
进程名:swapper (交换进程),进程ID:0,类型:系统进程,作用:它是内核的一部分,不执行磁盘上的程序,是调度进程。
进程名:init(init进程),进程ID:1,类型:用户进程 ,作用:永远不会终止,启动系统,读取系统初始化的文件。
进程名:pagedaemon(页精灵进程),进程ID:2 ,类型:系统进程,作用:虚存系统的请页操作。
除了进程ID,每个进程还有一些其他的标识符。下列函数返回这些标识符:
1 #include <sys/types.h> 2 #include <unistd.h> 3 pid_t getpid(void); //返回值:调用进程的进程ID 4 pid_t getppid(void); //返回值:调用进程的父进程ID 5 uid_t getuid(void); //返回值:调用进程的实际用户ID 6 uid_t geteuid(void); //返回值:调用进程的有效用户ID 7 gid_t getgid(void); //返回值:调用进程的实际组ID 8 gid_t getegid(void); //返回值:调用进程的有效组ID
以上6个函数,如果执行成功,则返回对应的ID值;失败,则返回-1。除了进程ID和父进程ID这两个值不能够更改以外,其他的4个ID值在适当的条件下可以被更改。下面的示例程序用于获取当前进程的6个ID值并打印出来。我们通过代码来实际看看:
1 #include <stdio.h> 2 #include <unistd.h> 3 #include <errno.h> 4 #include <stdlib.h> 5 int main() 6 { 7 uid_t uid; 8 uid_t euid; 9 pid_t pid; 10 pid_t ppid; 11 pid = fork(); 12 if(pid < 0) 13 { 14 printf("%d ",errno); 15 exit(2); 16 } 17 else if(pid == 0){ //child 18 uid = getuid(); 19 euid = geteuid(); 20 printf("child -> pid: %d, ppid : %d ,uid : %d, euid : %d ",getpid(),getppid(),uid, euid); 21 exit(0); 22 } 23 else{ 24 uid = getuid(); 25 euid = geteuid(); 26 printf("father -> pid: %d, ppid : %d ,uid : %d, euid : %d ",getpid(),getppid(),uid, euid); 27 sleep(2); 28 } 29 return 0; 30 }
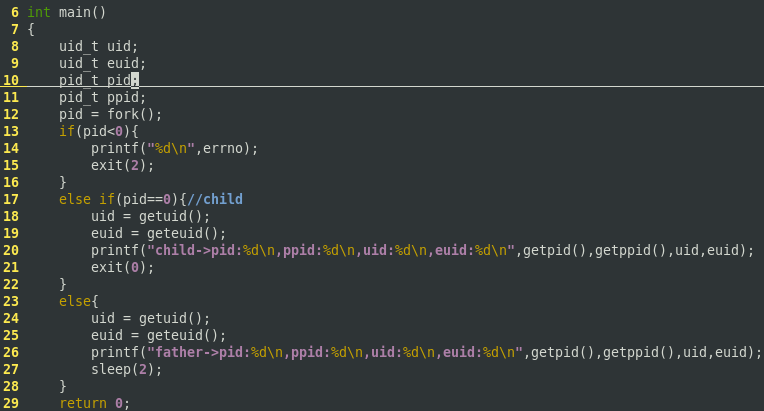 程序运行效果如下:
程序运行效果如下:

2. 实际用户和有效用户
(1)实际用户ID和实际用户组ID:标识我是谁。也就是登录用户的uid和gid,比如我的Linux以admin登录,在Linux运行的所有的命令的实际用户ID都是admin的uid,实际用户组ID都是admin的gid(可以用id命令查看)。

(2)有效用户ID和有效用户组ID:进程用来决定我们对资源的访问权限。一般情况下,有效用户ID等于实际用户ID,有效用户组ID等于实际用户组ID。当设置-用户-ID(SUID)位设置,则有效用户ID等于文件的所有者的uid,而不是实际用户ID;同样,如果设置了设置-用户组-ID(SGID)位,则有效用户组ID等于文件所有者的gid,而不是实际用户组ID。其中, 实际用户ID/实际组ID标识进程究竟是谁(即是进程在系统的唯一标识),有效用户ID/有效组ID/附加组ID决定了进程的访问权限。
suid (chmod u+s file)只能应用在可执行文件上,允许任意用户在执行文件时以文件拥有者的身份执行;
sgid (chmod g+s file)只能应用在可执行文件上,使任意用户在执行可执行文件时,将以拥有组成员的身份执行;
说明: suid 和 sgid 表示在bin在运行时,会具有拥有者的权限,换句话说,只要运行该可执行程序,那么运行者也是有权限对拥有者的所有相关文件(可执行程序会读写)
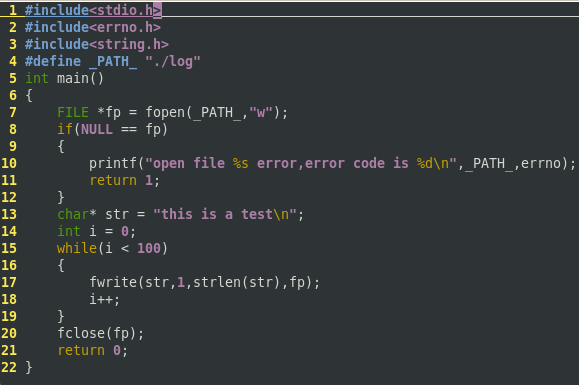
进行操作。验证代码:
1 #include <stdio.h> 2 #include <errno.h> 3 #include <string.h> 4 #define _PATH_ "./log" 5 int main() 6 { 7 FILE *fp = fopen(_PATH_, "w"); 8 if( NULL == fp ){ 9 printf("open file is error, error code is : %d ",_PATH_, errno); 10 return 1; 11 } 12 char *str = "this is a test "; 13 int i=0; 14 while( i<100 ){ 15 fwrite(str, 1, strlen(str),fp); 16 i++; 17 } 18 fclose(fp); 19 return 0; 20 }
3. 进程创建
3.1 fork()函数创建进程
前面进程描述一节里简单介绍过进程的创建,分别通过fork()和execve()函数创建子进程,这里再进一步深入探讨有关fork()创建子进程的问题。一个现有进程可以调用fork创建一个新进程。返回值: 子进程中返回0,父进程中返回子进程ID,出错返回-1。如下:
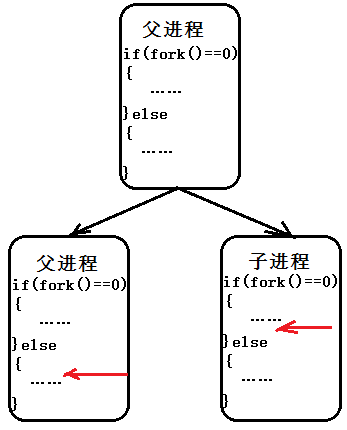
子进程是父进程的副本。例如:子进程获得父进程数据空间、堆和栈的副本(主要是数据结构的副本)。 父子进程不共享这些存储空间部分。父子进程共享正文段。由于fork之后经常归属exec,所以现在很多实现并不执行一个父进程数据段、栈和堆的完全复制。作为替代,使用了写时复制(Copy-On-Write)技术。这些区域由父子进程共享,而且内核将他们的访问权限改变为只读的。如果父子进程中的任意个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本。
下面的程序演示了fork函数,从中可以看出子进程对变量所作的改变并不去影响父进程中该变量的值。
1 #include <unistd.h> 2 #include <stdio.h> 3 int glob = 6; /* externalvariable in initialized data */ 4 char buf[] = "a write to stdout "; 5 int main(void) 6 { 7 int var; /* automatic variable on the stack */ 8 pid_t pid; 9 var = 88; 10 if (write(STDOUT_FILENO, buf, sizeof(buf)-1) != sizeof(buf)-1) 11 perror("write error"); 12 printf("before fork "); /* we don't flush stdout */ 13 if ((pid = fork()) < 0) 14 { 15 perror("fork error"); 16 } 17 else if (pid == 0) { /* child */ 18 glob++; /* modifyvariables */ 19 var++; 20 } 21 else { 22 sleep(2); /* parent*/ 23 } 24 printf("pid = %d, glob = %d, var = %d ", getpid(), glob,var); 25 exit(0); 26 }
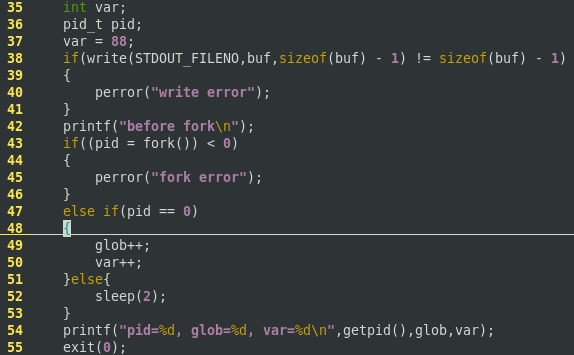
执行及输出结果:

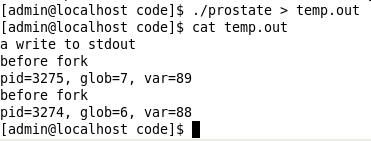
一般来说fork之后父进程和子进程的执行顺序是不确定的,这取决于内核的调度算法。在上面的程序中,父进程是自己休眠2秒钟,以使子进程先执行。程序中fork与I/O函数之间的关系: write是不带缓冲 的(http://blog.sina.com.cn/s/blog_6fb9dec201017tk3.html),因为在fork之前调用write,所以其数据只写到标准输出一次。标准I/O是缓冲的,如果标准输出到终端设备,则它是行缓冲,否则它是全缓冲。当以交互方式运行该程序时,只得到printf输出的行一次, 因为标准输出到终端缓冲区由换行符冲洗。但将标准输出重定向到一个文件时,由于缓冲区是全缓冲,遇到换行符不输出,当调用fork时,其printf的数据仍然在缓冲区中,该数据将被复制到子进程中,该缓冲区也被复制到子进程中。于是父子进程的都有了带改行内容的标准I/O缓冲区,所以每个进程终止时,会冲洗其缓冲区中的数据,得到第一个printf输出两次。
3.2 fork的文件共享特性
fork的一个特性是父进程的所有打开文件描述符都被复制到子进程中。父子进程每个相同的文件描述符共享一个文件表项。假设一个进程有三个不同的打开文件,在从fork返回时,我们有如下所示结构:
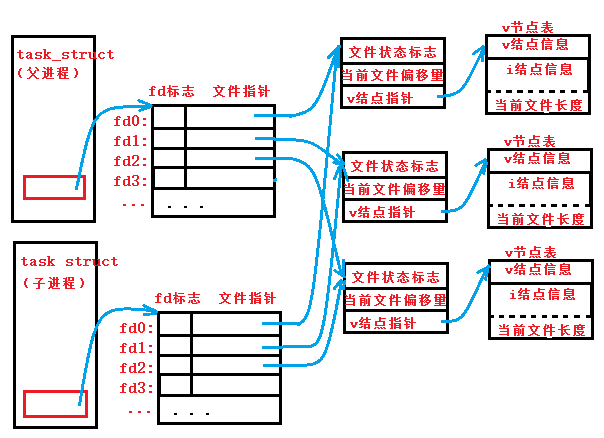
在fork之后处理的文件描述符有两种常见的情况:
1. 父进程等待子进程完成。在这种情况下,父进程不需对其描述符做任何处理。当子进程终止后,子进程对文件偏移量的修改会更新到父进程。
2. 父子进程各各执行不同的程序段。(即子进程exec之后)这种情况下,在fork之后,父子进程各自关闭他们不需要使用的文件描述符,这样就不会干扰对方使用文件描述符。 这种方法在联络服务进程中经常使用。
父子进程之间的区别:
1. fork的返回值;
2. 进程ID不同;
3. 具有不同的父进程ID;
4. 子进程的tms_utime、 tms_stime、 tms_cutime及tms_ustime均被设置为0;
5. 父进程设置的文件锁不会被子进程继承;
6. 子进程的未处理闹钟被清除;
7. 子进程的未处理信号集被设置为空集。
fork有下面两种方法:
1. 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
2. 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因:
1. 系统中有太多的进程;
2. 实际用户的进程数超过了限制。
3.3 vfork函数
vfork用于创建一个新进程,且该新进程的目的是exec一个新程序。 vfork与fork都创建一个新进程,但vfork不将新进程的地址空间复制到子进程中,因为子进程会立即调用exec,于是不会存访问该地址空间。在子进程调用exec或exit之前,它在父进程的空间中运行,也就是说会更改父进程的数据段、栈和堆。 vfork和fork另一区别在于: vfork保证子进程先运行,在它调用exec或exit(这里不能使用return,原因见http://coolshell.cn/articles/12103.html)之后父进程才可能被调度运用。
下面是vfork的使用程序:
1 #include <stdio.h> 2 #include <string.h> 3 #include <unistd.h> 4 #include <stdlib.h> 5 int g_val = 0; 6 void fun() 7 { 8 printf("child exit "); 9 } 10 int main() 11 { 12 int _val = 0; 13 pid_t id = vfork(); 14 if( id < 0 ){ 15 exit(1); 16 } 17 else if( id == 0 ){ //child 18 atexit(fun); 19 printf("this is child process. "); 20 // ++g_val; //验证第⼀点不同 21 // ++_val; 22 sleep(3); 23 exit(0); 24 } 25 else{ 26 printf("this is father process "); 27 //printf(“father exit, g_val = %d, _val = %d ",g_val, _val); 28 } 29 return 0; 30 }
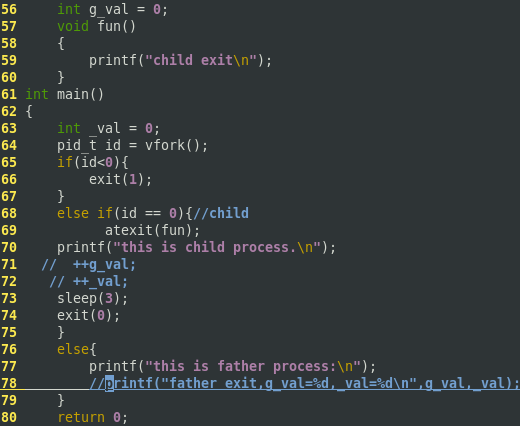

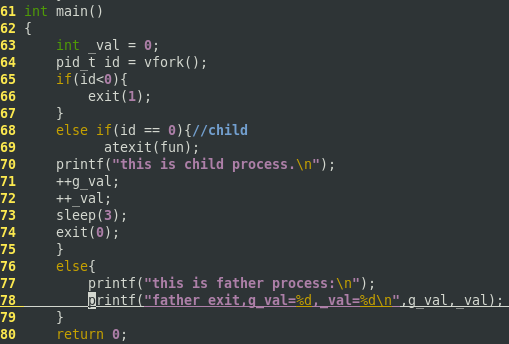

可见子进程直接改变了父进程的变量值,因为子进程在父进程的地址空间中运行。