说明
本篇文章整个操作都是在root账号下进行,所有操作步骤完成后,可以根据实际的需求,更改目录权限。
整个操作的目的有两个:
- 安装snappy包,安装完成后所在路径是/usr/local/lib/
- 安装hadoop依赖的snappy包,安装完成后所在路径是 $HADOOP_HOME/lib/native
然后将上面两个拷贝分发到所有节点,其中第2个在安装hadoop时会拷贝,通常第一个分发拷贝操作可能会遗忘。
1. 安装编译环境
1.1 安装C++编译器
yum install -y automake autoconf gcc-c++ libedit libtool openssl-devel ncurses-devel
1.2 安装cmake
注意版本需要大于3
查看cmake的版本,如果是2.8.12.2,则需要卸载掉,单独安装。
cmake --version
卸载cmake
yum remove cmake -y
重新安装cmake3.9版本
wget https://cmake.org/files/v3.9/cmake-3.9.2.tar.gz
tar zxvf cmake-3.9.2.tar.gz
cd cmake-3.9.2
./configure
make & make install
1.3 安装protobuf-2.5.0
版本必须是该版本
tar zxvf protobuf-2.5.0.tar.gz
cd protobuf-2.5.0
./configure
make & make install
安装完成后,退出重新登录。
1.4 安装maven
yum install wget -y
wget http://mirror.bit.edu.cn/apache/maven/maven-3/3.5.4/binaries/apache-maven-3.5.4-bin.tar.gz
tar xvf apache-maven-3.5.4-bin.tar.gz
修改环境变量/etc/profile
export MAVEN_HOME=/opt/local/maven
export PATH=$PATH:$MAVEN_HOME/bin
修改setting文件仓库位置:
<localRepository>/opt/local/maven/repo</localRepository>
修改镜像服务器地址:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
2. 安装snappy
2.1 安装snappy
wget https://src.fedoraproject.org/repo/pkgs/snappy/snappy-1.1.3.tar.gz/7358c82f133dc77798e4c2062a749b73/snappy-1.1.3.tar.gz
tar xvf snappy-1.1.3.tar.gz
cd snappy-1.1.3
./configure
make
make install
#卸载命令 make uninstall
注意:安装完成后,在/usr/local/lib/目录下生成对应的snappy文件
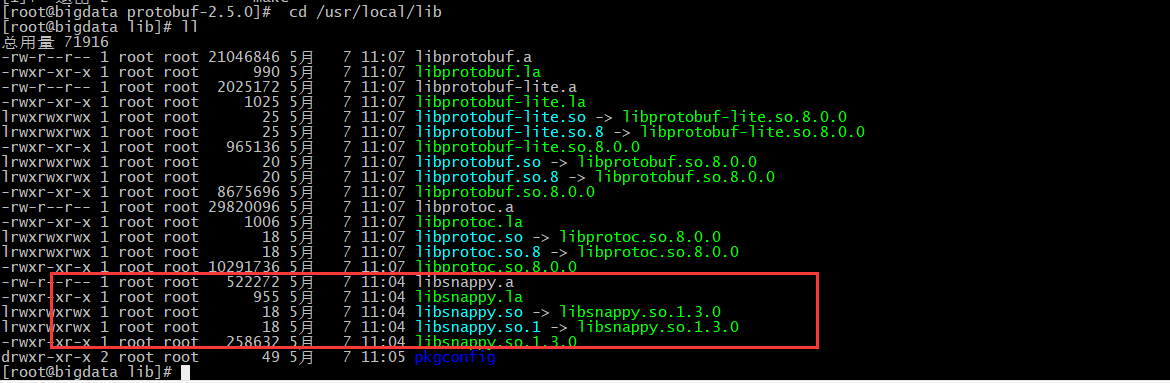
将/usr/local/lib 目录下所有文件拷贝到 其他节点相同目录下。
2.2 编译hadoop-snappy(未做似乎不影响)
wget下载,或者直接从git地址https://github.com/electrum/hadoop-snappy 手工选择download ZIP包。
wget https://github.com/electrum/hadoop-snappy/archive/refs/heads/master.zip
解压缩,编译
yum install unzip
unzip master.zip
cd hadoop-snappy-master
mvn package
一定要先安装好snappy,然后检查在/usr/local/lib/目录下有对应的snappy文件,否则该步骤无法打包成功。
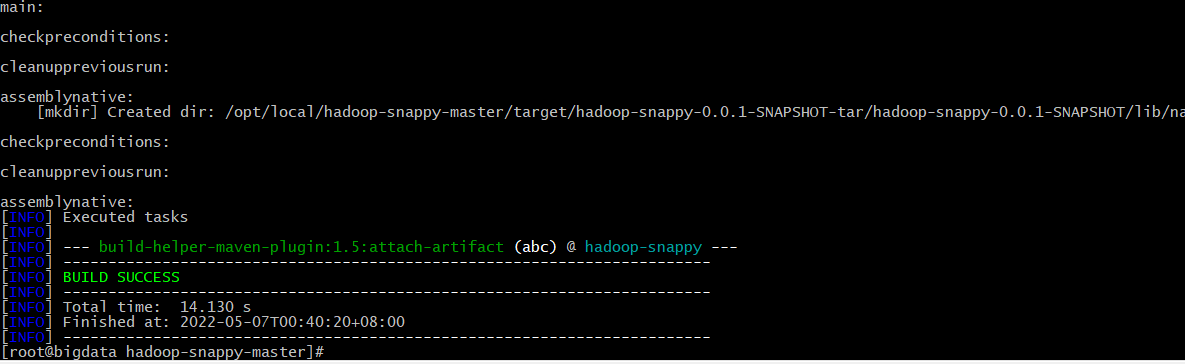
编译成功后,在target文件夹下面如下:
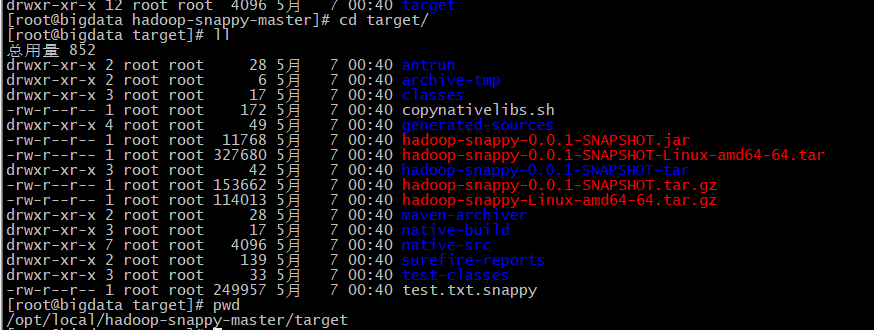
3. hadoop
hadoop编译的目的是为了获取到编译完成后的lib库,编译完成的lib库保存在路径
/opt/local/hadoop-3.1.3-src/hadoop-dist/target/hadoop-3.1.3/lib/native
然后将lib库拷贝到对应版本已安装的节点上。
拷贝后,需要重启节点。
3.1 编译hadoop
wget http://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3-src.tar.gz
tar -zxvf hadoop-3.1.3-src.tar.gz
cd hadoop-3.1.3-src
在hadoop-3.1.3-src目录里新建文件compile.sh,填写以下内容,并修改权限755。
vim compile.sh
export MAVEN_OPTS="-Xms256m -Xmx512m"
mvn clean package -Pdist,native -DskipTests -Dtar -rf :hadoop-common -Drequire.snappy -X
这种编译是将snappy包直接编译到一起,编译过程大于20分钟左右。
chmod 755 compile.sh
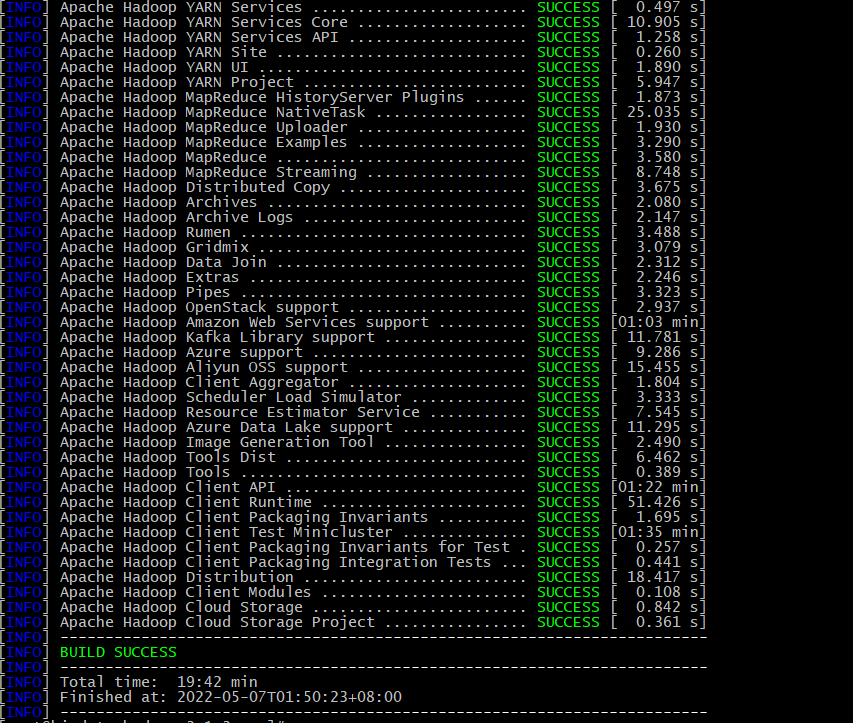
./compile.sh
编译成功如下:
网上还有一段增加其他依赖的编译命令如下,可以自行尝试。
#!/bin/bash
mvn package -Pdist,native,nexus -DskipTests=true -Dmaven.javadoc.skip=true -Dtar -Dcontainer-executor.conf.dir=/etc/hadoop/ -Drequire.snappy -Dbundle.snappy -Dsnappy.lib=/opt/develop/snappy/lib -Dsnappy.prefix=/opt/develop/snappy -Drequire.openssl -Dbundle.openssl -Dopenssl.lib=/opt/develop/openssl/lib -Dopenssl.prefix=/opt/develop/openssl -Drequire.bzip2=true -Dzstd.prefix=/opt/develop/zstd -Dzstd.lib=/opt/develop/zstd/lib -Dbundle.zstd -Drequire.zstd -Disal.prefix=/opt/develop/isal -Drequire.isal=true -Dbundle.isal -Disal.lib=/opt/develop/isal/lib
3.2 修改hadoop配置文件
3.2.1 修改core-site.xml
<!-- 用于压缩/解压的CompressionCodec列表,多种算法使用逗号分隔的类名 -->
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
3.2.2 修改yarn-site.xml
<!-- 压缩MapReduce作业的输出 -->
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<!-- 指定压缩算法的类名 -->
<property>
<name>mapred.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
4. 拷贝文件
4.1 分发snappy文件
如果2.1没做拷贝,就将/usr/local/lib 目录下所有文件拷贝到 其他节点相同目录下
scp -r /usr/local/lib/* hadoop100:/usr/local/lib/
4.2 分发hadoop lib库
将hadoop目录中lib/native文件夹复制拷贝到 /opt/local/hbase/lib/目录下,需要所有节点都拷贝。
scp -r $HADOOP_HOME/lib/native hadoop100:/opt/local/hbase/lib/
5. 修改hbase配置
修改hbase-env.sh,在末尾添加以下配置:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native/:/usr/local/lib/
export HBASE_LIBRARY_PATH=$HBASE_LIBRARY_PATH:$HBASE_HOME/lib/native/:/usr/local/lib/
export CLASSPATH=$CLASSPATH:$HBASE_LIBRARY_PATH
修改完,在所有节点同步该文件。
6. Hbase测试
create 'test2',{NAME=>'f1',COMPRESSION => 'gz'}
create 'test3',{NAME=>'f1',COMPRESSION => 'SNAPPY'}