Redis持久化
1.RDB和AOF优缺点
RDB: 快照,把当前内存里的状态快照到磁盘上
优点: 压缩格式/恢复速度快
缺点: 可能会丢失数据
AOF: 类似于mysql的binlog,重写,、每次操作都写一次/1秒写一次
优点: 安全,有可能会丢失1秒的数据
缺点: 文件比较大,恢复速度慢
持久化RDB
1.配置
[root@db01 redis_6379]# vim /opt/redis_6379/conf/redis_6379.conf
save 900 1
save 300 10
save 60 10000
背景:
1.配置文件里设置了数据目录和持久化文件名
现象:
1.直接关闭重启,数据丢失
2.执行了bgsave之后。数据目录持久化了,重启数据不丢失
背景:
1.配置文件设置了数据目录和持久化文件名
2.设置了触发条件
现象:
1.触发条件都不满足,但是重启之后数据还在,持久化了
结论:
1.如果不设定触发条件,关闭redis不会持久化
2.如果设定了触发条件,即使触发持久化,但是关闭的时候,redis会替你执行一次bgsave
2.结论:
1.执行shutdown的时候,内部会自动执行bgsave,然后再执行shutdown
2.pkill 会持久化
kill 会持久化
killall 会持久化
shutdown 会持久化.会触发bgsave持久化
kill -9 不会持久化
3.恢复的时候,rdb文件名称要和配置文件里写的一样
4.如果没有配置save参数,执行shutdown不会自动bgsave持久化
5.如果没有配置save参数,可以手动执行bgsave触发持久化保存
常用命令:
ll /data/redis_6379/
cat /opt/redis_6379/conf/redis_6379.conf
vim /opt/redis_6379/conf/redis_6379.conf
pkill redis
redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
redis-cli -h db01
redis-cli -h db01 shutdown
bash for.sh
3.配置AOF
appendfilename "redis_6379.aof"
appendonly yes
appendfsync everysec
3.实验
设置数据
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3
OK
#关机
[root@db01 redis_6379]# redis-cli
127.0.0.1:6379> SHUTDOWN
not connected>
#开机
[root@db01 redis_6379]# redis-server /opt/redis_6379/conf/redis_6379.conf
#查看
[root@db01 redis_6379]# ll
total 4
-rw-r--r-- 1 root root 102 Dec 25 15:17 redis_6379.rdb
[root@db01 redis_6379]# redis-cli
127.0.0.1:6379> KEYS *
1) "k1"
2) "k2"
3) "k3"
127.0.0.1:6379>
实验:
如果aof和rdb文件同时存在,redis会如何读取:
实验步骤:
1.插入一条数据
aof: 有记录
rdb: 没有记录
2.复制到其他地方
3.把redis停掉
4.清空数据目录
5.把数据文件拷贝过来
aof: 有记录
rdb: 没有记录
6.启动redis
7.测试,如果有新插入的数据,就表示读取的是aof,如果没有,就表示读取的是rdb
实验结论:
如果2种数据格式都存在,优先读取aof
官方文档:
https://redis.io/topics/persistence
如何选择:
好的,那我该怎么用?
通常的指示是,如果您希望获得与PostgreSQL可以提供的功能相当的数据安全性,则应同时使用两种持久性方法。
如果您非常关心数据,但是在灾难情况下仍然可以承受几分钟的数据丢失,则可以仅使用RDB。
有很多用户单独使用AOF,但我们不建议这样做,因为不时拥有RDB快照对于进行数据库备份,加快重启速度以及AOF引擎中存在错误是一个好主意。
注意:由于所有这些原因,我们将来可能会最终将AOF和RDB统一为一个持久性模型(长期计划)。
以下各节将说明有关这两个持久性模型的更多详细信息。
持久化AOF
开启AOF功能需要设置配置:
appendonly yes,默认不开启.AOF文件名通过appendfilename配置设置,默认文件名是appendonly.aof. 保存路径通RDB持久化方式一致,通过dir配置指定.
1.AOF的工作流程
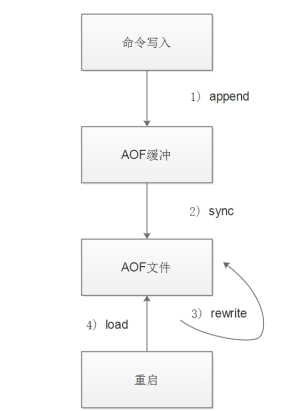
1.所有写入命令会追加到aof_buf(缓冲区)中.
2.AOF缓冲区根据对应的策略向硬盘做同步操作
3.随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的.
4.当Redis服务重启时,可以加载AOF文件进行数据恢复.
2.配置
[root@db01 redis_6379]# vim /opt/redis_6379/conf/redis_6379.conf
appendfilename "redis_6379.aof"
appendonly yes
appendfsync everysec
3.实验
#开机
[root@db01 redis_6379]# redis-server /opt/redis_6379/conf/redis_6379.conf
[root@db01 redis_6379]# ll
total 4
-rw-r--r-- 1 root root 0 Dec 25 16:05 redis_6379.aof
-rw-r--r-- 1 root root 102 Dec 25 16:04 redis_6379.rdb
#插入数据
[root@db01 redis_6379]# redis-cli
127.0.0.1:6379> KEYS *
(empty list or set)
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379>
#查看
[root@db01 redis_6379]# ll
total 8
-rw-r--r-- 1 root root 85 Dec 25 16:07 redis_6379.aof
-rw-r--r-- 1 root root 102 Dec 25 16:04 redis_6379.rdb
#再次插入
[root@db01 redis_6379]# redis-cli set k4 v4
OK
#再次查看发现.aof 有变化 而.rdb没有变化
[root@db01 redis_6379]# ll
total 8
-rw-r--r-- 1 root root 114 Dec 25 16:09 redis_6379.aof
-rw-r--r-- 1 root root 102 Dec 25 16:04 redis_6379.rdb
#for循环插入数据
for i in {1..10000}; do redis-cli set k_${i} v_${i};echo ${i};done
4.结论
.aof 是实时记录的
.rdb 是关机或者pkill 做的一个备份
测试,如果有新插入的数据,就表示读取的是aof,如果没有,就表示读取的是rdb
实验结论:
如果2种数据格式都存在,优先读取aof
官方解释:
https://redis.io/topics/persistence
安全认证
#配置密码
[root@db01 redis_6379]# vim /opt/redis_6379/conf/redis_6379.conf
requirepass 123456
[root@db01 redis_6379]# pkill redis
[root@db01 redis_6379]# redis-server /opt/redis_6379/conf/redis_6379.conf
#登录发现需要认证
[root@db01 redis_6379]# redis-cli
127.0.0.1:6379> KEYS *
(error) NOAUTH Authentication required.
#输入密码登录
[root@db01 redis_6379]# redis-cli -a 123456
127.0.0.1:6379> get k1
"v1"
禁用危险命令
配置文件里添加禁用危险命令的参数
[root@db01 redis_6379]# vim /opt/redis_6379/conf/redis_6379.conf
rename-command KEYS ""
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
#关机
[root@db01 redis_6379]# pkill redis
#启动
[root@db01 redis_6379]# redis-server /opt/redis_6379/conf/redis_6379.conf
[root@db01 redis_6379]# redis-cli -a 123456
#查看
127.0.0.1:6379> KEYS *
(error) ERR unknown command 'KEYS'
设置一个别名
[root@db01 redis_6379]# vim /opt/redis_6379/conf/redis_6379.conf
rename-command KEYS "AA"
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
就是 输入 AA*的时候,才可以看到keys *的所有内容
主从复制
快速创建第二台redis节点命令:
[root@db01 redis_6379]# yum install -y rsync
利用rsync 传到对端
[root@db01 redis_6379]# rsync -avz /opt/* db02:/opt/
[root@db01 redis_6379]# rsync -avz /data db02:/
db02 操作
[root@db02 ~]# cd /opt/redis
[root@db02 redis]# make install
修改端口
[root@db02 redis]# sed -i 's#51#52#g' /opt/redis_6379/conf/redis_6379.conf
[root@db02 redis]# rm -rf /data/redis_6379/*
启动
[root@db02 redis]# redis-server /opt/redis_6379/conf/redis_6379.conf
进入查看
[root@db02 redis]# redis-cli
127.0.0.1:6379> KEYS *
(empty list or set)
开始做主从
#临时生效
127.0.0.1:6379> SLAVEOF 10.0.0.51 6379
ok
127.0.0.1:6379> get k1
"v1"
#永久生效 将SLAVEOF 10.0.0.51 6379 写入配置文件中
注意:做主从的时候,从的配置文件一定要跟主的一模一样,要不然做不了
主的配置文件
[root@db01 redis_6379]# !v
vim /opt/redis_6379/conf/redis_6379.conf
### 监听端口
port 6379
### pid文件和log文件的保存地址
pidfile /opt/redis_6379/pid/redis_6379.pid
logfile /opt/redis_6379/logs/redis_6379.log
### 设置数据库的数量,默认数据库为0
databases 16
### 指定本地持久化文件的文件名,默认是dump.rdb
dbfilename redis_6379.rdb
### 本地数据库的目录
dir /data/redis_6379
#save 900 1
#save 300 10
#save 60 10000
#
#appendfilename "redis_6379.aof"
#appendonly yes
#appendfsync everysec
#requirepass 123456
通过看日志来分析主从复制的原理
[root@db02 ~]# cat /opt/redis_6379/logs/redis_6379.log
从节点日志
9744:S 25 Dec 19:03:53.501 * Connecting to MASTER 10.0.0.51:6379
9744:S 25 Dec 19:03:53.502 * MASTER <-> SLAVE sync started
9744:S 25 Dec 19:03:53.502 * Non blocking connect for SYNC fired the event.
9744:S 25 Dec 19:03:53.502 * Master replied to PING, replication can continue...
9744:S 25 Dec 19:03:53.503 * Partial resynchronization not possible (no cached master)
9744:S 25 Dec 19:03:53.505 * Full resync from master: cbd36d5d4638a5433f3e6bbaf1e402fe8abb5ee4:1
#从节点接收主节点发送的数据,然后载入内存:
9744:S 25 Dec 19:03:53.602 * MASTER <-> SLAVE sync: receiving 147898 bytes from master
9744:S 25 Dec 19:03:53.604 * MASTER <-> SLAVE sync: Flushing old data
9744:S 25 Dec 19:03:53.604 * MASTER <-> SLAVE sync: Loading DB in memory
9744:S 25 Dec 19:03:53.616 * MASTER <-> SLAVE sync: Finished with success
======================================================================================
主节点日志
[root@db01 ~]# cat /opt/redis_6379/logs/redis_6379.log
33819:M 25 Dec 19:02:56.917 * DB loaded from disk: 0.013 seconds
#主节点收到请求之后开始持久化保存数据:
33819:M 25 Dec 19:02:56.917 * The server is now ready to accept connections on port 6379
33819:M 25 Dec 19:03:53.815 * Slave 10.0.0.52:6379 asks for synchronization
33819:M 25 Dec 19:03:53.815 * Full resync requested by slave 10.0.0.52:6379
33819:M 25 Dec 19:03:53.815 * Starting BGSAVE for SYNC with target: disk
33819:M 25 Dec 19:03:53.815 * Background saving started by pid 33826
33826:C 25 Dec 19:03:53.830 * DB saved on disk
33826:C 25 Dec 19:03:53.831 * RDB: 8 MB of memory used by copy-on-write
#主节点收到从节点同步完成的消息
33819:M 25 Dec 19:03:53.913 * Background saving terminated with success
33819:M 25 Dec 19:03:53.915 * Synchronization with slave 10.0.0.52:6379 succeeded
主从复制流程:
1.从节点发送同步请求到主节点
2.主节点接收到从节点的请求之后,做了如下操作
- 立即执行bgsave将当前内存里的数据持久化到磁盘上
- 持久化完成之后,将rdb文件发送给从节点
3.从节点从主节点接收到rdb文件之后,做了如下操作
- 清空自己的数据
- 载入从主节点接收的rdb文件到自己的内存里
4.后面的操作就是和主节点实时的了
取消主从复制
SLAVEOF no one
查看取消主从复制日志
[root@db02 ~]# cat /opt/redis_6379/logs/redis_6379.log
9744:M 25 Dec 19:25:12.655 # Connection with master lost.
#缓存断开连接的主状态
9744:M 25 Dec 19:25:12.655 * Caching the disconnected master state.
#丢弃以前缓存的主状态。
9744:M 25 Dec 19:25:12.655 * Discarding previously cached master state.
9744:M 25 Dec 19:25:12.656 * MASTER MODE enabled (user request from 'id=5 addr=127.0.0.1:53702 fd=6 name= age=3 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=slaveof')
[root@db01 ~]# cat /opt/redis_6379/logs/redis_6379.log
#连接从10.0.0.52:6379丢失。
33819:M 25 Dec 19:25:12.967 # Connection with slave 10.0.0.52:6379 lost.
注意!!!
1.从节点只读不可写
2.从节点不会自动故障转移,它会一直同步主
10.0.1.52:6379> set k1 v1
(error) READONLY You can't write against a read only slave.
3.主从复制故障转移需要人工介入
- 修改代码指向REDIS的IP地址
- 从节点需要执行SLAVEOF no one
注意!!!
1.从节点会清空自己原有的数据,如果同步的对象写错了,就会导致数据丢失
安全的操作:
1.无论是同步,无论是主节点还是从节点
2.先备份一下数据
