1. 本周学习总结
1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容。

1.2 选做:收集你认为有用的代码片段
- 遍历Map的方法:
for(Map.Entry<String, ArrayList<Integer>> entry:map.entrySet())
System.out.println(entry.getKey()+"="+entry.getValue());
- forEach循环遍历的方法:
for(E element : 某个Collection集合){
do sth with Collection;
}
- Map 转为List的方法:
List<Entry<String,Integer>> list = new ArrayList<Entry<String,Integer>>(amount.entrySet());
- 过滤方法:
integerList.stream().filter(Lambda表达式).collect(Collector.toList()).forEach(System.out::println);
- 返回给定Collection的最大值方法:
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll){
return Collections.max(coll);
}
2. 书面作业
本次作业题集集合
2.1 List中指定元素的删除(题集题目)
2.1.1 实验总结。并回答:列举至少2种在List中删除元素的方法。
实验总结:
- 表示单个或者多个空格的方法有
String [] arr = line.split(" +");String []arr=line.split("\s+");s是在split正则表达式中匹配任何空白字符。 - 该实验还让我学会了多种删除List中元素的方法,详见如下截图。
以下是采用迭代器删除列表元素和利用列表本身具有的remove方法删除元素。

2.2 统计文字中的单词数量并按出现次数排序(题集题目)
2.2.1 伪代码(不得复制代码,否则扣分)
- 用HashMap实现每个单词与其数量的映射。
- 将HashMap转为List
- 重写Collections类中的sort方法实现对List的排序。
2.2.2 实验总结
- HashMap中的一些基本方法,
hashmap.contains(Key)判断映射中是否已经包含此键hashmap.get(K)得到键所对应的值hashmap.size()此映射中包含几条键值对 - 将HashMap转为List
List<Entry<String,Integer>> list = new ArrayList<Entry<String,Integer>>(amount.entrySet()); - 重写Collections类中的sort方法
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if(o1.getValue()==o2.getValue())
return o1.getKey().compareTo(o2.getKey());
else return (o2.getValue() - o1.getValue());
}
});
2.3 倒排索引(题集题目)
本题较难,做不出来不要紧。但一定要有自己的思考过程,要有提交结果。
2.3.1 截图你的代码运行结果


2.3.2 伪代码(不得复制代码,否则扣分)
- 使用HashMap实现单词与位置的映射。显然键为
String型,值为ArrayList<Integer>。 - 将HashMap转为List并且输出。(之前的做法,学习了Map的遍历方法后我们可以遍历map来输出键值对)
- 查找条目:如果输入一个单词则直接根据Key查找Value输出;如果输入多个单词的话先找到单词公共出现的位置,然后将公共位置输出。
- 在实现第一步的时候就将每一行的内容添加到一个数组中,方便最后根据位置再输出句子。
2.3.3 实验总结
- 实验还得考虑一种情况,那就是如果一个句子中重复出现一个单词的情况。所以得判断值数组中是否已经包含该行数。

- 将HashMap转为List方法同上一题。遍历map方法如下:
for(Map.Entry<String, ArrayList<Integer>> entry:map.entrySet())
System.out.println(entry.getKey()+"="+entry.getValue());
- 得到多个单词的公共位置,可以以第一个单词的值数组为基础,然后如果其他值数组中不包含某一个就将其remove。最后如果基础数组空了就输出
found 0 results

2.4 Stream与Lambda
编写一个Student类,属性为:
private Long id;
private String name;
private int age;
private Gender gender;//枚举类型
private boolean joinsACM; //是否参加过ACM比赛
创建一集合对象,如List
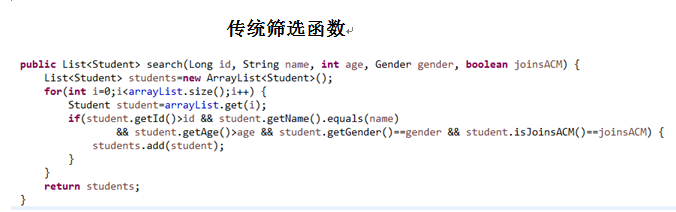
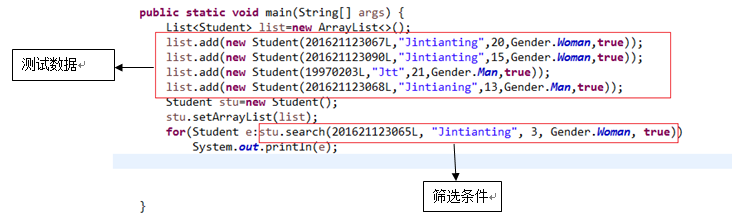
2.4.1 使用传统方法编写一个搜索方法List search(Long id, String name, int age, Gender gender, boolean joinsACM),然后调用该方法将id>某个值,name为某个值, age>某个值, gender为某个值,参加过ACM比赛的学生筛选出来,放入新的集合。在main中调用,然后输出结果。(截图:出现学号、姓名)
以下是使用传统方法将ID>201621123065,姓名为Jintianting,age>3,参加过ACM的女性筛选出来并且输出

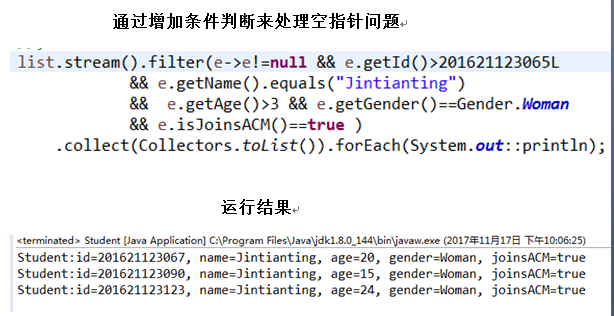
2.4.2 使用java8中的stream(), filter(), collect()编写功能同4.1的代码,并测试(要出现测试数据)。构建测试集合的时候,除了正常的Student对象,再往集合中添加一些null,你编写的方法应该能处理这些null而不是抛出异常。(截图:出现学号)
该题先通过stream()变成流,用filter()过滤,留下符合要求的对象,collect()收集留下的元素,可以以List的方式展示。该题添加null之后会报错说是空指针异常,因为Lambda表达式中调用方法的对象可能为空,那解决这个问题的方法可以是加限定条件,也可以是通过try-catch捕获异常,但是捕获异常优缺点。详见下。
collect是一个终端操作,它接收的参数是将流中的元素累积到汇总结果的各种方式。可以是List,也可以使Set等等。


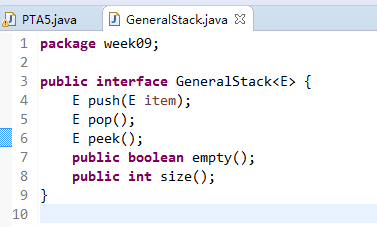
2.5 泛型类:GeneralStack
题集jmu-Java-05-集合之GeneralStack
2.5.1 GeneralStack接口的代码
2.5.2 结合本题与以前作业中的ArrayListIntegerStack相比,说明泛型有什么好处
- 之前作业中ArrayListIntegerStack类中的栈只能存放Integer类型的元素,使用泛型之后栈不在限定为只能存放某种类型的元素。
- 泛型可以避免不安全的强制类型转换,因为栈中的元素类型是自己指定的。
- 使用泛型之后编译阶段就会对类型进行检查,不会在运行时才报错。
2.6. 选做:泛型方法
基础参考文件GenericMain,在此文件上进行修改。
2.6.1 编写方法max,该方法可以返回List中所有元素的最大值。List中的元素必须实现Comparable接口。编写的max方法需使得String max = max(strList)可以运行成功,其中strList为List<String>类型。也能使得Integer maxInt = max(intList);运行成功,其中intList为List<Integer>类型。注意:不得直接调用Collections.max函数。
String ,Integer类型已经实现自比较的Comparable接口
max(Collection<? extends T>) 方法用于返回给定collection的最大元素,根据其元素的自然顺序。
声明
以下是java.util.Collections.max()方法的声明。
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
参数
coll-- 其最大元素的集合
返回值
方法调用返回给定collection的最大元素,根据其元素的自然顺序。
异常
ClassCastException--这被抛出,如果集合中包含不可相互比较的(例如,字符串和整数)个元素。
NoSuchElementException--如果集合是空的,抛出此异常。
下面的例子显示java.util.Collections.max()方法的使用
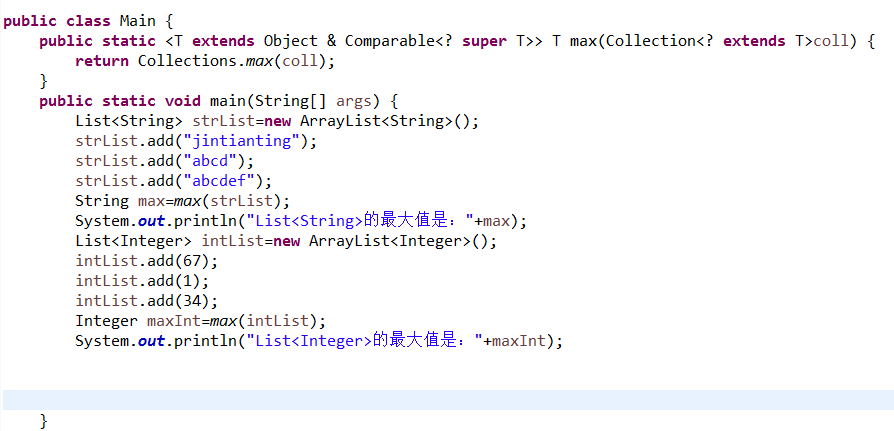

2.6.2 选做:现有User类,其子类为StuUser,且均实现了Comparable接口。编写方法max1,基本功能同6.1,使得User user = max1(stuList);可以运行成功,其中stuList为List类型。也可使得Object user = max(stuList)运行成功。
不是很理解这道题要做啥,上题可以实现Integer 和String类型的最大值输出已经使用到泛型,那这题沿用上题的max方法显然也可以实现。其次因为父类实现了Comparable接口,其中的Comparable To方法实现的是将User按照年龄从小到大排序,那么调用max方法后将输出年龄最大的StuUser。另外所有的类is a Object,Object user = max(stuList)也可以运行成功。如果User user = max1(stuList);这句是想输出User,那将StuUser里面的toString方法注释掉就好了。


2.6.3 选做:编写int myCompare(T o1, T o2, Comparator c)方法,该方法可以比较两个User对象,也可以比较两个StuUser对象,传入的比较器c既可以是Comparator<User>,也可以是Comparator<StuUser>。注意:该方法声明未写全,请自行补全。
方法代码:
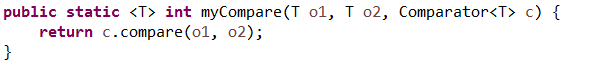
测试数据:

运行结果:
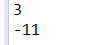
2.7 选做:逆向最大匹配分词算法
集合实验文件中的第07次实验(集合).doc文件,里面的题目6.
2.7.1 写出伪代码(不得直接复制代码)
- HashSet存储词表。
- 循环遍历句子,过程如下:

- 如果遍历完句子都没有找到一个集中的词,则说明该词不存在,直接输出该字符就好。
2.7.2 截图你的代码运行结果。
有部分没实现,词表中包含命和生命,逆向的话先得到命,这一点还没想清楚。
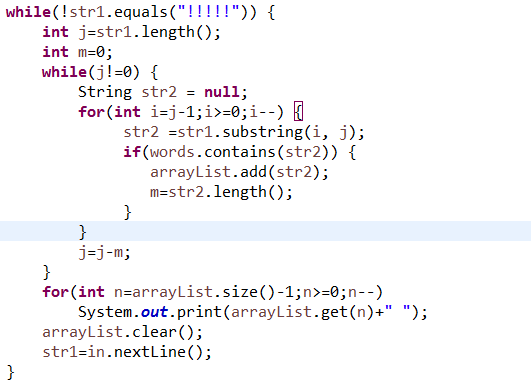


3.码云及PTA
题目集:jmu-Java-05-集合
3.1. 码云代码提交记录
在码云的项目中,依次选择“统计-Commits历史-设置时间段”, 然后搜索并截图
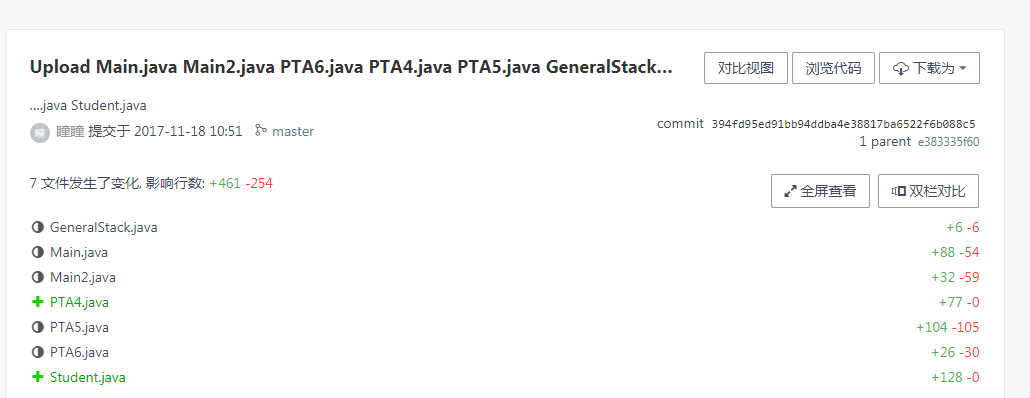
3.2 截图PTA题集完成情况图
需要有两张图(1. 排名图。2.PTA提交列表图)

3.3 统计本周完成的代码量
需要将每周的代码统计情况融合到一张表中。
自己的目标能实现吗?
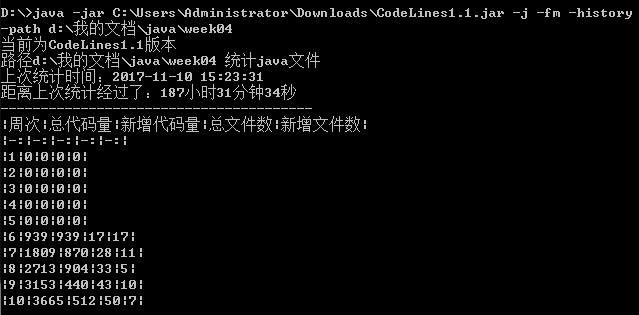
| 周次 | 总代码量 | 新增代码量 | 总文件数 | 新增文件数 |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 |
| 6 | 939 | 939 | 17 | 17 |
| 7 | 1809 | 870 | 28 | 11 |
| 8 | 2713 | 904 | 33 | 5 |
| 9 | 3153 | 440 | 43 | 10 |
| 10 | 3665 | 512 | 50 | 7 |
3.4 评估自己对Java的理解程度
尝试从以下几个维度评估自己对Java的理解程度
| 维度 | 程度 |
|---|---|
| 语法 | PTA的题目可以自行完成,不会就百度,写完只是时间问题 |
| 面向对象设计能力 | 需要时间思考如何根据问题设计合适的模型 |
| 应用能力 | 还未尝试编写小工具,如果只是图形界面的话我觉得还行 |
| 至今为止代码行数 | 3665 |
3.5 选做:使用Java解决实际问题
有n门课程,每个学生对每门课程都有几个不懂的问题(每题都有标号)。教师期望对所有学生的问题进行归类,首先对问题按课程分类,在某类中又将同一个学生的题目归类在一起。现有的操作流程,是每个学生把自己的各科目中不懂得题目按课程分类号后发给学习委员,学习委员进行统一汇总。现在希望编写一个程序,帮助学习委员分类,并统计每门课程中哪些题目不懂率最高。尝试写出解决该问题的大概步骤?每个学生发给学习委员的文件内容应遵循一定规范方便程序处理,尝试写出该规范
- 先整合一张规范的文件。
- JAVA导入POI的jar包。进行一些基本的设置。
- 读取文件,遇到“,”就移至下一个单元格,遇到回车就移至下一行。
- 获取除首行外的每一列内容添加至一个List中,统计某个题目的数量,除以List的长度得到该题目的不懂率。
规范文本:

(其实在文本文件中使用tab键和回车键就好,之后将文本文件复制在excel中就会实现自动换行换列,统计不懂率应该在Excel中也是可以操作的)