一、数据库概念设计
主要解决数据需求,即如何准确地理解数据需求。
任务:
涉及的数据范围、数据的属性特征、数据之间的关系、数据的约束、数据安全性要求、数据处理需求、保证信息模型方便地转换成数据库的逻辑结构。
依据:
依据是需求说明书、功能模型、收集到的各类报表,从中抽取中数据之间的相互联系和满足的约束条件。
构造信息模型,编写数据库概念设计说明书(逻辑设计的依据)。
过程:
明确建模目标。
定义实体集(通常采用自底向上的方式):先分别画出子系统的ER图,然后将局部ER图集合整合成应用系统总体的信息模型。
定义联系:描述实体集之间的关联关系。
建立信息模型:ER图,先局部再总体。
确定实体集属性:可以不画在模型图中。
对信息模型进行集成和优化。
数据建模方法
ER建模方法:
实体(实例):一个具体的人或物,也可以是抽象事物。
实体集:学生的实体集指全部学生的集合,集合中的一个元素是这个实体机的一个实例。

属性:

码:能唯一标识每一个实例的属性或属性组称为该实体集的码。
联系:
实物之间的联系
有一对一、一对多、多对多联系。
IDEF1X建模方法:
IDEF0描述系统功能需求,是功能建模方法。
IDEF1X侧重分析、抽象和概括应用领域中的数据需求,是数据建模方法。
元素:
实体集:每个实体集有唯一名字和编码,写在矩形框的上方——实体集/编号
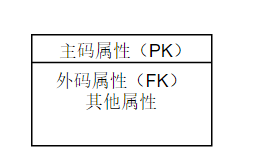
独立实体集:每个实例都被唯一地标识,不决定于它与其他实体集的联系,比如学号。
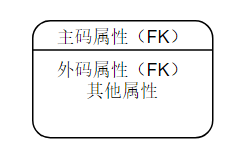
从属实体集:从属实体的实例依赖于独立实体的实例存在而存在。
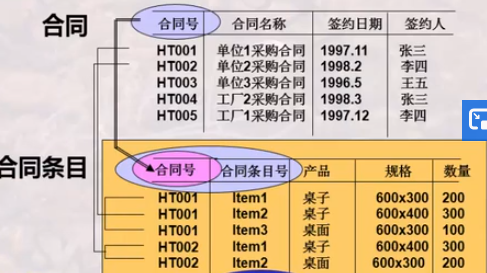
例子:
合同条目号依赖于合同号,否则没有意义。
联系:
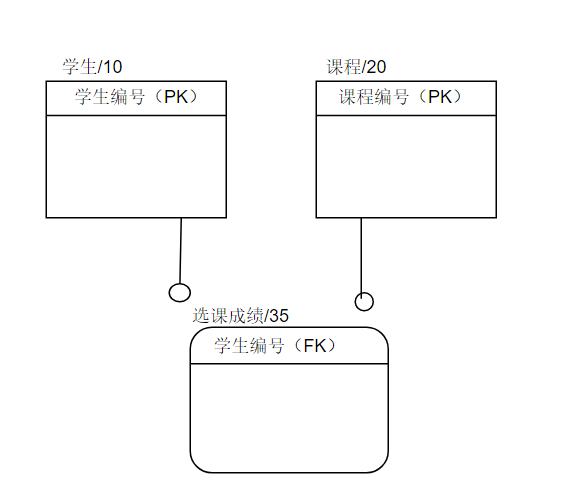
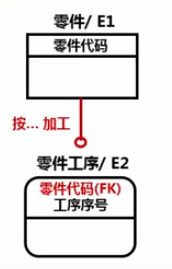
连接联系分为:标定联系和非标定联系,又称父子联系或依存联系。(一对多)
标定型联系:(独立实体与从属实体的联系,父实体的主关键字是子实体主关键字的一部分)
子女实体集中的每个实例都是由它与双亲的联系而确定的。
如:选课成绩由学生编号和课程编号确定,零件代码与零件加工工序。
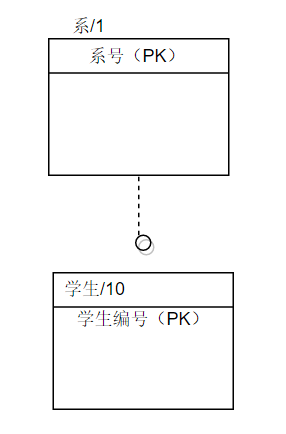
非标定型联系:(父实体的主关键字不是子实体的主关键字,如顾客签合同,两个都是独立实体)
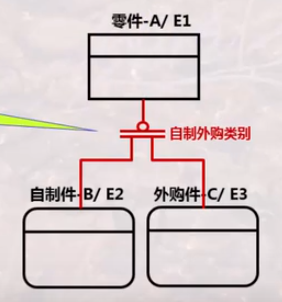
分类联系:
含一个一般实体实例和多个分类实体实例。
有相同属性(在一般实体中),和不同属性。
非确定联系:(多对多联系,如读者借书)

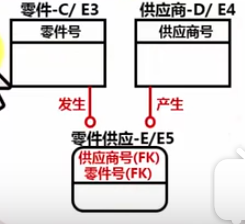
引入相交实体实现实体间的联系。
二、数据库逻辑设计
把ER模型转换为具体的数据库管理系统支持的数据模型,并对其进行优化,是面向机器世界的。
函数依赖:
如果学号相同,姓名也相同,则学号决定于姓名,姓名依赖于学号,即学号相同的时候,姓名没有不同的值)。
部分和完全函数依赖:
成绩完全函数依赖于(学号,课号),姓名部分函数依赖于(学号,课号)。
传递函数依赖:
学号决定班号,班号决定班长,班长传递函数依赖于学号。
(商店,商品)决定商品经营部,商品经营部决定经营部经理,所以经营部经理传递函数依赖于(商店,商品)。
平凡函数依赖:
对任一关系模式必然成立。
(学号,班号)决定学号。
学号决定学号。
候选码:如果某属性组能唯一确定整个元组的值,则称该属性组为候选码或候选关键字。
主码:如果候选码有多个,可以选一个作为主码。
外码:或外键,另外一个关系模式的主码(或候选键)。如学号是学生信息的主码,是SC关系的外码。
非主属性:不包含在候选键中的属性。
关系模式规范化:
范式:关系模式所满足的约束条件。
第一范式:每一个属性都是不可再分的数据项(原子的)。
多值属性或者复合属性不满足第一范式。
转换为第一范式:

第二范式:首先要符合第一范式,每个非主属性完全依赖于主码。
(学号,课号)决定课程名(或姓名),存在部分依赖,不满足第二范式。
第三范式:首先符合第二范式,每个非主属性不传递依赖于主码。
先由学号确定所在学院,再确定学院地点和电话,存在传递依赖。

三、数据库物理设计
概述:
将数据的逻辑描述转换为实现技术规范,目标是设计数据存储方案,提供足够好的性能。
不包括文件和数据库的具体实现细节(比如如何创建文件)。
数据库中的数据是以文件的形式存储在外存上。
物理设计要解决的解决问题:
文件的组织、文件的结构、文件的存取、索引技术。
索引:
分类:
有序索引:(索引文件机制)
实现记录域(查找码,可以是主属性,也可以是非主属性,或者属性的组合值)取值到记录物理地址间的映射关系。
先查阅索引文件,找到对应的索引项,从索引项中找出数据记录在数据文件中的物理地址,根据地址找到数据记录。
散列技术:哈希。
聚集索引:数据文件中数据记录的排列顺序与索引文件中索引项的排列顺序一致。
(属性作为分组、排序条件,作为检索限制条件)
一个主文件通常只有一个聚集索引,可以有多个非聚集索引。
主索引通常是聚集索引。

非聚集索引:
辅索引通常是非聚集索引。
稠密索引:主文件中每一个不同的值都有索引记录与之对应。
非候选键作为查找码时,索引记录不能重复,主文件中字段须排序存储。
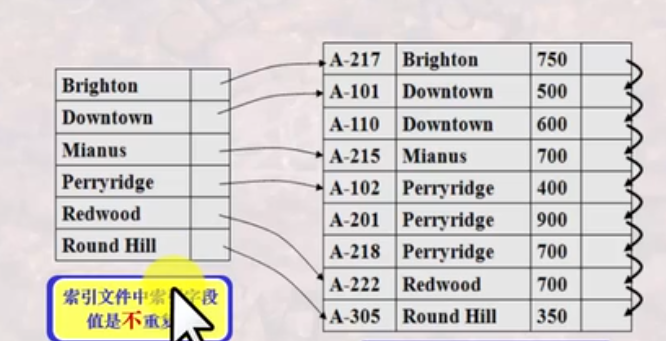
如果主文件中没有排序存储,则索引记录可重复。
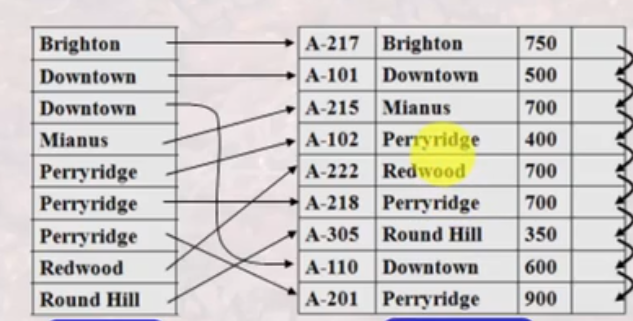
稀疏索引:主文件中只有部分不同值有索引。(如何查找?:通过索引找到最近的值,再顺序检索)。
主索引:每个存储块有一个索引项,通常建立在主文件的主码的排序字段上,通常属于稀疏索引(没有排序存储的时候可能是稠密索引)。
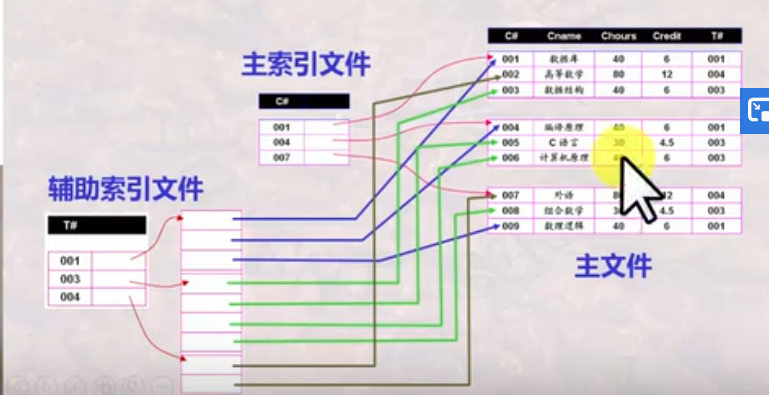
辅索引:建立在非排序字段上,可使用中间链表来保存多个记录的位置。
辅索引是稠密索引。

唯一索引:索引列不包含重复的值,在多列唯一索引的情况下,可以确保索引列中每个值的组合都是唯一的。
单层索引:也叫线性索引,如前面所提到的各类。
多层索引:通过多层树型结构快速定位大数据量文件中的数据记录。
B树/B+树索引,暂不展开。
倒排索引:
一个词汇包含在哪些文档中?
以关键词为组织单位。
按照关键词排序。
建立索引原则:
聚集函数参数、连接、
物理设计内容:
数据库逻辑模式描述:把关系模式转换成基本表和视图,利用完整性约束设计业务规则。
文件组织和存取设计:对文件、顺序文件、索引文件、散列文件等。存取方法:索引、聚簇、HASH等。
数据分布设计:根据类型、作用、频率不同,合理安排在不同存储介质中。
水平,垂直划分。
确定系统配置
物理模式评估:从多种可行方案中选择合理的数据库物理结构。
设计结果应形成物理设计文档,供下一阶段的数据库实现与部署使用。
数据库逻辑模式描述:
DB文件组织与存取设计
有序记录文件:排序字段。排序效率高,更新效率不高。数据库重组:将溢出文件合并到主文件。
堆文件:一个基本表中数据流少,插入、删除、更新频繁。无须建立索引,维护代价低。更新效率高,检索效率低。
B-和B+树文件:大数据量、等值查询、范围查询、模糊查询和部分查询。动态索引,可以随着数据文件的内容变化而不断调整,保证性能不会恶化。
聚集文件:将相同或相似的记录存放在连续的磁盘簇块中,执行频繁和需要进行多表连接的操作。
考虑建立索引的情况:
主码、WHERE、连接、Order by、Group by、一个属性有很多不同值。
很多数据库管理系统中的索引不引用具有空值的行,对空值的查找需要使用全表扫描来实现。
关系模式去规范化:可以提高查询效率,但是可能出现插入异常、删除异常、更新异常和数据冗余的问题。