本周学习的东西比较杂,主要是继续完成征集系统,其次是初学MapReduce,使用C++完成递归向下分析法,接下来作个总结:
征集系统仅展示动态树形结构的生成,使用layui实现,要求是项目名称作为子节点,后边有个数标识,先看代码:
TreeDao.java(遍历数据库,拿到数据并计数,后台构造出jsonarray形式的数据之后传到前端展示)
1 package Dao; 2 3 import java.sql.Connection; 4 import java.sql.ResultSet; 5 import java.sql.Statement; 6 import java.util.HashMap; 7 import java.util.Iterator; 8 import java.util.Map; 9 import java.util.Set; 10 11 import net.sf.json.JSONObject; 12 import net.sf.json.JSONArray; 13 import util.DBUtil; 14 15 public class TreeDao { 16 public static JSONArray dochildren(Map<String,Integer>map, String id_str) { 17 JSONArray ja=new JSONArray(); 18 Set<String> set=map.keySet(); 19 Iterator<String> it=set.iterator(); 20 while(it.hasNext()) { 21 JSONObject ans=new JSONObject(); 22 String key=(String)it.next(); 23 int value=(int)map.get(key); 24 String key_str=key+"("+value+")"; 25 ans.put("title", key_str); 26 ans.put("id", id_str); 27 ja.add(ans); 28 } 29 return ja; 30 } 31 public static String CreateTree(String sql) { 32 String ans=""; 33 Connection con=DBUtil.getConn(); 34 Statement state=null; 35 ResultSet rs=null; 36 JSONArray jsonarray=new JSONArray(); 37 Map<String, Integer> jgmc=new HashMap<String, Integer>(); 38 Map<String, Integer> gkglbm=new HashMap<String, Integer>(); 39 Map<String, Integer> szdy=new HashMap<String, Integer>(); 40 Map<String, Integer> frdb=new HashMap<String, Integer>(); 41 Map<String, Integer> lxr=new HashMap<String, Integer>(); 42 Map<String, Integer> jgsx=new HashMap<String, Integer>(); 43 Map<String, Integer> jsxqmc=new HashMap<String, Integer>(); 44 Map<String, Integer> gjz=new HashMap<String, Integer>(); 45 Map<String, Integer> ntrzjze=new HashMap<String, Integer>(); 46 Map<String, Integer> jsxqjjfs=new HashMap<String, Integer>(); 47 Map<String, Integer> yjlx=new HashMap<String, Integer>(); 48 Map<String, Integer> xkfl=new HashMap<String, Integer>(); 49 Map<String, Integer> xqjsssly=new HashMap<String, Integer>(); 50 Map<String, Integer> xqjsyyhy=new HashMap<String, Integer>(); 51 Map<String, Integer> glcs=new HashMap<String, Integer>(); 52 try { 53 state=con.createStatement(); 54 rs=state.executeQuery(sql); 55 String jgmcmc=""; 56 String gkglbmmc=""; 57 String szdymc=""; 58 String frdbmc=""; 59 String lxrmc=""; 60 String jgsxmc=""; 61 String jsxqmcmc=""; 62 String gjzmc=""; 63 String ntrzjzemc=""; 64 String jsxqjjfsmc=""; 65 String yjlxmc=""; 66 String xkflmc=""; 67 String xqjssslymc=""; 68 String glcsmc=""; 69 String xqjsyyhymc=""; 70 while(rs.next()) { 71 if(rs.getString("JGMC")==null||rs.getString("JGMC").equals("")) { 72 jgmcmc="无"; 73 }else { 74 jgmcmc=rs.getString("JGMC"); 75 } 76 if(rs.getString("GKGLBM")==null||rs.getString("GKGLBM").equals("")) { 77 gkglbmmc="无"; 78 }else { 79 gkglbmmc=rs.getString("GKGLBM"); 80 } 81 if(rs.getString("SZDY")==null||rs.getString("SZDY").equals("")) { 82 szdymc="无"; 83 }else { 84 szdymc=rs.getString("SZDY"); 85 } 86 if(rs.getString("FRDB")==null||rs.getString("FRDB").equals("")) { 87 frdbmc="无"; 88 }else { 89 frdbmc=rs.getString("FRDB"); 90 } 91 if(rs.getString("LXR")==null||rs.getString("LXR").equals("")) { 92 lxrmc="无"; 93 }else { 94 lxrmc=rs.getString("LXR"); 95 } 96 if(rs.getString("JGSX")==null||rs.getString("JGSX").equals("")) { 97 jgsxmc="无"; 98 }else { 99 jgsxmc=rs.getString("JGSX"); 100 } 101 if(rs.getString("JSXQMC")==null||rs.getString("JSXQMC").equals("")) { 102 jsxqmcmc="无"; 103 }else { 104 jsxqmcmc=rs.getString("JSXQMC"); 105 } 106 if(rs.getString("GJZ")==null||rs.getString("GJZ").equals("")) { 107 gjzmc="无"; 108 }else { 109 gjzmc=rs.getString("GJZ"); 110 } 111 if(rs.getString("NTRZJZE")==null||rs.getString("NTRZJZE").equals("")) { 112 ntrzjzemc="无"; 113 }else { 114 ntrzjzemc=rs.getString("NTRZJZE"); 115 } 116 if(rs.getString("JSXQJJFS")==null||rs.getString("JSXQJJFS").equals("")) { 117 jsxqjjfsmc="无"; 118 }else { 119 jsxqjjfsmc=rs.getString("JSXQJJFS"); 120 } 121 if(rs.getString("YJLX")==null||rs.getString("YJLX").equals("")) { 122 yjlxmc="无"; 123 }else { 124 yjlxmc=rs.getString("YJLX"); 125 } 126 if(rs.getString("XKFL")==null||rs.getString("XKFL").equals("")) { 127 xkflmc="无"; 128 }else { 129 xkflmc=rs.getString("XKFL"); 130 } 131 if(rs.getString("XQJSSSLY")==null||rs.getString("XQJSSSLY").equals("")) { 132 xqjssslymc="无"; 133 }else { 134 xqjssslymc=rs.getString("XQJSSSLY"); 135 } 136 if(rs.getString("XQJSYYHY")==null||rs.getString("XQJSYYHY").equals("")) { 137 xqjsyyhymc="无"; 138 }else { 139 xqjsyyhymc=rs.getString("XQJSYYHY"); 140 } 141 if(rs.getString("GLCS")==null||rs.getString("GLCS").equals("")) { 142 glcsmc="无"; 143 }else { 144 glcsmc=StatusDao.UserStatus(rs.getString("GLCS")); 145 } 146 if(jgmc.get(jgmcmc)==null) { 147 jgmc.put(jgmcmc, 1); 148 }else { 149 jgmc.put(jgmcmc, jgmc.get(jgmcmc)+1); 150 } 151 if(gkglbm.get(gkglbmmc)==null) { 152 gkglbm.put(gkglbmmc, 1); 153 }else { 154 gkglbm.put(gkglbmmc, gkglbm.get(gkglbmmc)+1); 155 } 156 if(szdy.get(szdymc)==null) { 157 szdy.put(szdymc, 1); 158 }else { 159 szdy.put(szdymc, szdy.get(szdymc)+1); 160 } 161 if(frdb.get(frdbmc)==null) { 162 frdb.put(frdbmc, 1); 163 }else { 164 frdb.put(frdbmc, frdb.get(frdbmc)+1); 165 } 166 if(lxr.get(lxrmc)==null) { 167 lxr.put(lxrmc, 1); 168 }else { 169 lxr.put(lxrmc, lxr.get(lxrmc)+1); 170 } 171 if(jgsx.get(jgsxmc)==null) { 172 jgsx.put(jgsxmc, 1); 173 }else { 174 jgsx.put(jgsxmc, jgsx.get(jgsxmc)+1); 175 } 176 if(jsxqmc.get(jsxqmcmc)==null) { 177 jsxqmc.put(jsxqmcmc, 1); 178 }else { 179 jsxqmc.put(jsxqmcmc, jsxqmc.get(jsxqmcmc)+1); 180 } 181 if(gjz.get(gjzmc)==null) { 182 gjz.put(gjzmc, 1); 183 }else { 184 gjz.put(gjzmc, gjz.get(gjzmc)+1); 185 } 186 if(ntrzjze.get(ntrzjzemc)==null) { 187 ntrzjze.put(ntrzjzemc, 1); 188 }else { 189 ntrzjze.put(ntrzjzemc, ntrzjze.get(ntrzjzemc)+1); 190 } 191 if(jsxqjjfs.get(jsxqjjfsmc)==null) { 192 jsxqjjfs.put(jsxqjjfsmc, 1); 193 }else { 194 jsxqjjfs.put(jsxqjjfsmc, jsxqjjfs.get(jsxqjjfsmc)+1); 195 } 196 if(yjlx.get(yjlxmc)==null) { 197 yjlx.put(yjlxmc, 1); 198 }else { 199 yjlx.put(yjlxmc, yjlx.get(yjlxmc)+1); 200 } 201 if(xkfl.get(xkflmc)==null) { 202 xkfl.put(xkflmc, 1); 203 }else { 204 xkfl.put(xkflmc, xkfl.get(xkflmc)+1); 205 } 206 if(xqjsssly.get(xqjssslymc)==null) { 207 xqjsssly.put(xqjssslymc, 1); 208 }else { 209 xqjsssly.put(xqjssslymc, xqjsssly.get(xqjssslymc)+1); 210 } 211 if(glcs.get(glcsmc)==null) { 212 glcs.put(glcsmc, 1); 213 }else { 214 glcs.put(glcsmc, glcs.get(glcsmc)+1); 215 } 216 if(xqjsyyhy.get(xqjsyyhymc)==null) { 217 xqjsyyhy.put(xqjsyyhymc, 1); 218 }else { 219 xqjsyyhy.put(xqjsyyhymc, xqjsyyhy.get(xqjsyyhymc)+1); 220 } 221 } 222 223 JSONArray j1=dochildren(jgmc, "JGMC"); 224 jsonarray.add(j1); 225 JSONArray j2=dochildren(gkglbm,"GKGLBM"); 226 jsonarray.add(j2); 227 JSONArray j3=dochildren(szdy,"SZDY"); 228 jsonarray.add(j3); 229 JSONArray j4=dochildren(frdb,"FRDB"); 230 jsonarray.add(j4); 231 JSONArray j5=dochildren(lxr,"LXR"); 232 jsonarray.add(j5); 233 JSONArray j6=dochildren(jgsx,"JGSX"); 234 jsonarray.add(j6); 235 JSONArray j7=dochildren(jsxqmc,"JSXQMC"); 236 jsonarray.add(j7); 237 JSONArray j8=dochildren(gjz,"GJZ"); 238 jsonarray.add(j8); 239 JSONArray j9=dochildren(ntrzjze,"NTRZJZE"); 240 jsonarray.add(j9); 241 JSONArray j10=dochildren(jsxqjjfs,"JSXQJJFS"); 242 jsonarray.add(j10); 243 JSONArray j11=dochildren(yjlx,"YJLX"); 244 jsonarray.add(j11); 245 JSONArray j12=dochildren(xkfl,"XKFL"); 246 jsonarray.add(j12); 247 JSONArray j13=dochildren(xqjsssly,"XQJSSSLY"); 248 jsonarray.add(j13); 249 JSONArray j14=dochildren(xqjsyyhy,"XQJSYYHY"); 250 jsonarray.add(j14); 251 JSONArray j15=dochildren(glcs,"GLCS"); 252 jsonarray.add(j15); 253 }catch(Exception e) { 254 e.printStackTrace(); 255 } 256 ans=jsonarray.toString(); 257 return ans; 258 } 259 260 }
TryTree.html(动态构造树形结构,使用了layui组件)
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Insert title here</title> 6 <script type="text/javascript" src="js/jquery.js"></script> 7 <script type="text/javascript" src="js/cookie.js"></script> 8 <link rel="stylesheet" type="text/css" href="layui/css/layui.css"/> 9 </head> 10 <body> 11 <div id="test1"></div> 12 <script src="layui/layui.all.js"></script> 13 <script> 14 layui.use('tree',function(){ 15 var tree=layui.tree; 16 $.post( 17 'OrganServlet?method=tree', 18 {"where":"formal"}, 19 function (msg) { 20 var json=JSON.parse(msg); 21 console.log(json); 22 var inst1=tree.render({ 23 elem:'#test1', 24 data:[{ 25 title:'机构全称', 26 children:json[0] 27 },{ 28 title:'归口管理单位', 29 children:json[1] 30 },{ 31 title:'所在地域', 32 children:json[2] 33 },{ 34 title:'法人代表', 35 children:json[3] 36 },{ 37 title:'联系人', 38 children:json[4] 39 },{ 40 title:'机构属性', 41 children:json[5] 42 },{ 43 title:'技术需求名称', 44 children:json[6] 45 },{ 46 title:'关键字', 47 children:json[7] 48 },{ 49 title:'拟投入资金总额', 50 children:json[8] 51 },{ 52 title:'技术需求解决方式', 53 children:json[9] 54 },{ 55 title:'科技活动类型', 56 children:json[10] 57 },{ 58 title:'学科分类', 59 children:json[11] 60 },{ 61 title:'需求技术所属领域', 62 children:json[12] 63 },{ 64 title:'需求技术应用行业', 65 children:json[13] 66 },{ 67 title:'管理处室', 68 children:json[14] 69 } 70 ], 71 click:function(obj){ 72 layer.msg(JSON.stringify(obj.data)); 73 } 74 }) 75 } 76 ); 77 }); 78 </script> 79 </body> 80 </html>
这部分的关键在于要明白layui树形组件中data的构造结构。最终实现情况如下,点击事件设置为显示节点数据,整合到项目时该数据将作为查询条件返回后台完成查询效果:

第二部分是MapReduce,使用MapReduce实现字符统计,因MapReduce包含在hadoop内,使用wordcount实现,所以不必再进行安装。实现的是核心思路是编写必要的java运行文件,之后将项目打成jar包传到Linux上,调用即可。
编写的三个java文件:
WordCountDriver.java(调用)
1 package com.mapr; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 import java.io.IOException; 11 12 public class WordCountDriver { 13 public static void main(String[]args)throws IOException, ClassNotFoundException, InterruptedException{ 14 // 1 获取配置信息以及封装任务 15 Configuration configuration = new Configuration(); 16 Job job = Job.getInstance(configuration); 17 // 2 设置jar加载路径 18 job.setJarByClass(WordCountDriver.class); 19 // 3 设置map和reduce类 20 job.setMapperClass(WordCountMapper.class); 21 job.setReducerClass(WordCountReducer.class); 22 // 4 设置map输出 23 job.setMapOutputKeyClass(Text.class); 24 job.setMapOutputValueClass(IntWritable.class); 25 // 5 设置Reduce输出 26 job.setOutputKeyClass(Text.class); 27 job.setOutputValueClass(IntWritable.class); 28 // 6 设置输入和输出路径 29 FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.132.128:9000/mymapreduce1/in/MapReduceTry.txt")); 30 FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.132.128:9000/mymapreduce1/out")); 31 // 7 提交 32 job.waitForCompletion(true); 33 } 34 }
WordCountMapper.java(提取文档中的字符串,按指定要求划分成段)
1 package com.mapr; 2 3 import org.apache.hadoop.io.*; 4 import org.apache.hadoop.mapreduce.Mapper; 5 import java.io.IOException; 6 7 public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ 8 Text k=new Text(); 9 IntWritable v=new IntWritable(1); 10 protected void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{ 11 String line=value.toString(); 12 String[] words=line.split(" "); 13 for(String word:words){ 14 k.set(word); 15 context.write(k,v); 16 } 17 } 18 }
WordCountReducer.java(对每个字段进行个数统计)
1 package com.mapr; 2 3 import org.apache.hadoop.io.*; 4 import org.apache.hadoop.mapreduce.Reducer; 5 import java.io.IOException; 6 7 public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ 8 int sum; 9 IntWritable v=new IntWritable(); 10 protected void reduce(Text key, Iterable<IntWritable> values,Context context)throws IOException,InterruptedException{ 11 sum=0; 12 for(IntWritable count:values){ 13 sum+=count.get(); 14 } 15 v.set(sum); 16 context.write(key,v); 17 } 18 }
将项目打包:

上传到Linux文件之后,调用执行即可,显示结果如下(片段)
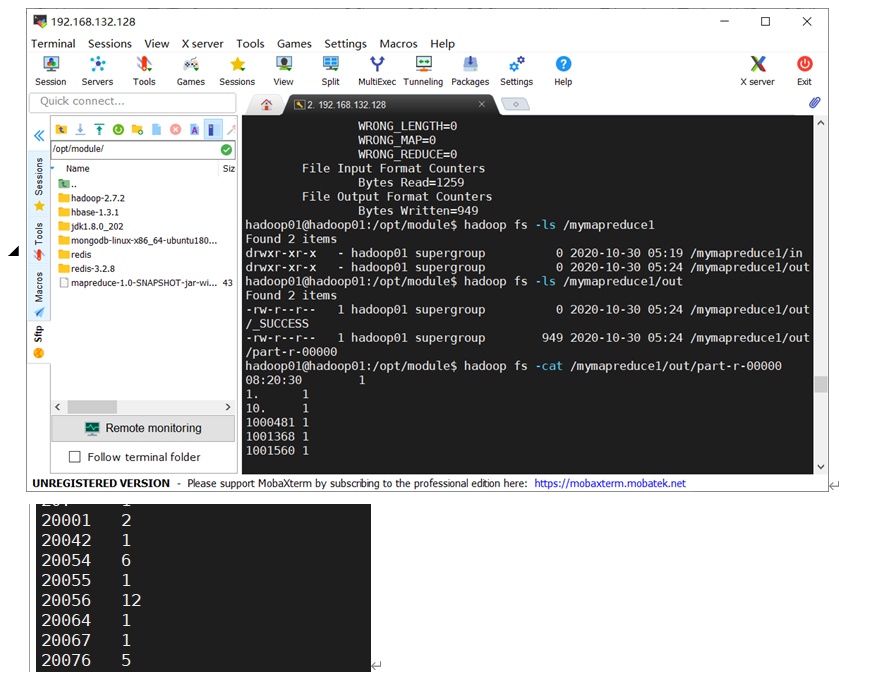
最后是C++实现文法分析,这里读懂题目给的文法结构,照着写函数递归调用就行。
题目:

接下来照着文法写代码:
1 #include<iostream> 2 #include<string> 3 #include<stdlib.h> 4 using namespace std; 5 6 int index = 0; 7 char str[50]; 8 9 void E(); 10 void T(); 11 void G(); 12 void S(); 13 void F(); 14 15 int main() 16 { 17 cout << "请输入字符串(长度<50,以#号为结尾)" << endl; 18 cin >> str; 19 E(); 20 return 0; 21 } 22 void Output() 23 { 24 cout << "分析字符:" << str[index] << " "; 25 cout << "分析串:"; 26 int len = strlen(str); 27 for (int i = 0; i < index; i++) 28 { 29 cout << str[i]; 30 } 31 cout << " "; 32 cout << "剩余串:"; 33 for (int i = index; i < len; i++) 34 { 35 cout << str[i]; 36 } 37 cout << endl; 38 } 39 void E() 40 { 41 cout << "文法:E->TG "; 42 Output(); 43 T(); 44 G(); 45 } 46 void T() 47 { 48 cout << "文法:T->FS "; 49 Output(); 50 F(); 51 S(); 52 } 53 void G() 54 { 55 if (str[index] == '+') 56 { 57 cout << "文法:G->+TG "; 58 Output(); 59 index++; 60 T(); 61 G(); 62 } 63 else if (str[index] == '-') 64 { 65 cout << "文法:G->-TG "; 66 Output(); 67 index++; 68 T(); 69 G(); 70 } 71 else 72 { 73 cout << "文法:G->^ "; 74 Output(); 75 } 76 } 77 void S() 78 { 79 if (str[index] == '*') 80 { 81 cout << "文法:S->*FS "; 82 Output(); 83 index++; 84 F(); 85 S(); 86 } 87 else if (str[index] == '/') 88 { 89 cout << "文法:S->/FS "; 90 Output(); 91 index++; 92 F(); 93 S(); 94 } 95 else 96 { 97 cout << "文法:S->^ "; 98 Output(); 99 } 100 } 101 void F() 102 { 103 if (str[index] == 'i') 104 { 105 cout << "文法:F->i "; 106 Output(); 107 index++; 108 } 109 else if (str[index] == '(') 110 { 111 cout << "文法:F->(E) "; 112 Output(); 113 index++; 114 E(); 115 if (str[index] == ')') 116 { 117 cout << "文法:F->(E) "; 118 Output(); 119 index++; 120 } 121 else 122 { 123 cout << "文法:F->^ "; 124 Output(); 125 cout << "ERROR" << endl; 126 exit(0); 127 } 128 } 129 else 130 { 131 cout << "文法:F->^ "; 132 Output(); 133 cout << "ERROR" << endl; 134 exit(0); 135 } 136 }
这里并不难理解,以E->TG为例,就是E()函数内,先执行T(),再执行G(),其他类似,而那种包含或关系的,如G->+TG|-TG,就是在执行TG之前,使用if-else判断是+号还是-号,如代码中所示。
运行截图:
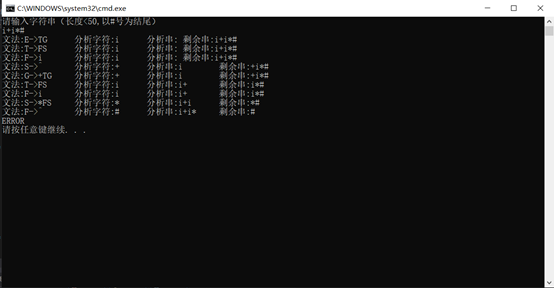

以上是本周总结。