1,我们是先创建一个django项目,要同时把app带上,
然后再django项目里面把settings部分设置好,按照我们一开始创建django项目的时候设置的那些,csrf以及templates还有static里面的部分,
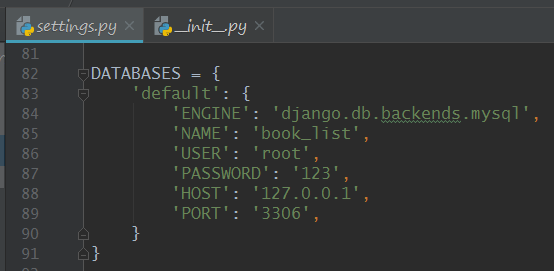
然后我们在settings里面找到databases,把里面的跟数据库连接的配置参数都设置好,default里面的engine(在原基础上把最后一个参数改成mysql即可),name(数据库名),
uuser(数据库用户名),password(数据库名对应的密码),host(数据库的ip地址,),port(数据库的端口)
到这里我们的setting里面的数据库参数配置就完成了
2.在我们的django里面,找到init文件在里面写上两句话,
import pymysql
pymysql.install_as_MySQLdb()
3.我们的orm是无法自己建库的,所以我们需要自己在命令行里面把库创建出来,仅仅是建库而已,
我们要把库先建立出来
4,再找到我们的App里面的models.py,我们在django里面运行这个程序它django本身就只是认识这个models而已,所以我们的数据库操作都要在这里执行,
class User(models.Model): # 这里的类名就是我们的数据库的名字
id = models.AutoField(primary_key=True) # 这里是字段名自增id,主键设定
name = models.CharField(max_length=30) # 字段名 varchar类型,最大长度是30
5.在models里面找到terminal,然后执行两句话,
python manage.py makemigrations # 我们的改动操作都需要执行这一句,
python manage.py migrate {我们这里的两句话执行是以类的形式去创建数据库里面的表格;类名对应的是数据库里面的表格,类的对象对应的是数据库里面的数据行,类的属性对应的是数据库里面的表格的字段}
五步:
1. 创建数据库
2. 在app下的models.py里面创建model类,继承models.Model
3. 在settings.py里面配置数据库连接信息
4. 在项目(project)的__init__.py里面写上 import pymysql, pymysql.install_as_MySQLdb()
5. 发命令:
python manage.py makemigrations 收集变更
python manage.py migrate 翻译成SQL语句,执行
四部分:
1. models.py
2. Django
3. pymysql
4. MySQL
ORM:
类 ---> 数据表
类的属性 ---> 数据列(表里的字段)
对象 ---> 数据行
补充一点注意事项:
queryset
可切片
使用python的切片语法来限制查询集记录的数目,它等同于sql的limit和offset字句,切片在orm里面是不支持负的索引,例如(entry.objects.all()[-2]) 通常,查询集的切片返回一个新的查询集,它不会执行查询
可迭代
articlelist=models.Article.objects.all()
for article in articlelist:
print(article.title)
惰性查询
查询集是惰性执行的---创建查询集不会带来任何数据库的访问,你可以将过滤器保持一整天,直到查询集需要求值时,django才会指正运行这个查询
queryresult=models.Article.objects.all()
print(queryresult)
for article in queryresult:
print(article.title)
一般来说只有在请求查询集的结果时才会到数据库中去获取它们,当你确实需要结果时,查询集通过访问数据库来值,关于求职发生的准确时间,
缓存机制
每个查询集都包含一个缓存来最小化对于数据库的访问,理解它是如何工作的将让你编写最高效的代码.
在一个新创建的查询集中,缓存为空,首次对查询集进行求值--同时发生数据库查询--django将保存查询的结果到查询集中并返回明确请求的结果(例如,如果正在迭代查询集,则返回下一个结果)接下来对该查询集的求值将重用缓存的结果.
请牢记这个缓存的行为,因为对查询集使用不当的话,效果会适得其反.例如,下面的语句创建两个查询集,对他们求值,然后扔掉它们:
print([a.title for a in models.Article.objects.all()])
print([a.create_time for a in models.Article.objects.all()])
这意味着相同的数据库查询将执行两次,显然倍增了你的数据库负载,同时还有可能两个结果列表并不包含相同的数据库记录,因为在两次请求期间有可能有Article被添加进来或删除掉,为了避免这个问题,只需要保存查询集并重新使用它:
queryresult=models.Article.objects.all()
print([a.title for a in queryresult])
print([a.create_time for a in queryresult])
何时查询集不会被缓存?
查询集不会永远缓存他们的结果,当只对查询集的部分进行求值时会检查会缓存,如果这个部分不在缓存中,那么接下来查询返回的记录都将不会被缓存,所以,这意味着使用切片或索引来限制查询集不会填充缓存.
例如,重复获取查询集对象中一个特定的索引将每次都查询数据库:
queryset=entry.objects.all()
print queryset[5] # queries the database
print queryset[5] # queries the database again
然而,如果已经对全部查询集求值过,则将检查缓存:
queryset=entry.objects.all()
[entry for entry in queryset] # queries the databases
print queryset[5] # uses cache
print queryset[5] # uses cache
下面是一些其他例子,他们会使得全部的查询集被求值并填充到缓存中:
[entry for entry in queryset]
bool(queryset)
entry in queryset
list(queryset)
注:简单地打印查询集不会填充缓存.
queryresult=models.Article.objects.all()
print(queryresult) # hits database
print(queryresult) # hits database
关于数据库创建表的两种方式:
1,code_first就是我们在django里面先把orm的创建数据库表的代码写出来然后进到terminal里面执行migrate命令操作就在数据库生成了表格
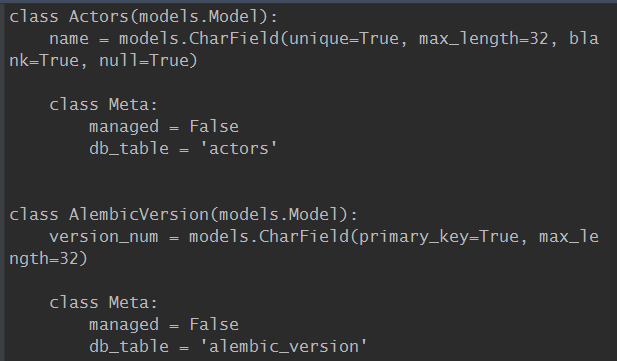
2,db_first就是在我们的数据库里面先用sql命令把数据库创建好,然后我们在django项目里面把settings文件里面所关联的数据库配置好,
在terminal里面执行
python manage.py inspectdb
得到效果如下图所示:这个命令就把我们数据库里面的所有表都生成了代码