MapReduce的输入输出
一个MapReduce作业的输入和输出类型:会有三组<key , value>键值对类型的存在

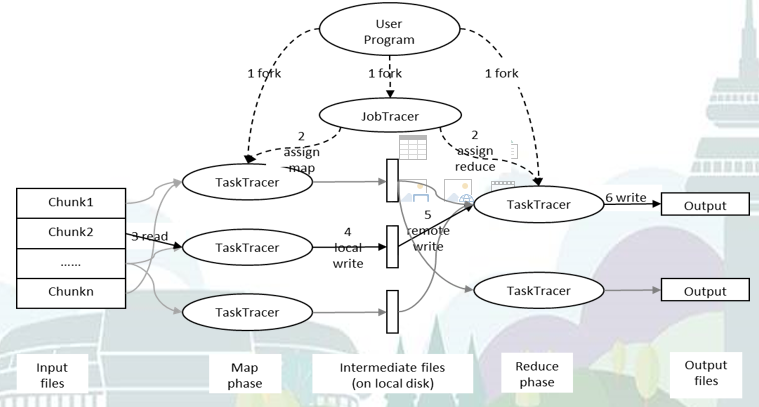
Mapreduce作业的处理流程
按照时间顺序包括:
输入分片(input split)
在进行map计算之前,mapreduce根据输入文件计算输入分片,每个输入分片针对一个map任务。
输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片往往和hdfs的block关系很密切。
map阶段
程序员编写好map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行的。
combiner阶段
conbiner阶段是程序员可以选择的,combiner其实也是一种reduce操作,因此我们看到WordCount类里是用reduce进行加载的。
Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入。
shuffle阶段
将map的输出作为reduce的输入的过程就是shuffle。
reduce阶段
由程序员编写,最终结果存储在hdfs上。