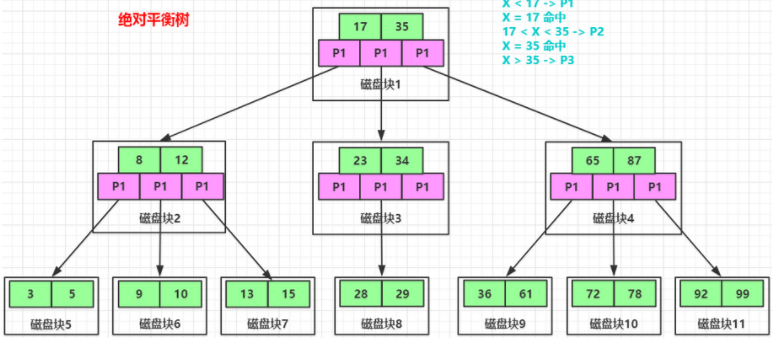
首先B树的所有节点都存储数据信息,而B+ 树的所有数据都存储在叶子节点
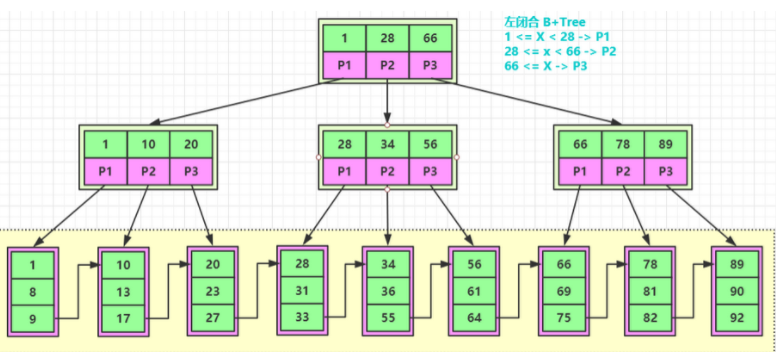
B+ 树是在B树的基础上的一种优化,使其更加适合外存储索引结构,InnoDB存储引擎及时B+ 树实现其索引结构
从B树结构图中可以看到每个节点中不仅包含数据的Key值,还有data值,而每一页的存储空间是有限的,如果data数据较大时会导致每一个节点(也就是每一页)能存储的key的数量很小,当存储的数据量很大时同时会导致B树的深度很深,高度很高,增大磁盘的IO次数,进而影响查询效率,在B+树中,所有数据节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储Key值信息,这样可以大大增加每个节点存储的key值数量,降低B+树的高度
以下是B树的结构图,所有的节点都有存储信息,
以下是B+ 树的结构示意图,只有在叶子节点才会存储数据信息,其他节点只存储key 值和索引,
总结:
-
B+Tree 是B-树的变种(PLUS版)多路绝对平衡查找树,它拥有B-树的优势**
-
B+Tree 扫库、表能力更强。
如果要从 B-Tree 中扫描表数据的话,基本要把整棵树都要扫描一遍,因为每个节点都存在数据区。B+Tree 就不需要扫描整棵树,只需要扫描叶子节点就可以了。
-
B+Tree** 的磁盘读写能力更强。
B+Tree 的节点上是不保存数据的,那么它保存的关键字就更多,这样一次 IO 操作,加载的关键字就更多,所以它的磁盘读写能力更强。
-
B+Tree** 的排序能力更强。
B+Tree 的叶子节点天然就是顺序存放的 。 B+树叶子节点是顺序排列的,并且相邻节点具有顺序引用的关系
-
B+Tree** 的查询效率更加稳定。
比如我们从上图的 B-Tree 中查询一条 id 等于8的数据需要经过两次 IO 操作,查询一条 id 等于3的数据需要经过三次 IO 操作,而从上图的 B+Tree 中只有叶子节点才保存数据,所以查询任何数据都需要经过三次 IO 操作。 所以 B+Tree 的查询效率更加稳定。
https://www.cnblogs.com/yinjw/p/11829284.html