性能测试过程中,不仅仅是对被测系统的性能问题定位、分析、优化,很多时候负责批量请求发起的压力机也存在各类性能瓶颈。毕竟用几千块钱的机器就想把几个亿的机器压瘫也是稍稍需要点技术的。
这里介绍一次典型的压力机性能优化过程,期间涉及到磁盘IO问题、CPU不足的问题、内存耗尽的问题,分别采用参数调整、代码调整等方法一一化解。
一、 压力机disk busy100%问题
(一) 问题
压力机的一个重要功能是作为挡板,接收A报文,返回对应的B报文。
性能测试过程中发现,用来接收报文的的本地队列拥堵,收到一批报文后,挡板要较长时间才能处理完,即回挡报文的效率很低。比如,接收A报文共10分钟,挡板一共用了17分钟才将所有B报文返回。
(二) 分析定位
首先看PC的任务管理器->资源监视器,从CPU、内存、网络、磁盘入手分析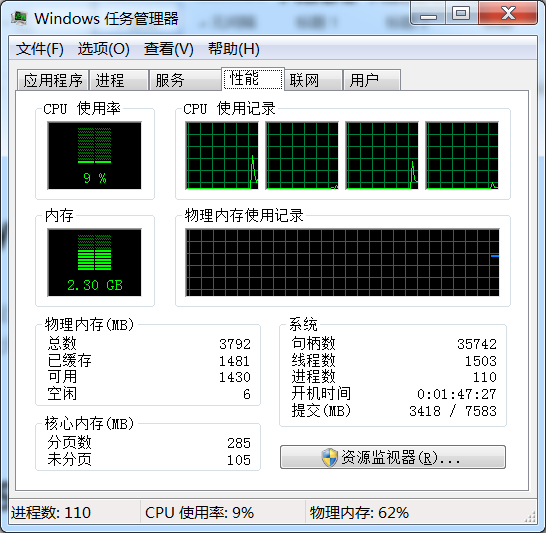
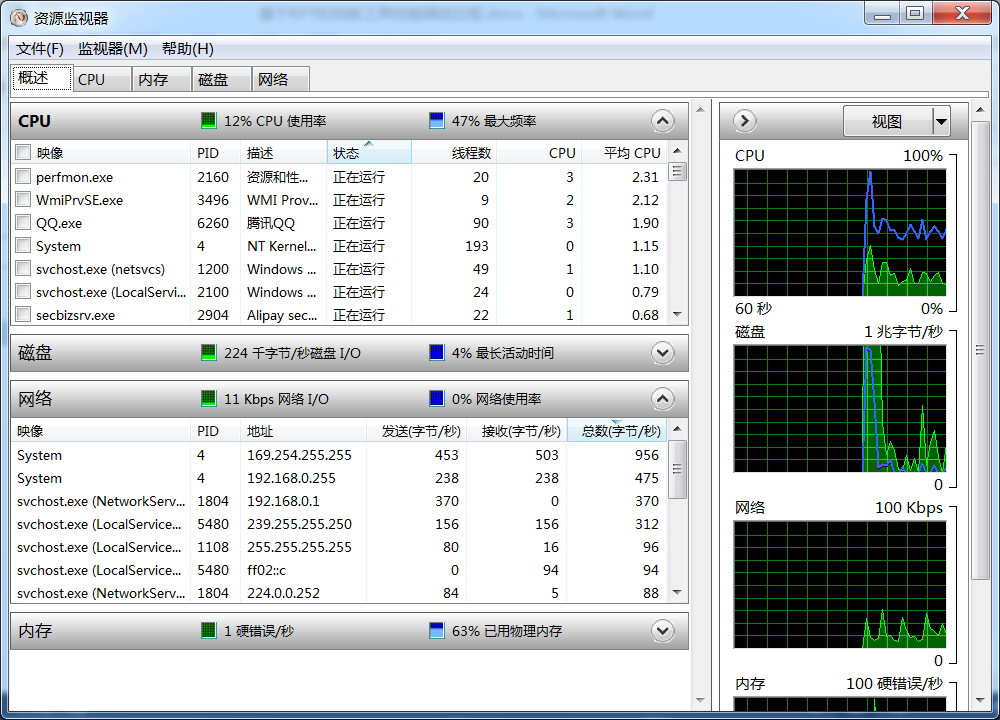
发现PC机“磁盘最长活动时间”长时间保持100%
接下来查看哪个进程用磁盘最多,发现是JAVA,但JAVA的应用很多,需要具体定位到是哪个应用。
在任务管理器中看这个进程是哪个应用,单击那个进程,右键“打开文件位置”;定位到使用磁盘最多的是MQ程序。
(三) 解决
MQ导致的写磁盘IO过多,最简单的方法就是减少写IO的次数。MQ写磁盘无非就是写日志、写报文,怎么样减少写IO的测试,这里需要一些MQ的知识。
1. 循环日志VS线性日志
MQ日志,有循环日志和线性日志两种,其中:
1)线性日志是连消息内容都保存在日志里,如果queue里面的消息被删了,也可以用日志恢复,即线性日志保存的内容多。
2)循环日志不保存消息
检查mq日志是不是线性日志,如果是,可以改为循环日志来缓解。
如果不起作用,进入下一步
2. 3重写入VS 1重写入
MQ默认的日志写入是3重写入。改为1重写入
这样可以节省大量Disk IO
如果还没有达到效果,进入下一步
3. 持久消息VS非持久消息
持久消息是要写的磁盘的文件里,且记日志(两次写磁盘)
非持久消息,不记日志,一般不会写到磁盘里,除非mq buffer不够用,放不下当前的消息,才会进入磁盘,(非持久消息只有在发不出去的情况下才丢掉,一般情况不会丢失),即一般情况不写磁盘
对于测试压力机,可以容许异常情况下丢报文,所以可以改为非持久消息,这样,又少了一次写IO。
4. 增大MQ buffer
上面提到“非持久消息,不记日志,一般不会写到磁盘里,除非MQ buffer不够用,放不下当前的消息,才会进入磁盘”。因此增大MQ Buffer也可以在某些压力情况下减少一次写IO。
本场景中,我们调整MQ buffer为10M。
(四) 效果
最后“磁盘最长活动时间”由100%变为10%以下,TPS大幅提高。
二、 压力机CPU 80~90%
(一) 问题
7台压力机,总计预计发送750笔报文/秒,但发现只能发出来500多笔报文/秒。
继续从PC的任务管理器->资源监视器,CPU、内存、网络、磁盘的分析入手。
这次,我们发现每台压力机CPU 80~90%,也就是说,磁盘IO的问题解决之后,CPU又变成了下一个瓶颈。
(二) 分析
这种情况下,一般是代码占用了过多的CPU。
分析代码发现,每一次性能测试工具的迭代(线程被调用),这个线程只处理一个MQ消息,即处理一个MQ消息需要打开、关闭一次MQ队列,这个打开、关闭队列是非常消耗CPU的。
(三) 解决
每次性能测试工具的迭代(线程被调用),让这个线程处理多个MQ消息。
问题来了,并不是每次迭代处理的越多越好,每次处理多少个MQ消息合适?
我们采用了 “当前队列深度”和“指定参数”的最小值。
为什么不是“当前队列深度”:设置为“当前队列深度”即每次迭代处理这个队列中所有的报文。那么如果队列深度很大(比如深度是100),这个线程要顺序处理这些消息,比较慢,其他线程得不到消息去处理,性能测试工具发挥不了并发处理的优势。
如果设置一个参数(比如10),每个线程每次最多处理10个消息,那么其他线程就有机会得到消息去并发处理。
因此,我们采用了 “当前队列深度”和“指定参数”的最小值。
(四) 效果
调整代码之后,预计发送750笔报文/秒,实际也真的发出来750笔报文/秒,不但如此,CPU由80-90%变为了30-60%,节约一半的CPU资源。
TPS提升50%,CPU降低一半,里外里,意味着TPS提升了200%(以前40%的CPU利用率支撑250TPS,现在是750TPS)
三、 场景跑完后,压力机CPU变为100%。
(一) 问题
场景跑的时候压力机 CPU 60-70%,跑完后,压力机CPU变为100%。
(二) 分析
这种情况一定是循环没有设置间隔。
或者是线程里面没有设置间隔,或者是线程的两次迭代之间没有设置间隔。经分析是线程的两次迭代之间没有设置间隔。
为什么最初没有设置间隔呢?因为这段代码的作用是实时抓取到达的报文并处理,如果设置间隔了就不那么实时了。
(三) 解决
设置间隔一定能解决这个问题,那么怎么设置呢?
1) 如果线程的两次迭代之间设置间隔,那么接收报文处理的环节就有一定的延时。不是我们想要的(人为的延长了响应时间)。
2) 在应用线程里面设置间隔。
如果有报文需要处理的时候,不设置时间延迟,实时抓取,没有报文的时候延迟20ms后再次读取队列。
处理方法为,判断队列深度,如果深度为0,则延迟20ms,不为0则不延时。
(四) 效果
修改代码后,场景跑完后CPU自然回落(100%变为10%以下)。
四、 内存耗尽
(一) 问题
PC机(4G内存)执行测试时,只有200M剩余,鼠标键盘操作非常缓慢。
(二) 分析
性能工具的JVM是预分配的1.5G,但实际上并没有用那么多
(三) 解决
把性能工具所占的jvm内存从1.5G调为1G。
(四) 效果
调整后,系统显示有840M可用内存,鼠标键盘操作比较灵活
从上面的4个问题的描述、分析和解决可以看出,有些问题需要些产品的知识,有些问题需要些代码的知识,完成一个性能测试会遇到各方面的问题,性能测试人员必须是多面手。
作者:杨建旭 出处:http://www.talkwithtrend.com/home/space.php?p=blog&t=&uid=898849&page=3 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。