adoop综合大作业 要求:
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
这次处理的文本是哈利波特之凤凰社英文长篇小说。

图2-1 分析的文本截图
操作:
1.开启Hadoop
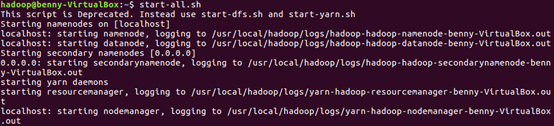
图2-2 启动hadoop截图
2.查询Hadoop开启情况
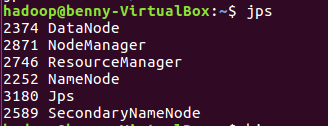
图2-3 hadoop开启情况截图
3. Hdfs上创建文件夹

图2-4 创建文件夹截图
4. 上传文件至hdfs

图2-5 上传文件截图
5.启动hive
图2-6 启动hive截图
6. 创建原始文档表

图2-7 创建文档表截图
7. 导入文件内容到表docs并查看

图2-8 导入文件截图
8. 进行词频统计,结果放在表word_count里
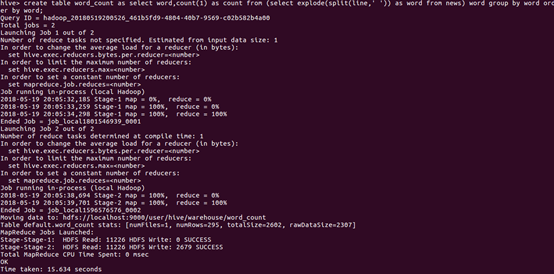
图2-9 词频统计截图
9.结果
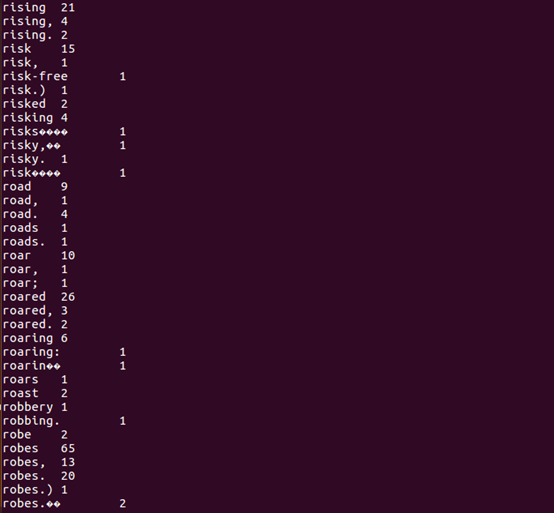
图2-10 部分结果截图
分析说明
从以上部分结果截图中可以看出,robes出现了65次,robe中文翻译是卢比,是哈利波特魔法世界的通用货币,统计发现robes出现了如此多次,说明在哈利波特世界中隐晦的表达了作者对于货币资本家的批判。
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果
爬虫大作业源代码:
import requests, re, pandas, time from bs4 import BeautifulSoup from datetime import datetime # 获取新闻细节 def getNewsDetail(newsUrl): time.sleep(0.1) res = requests.get(newsUrl) res.encoding = 'gb2312' soupd = BeautifulSoup(res.text, 'html.parser') detail = {'title': soupd.select('#epContentLeft')[0].h1.text, 'newsUrl': newsUrl, 'time': datetime.strptime( re.search('(d{4}.d{2}.d{2}sd{2}.d{2}.d{2})', soupd.select('.post_time_source')[0].text).group(1), '%Y-%m-%d %H:%M:%S'), 'source': re.search('来源:(.*)', soupd.select('.post_time_source')[0].text).group(1), 'content': soupd.select('#endText')[0].text} return detail # 获取一页的新闻 def getListPage(listUrl): res = requests.get(listUrl) res.encoding = "utf-8" soup = BeautifulSoup(res.text, 'html.parser') pagedetail = [] # 存储一页所有新闻的详情 for news in soup.select('#news-flow-content')[0].select('li'): newsdetail = getNewsDetail(news.select('a')[0]['href']) # 调用getNewsDetail()获取新闻详情 pagedetail.append(newsdetail) return pagedetail pagedetail = getListPage('http://tech.163.com/it/') # 获取首页新闻 for i in range(2, 20): # 因为网易新闻频道只存取20页新闻,直接设置20 listUrl = 'http://tech.163.com/special/it_2016_%02d/' % i # 填充新闻页,页面格式为两位数字字符 pagedetail.extend(getListPage(listUrl)) df = pandas.DataFrame(pagedetail) df.to_csv('news.csv')
创建用于存放csv数据目录:

把文件放入文件夹中

查看文件中的数据:
导入数据库表中

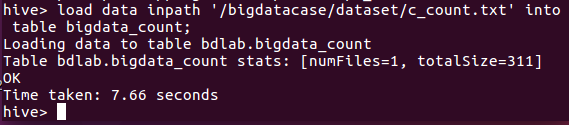
查看数据: