开发组在开发过程中,都不可避免地遇到了一些困难或问题,但都最终想出办法克服了。我们认为这样的经验是有必要记录下来的,因此就有了【技术博客】。
Pytorch代码生成经验文档
关于模型代码的生成,主要思路为从根节点开始进行广度优先搜索,从而自顶向下依次生成相关层的代码。这里和搜索相关的主要有三个数据结构:
- Q:队列,记录后续继续搜索的节点,即为后续的Node。
- graph:字典,记录整颗搜索树,每个key对应一个Node,Node为自己封装的一个类,里面包含每层的一些信息。记录搜索树的目的是为了后续的正确性验证,如下为Node的定义:
class Node:
def __init__(self, id = None, name = None, in_channels = 1, out_channels = 1, kernel_size = 3,
stride = 1, padding = 0, data = None, activity = None, pool_way = None, cat_dim = None):
self.fa = np.array([], dtype = str)
self.next = np.array([], dtype = str)
self.id = id
self.name = name
self.data = data
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.pool_way = pool_way
self.activity = activity
self.data_shape = np.array([], dtype = int)
self.cat_dim = cat_dim
def add_fa(self, f):
self.fa = np.append(self.fa, f)
def add_next(self, nx):
self.next = np.append(self.next, nx)
- done:字典,记录某节点相关代码是否已经生成,每个key对应一个boolean值。
同时还有以下需要关注的地方:
-
广度优先搜索。BFS为代码的主要框架。从’start’节点开始搜索,直到遍历结束,做一个线性的扫描。代码框架如下(省略了主要代码):
def make_graph(nets, nets_conn, init_func, forward_func): #code here Q = queue.Queue() Q.put(‘start’) #code here while not Q.empty(): cur_id = Q.get() if GL.done[cur_id]: continue '''''''''''' Main codes here '''''''''''' GL.done[cur_id] = True return init_func, forward_func -
关于全局变量的处理。由于一开始忽略了python变量的特性(不需要声明),所以在一开始第一全局变量的时候是直接定义在文件开头的,但是这样存在的问题是:如果在局部函数中引用全局变量,则此时则是重新定义了一个变量而不是引用,用global关键字代码看上去又很臃肿。所以采取的办法是重新定义了一个GLOB模块,里面存放着需要的所有全局变量。类似于这样:
class GLOB: def __init__(self): self.graph = {} self.done = {} self.layer_used_time = {'view_layer': 0, 'linear_layer': 0, 'conv1d_layer': 0, 'conv2d_layer': 0, 'element_wise_add_layer':0, 'concatenate_layer':0} self.nn_linear = 'torch.nn.Linear' self.nn_conv1d = 'torch.nn.Conv1d' self.nn_conv2d = 'torch.nn.Conv2d' self.nn_view = '.view' self.nn_sequential = 'torch.nn.Sequential' self.start_layer = ['start'] self.norm_layer = ['conv1d_layer', 'conv2d_layer', 'view_layer', 'linaer_layer'] self.multi_layer = ['element_wise_add_layer', 'concatenate_layer'] self.layers_except_start = self.norm_layer + self.multi_layer这样,只需要在代码里初始化一个GLOB对象GL,这样在任何地方引用全局变量都不会造成困扰。
-
关于变量名生成。每层的输出数据的名字格式为:层名 + “data_出现的次数”。有一个数据结构”layer_used_time”(字典)专门负责记录每个层出现的次数,同时,会在该层的代码生成结构后更新layer_used_time和done的值。
-
关于何时初始化和更新graph。在我们的代码中,当从队列中取出一个节点后会执行一个函数:get_next_nodes_and_update_pre_nodes()。该函数的目的是获取和初始化当前节点的儿子节点,记录前端传入该层的其他参数,更新其父子节点,同时返回当前节点的所有祖先节点代码是否已经生成完毕。另外,在该函数内部也会做模型的一部分正确性验证,主要验证搭建的模型里除了拼接层和相加层以外的层是否存在多个父节点或没有节点。该函数实现的功能较多,后期会考虑重构。
-
关于正确性验证。考虑到用户在搭建模型时不一定能够保证参数的正确,所以我们对参数的合理性是“宽容”的,但是也有硬性的要求,比如只能有一个开始节点,同时除了拼接层和相加层可以有多个父节点以外,其他层有且仅有一个父节点。
-
关于生成的模型NET中forward函数的返回值。由于搭建的模型允许出现网状结构,所以不能保证模型的出口只有一个,所以现阶段生成的模型会返回所有出度为0的层的输出值,具体顺序参见代码。
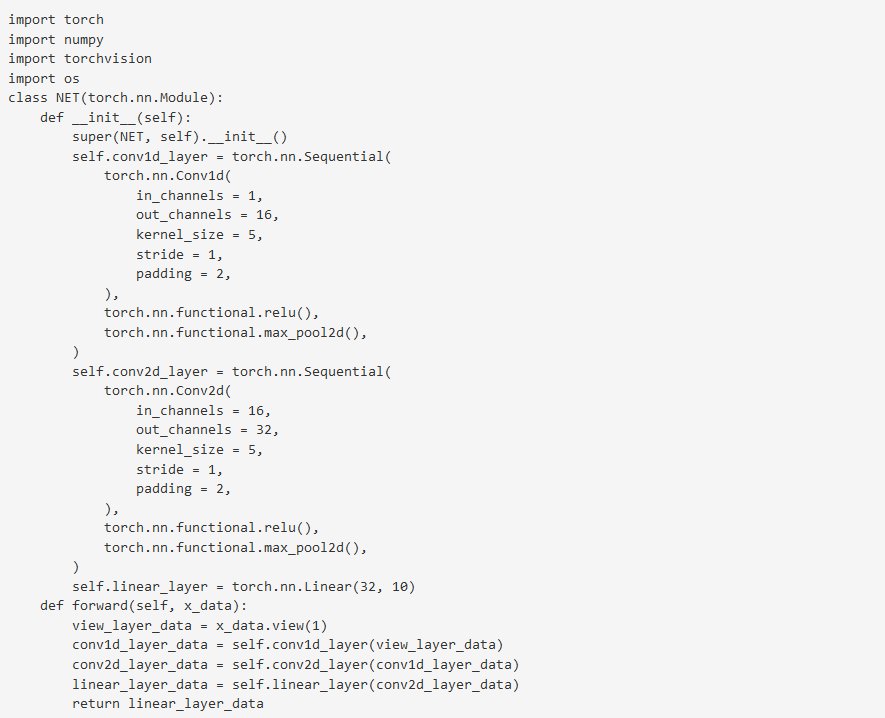
附最终生成的代码效果图(例):