20172304 实验四python综合实践报告
- 姓名:段志轩
- 学号:20172304
- 指导教师:王志强
- 课程:Python程序设计
- 实验时间:2020年5月13日至2020年6月14日
实验分析
本次是使用python来进行软件开发,python是一个有很多库的软件,提供了很多集成式的方法,可以很方便地实现很多操作。在本次实验的伊始,不自量力地想尝试游戏开发,在网上找到了一个植物大战僵尸的python源码,不过其内容较为繁琐,于是最后没有进行学习。后来又想尝试进行象棋游戏的开发。找到了一份象棋的c++源码,想要进行学习,最后败在了c++的格式上。最后还是回归了python应用最广泛的方面————爬虫。我将目光投向了b站。bilibili目前拥有动画、番剧、国创、音乐、舞蹈、游戏、科技、生活、娱乐、鬼畜、时尚等分区,并开设直播、游戏中心、周边等业务板块,是目前国内最大的二次元综合娱乐社区平台。于是就决定八一八b站的数据。
实验设计
本次实验扒取的数据主要是b站的视频排行榜上的100个视频的相关数据。主要数据有视频AV号,视频BV号,弹幕id,作者id,作者名称,投币数,视频时长,播放量,综合评分,视频标题,重放次数等。还有就是将视频对应的弹幕扒取下来并进行简单的分析(弹幕随秒数分布图),以及弹幕组成的词云图等等。
实验实现
1.首先当然是是找到数据的来源,打开哔哩哔哩网址,点击搜索榜。
2.按下Fn+F12,进入浏览器的控制台。
3.当然,此时其内部只是一片空白,此时还需要进行刷新来重新加载数据,按下F5,你会发现新世界。
4.再点击全站标签,在Filter中输入json,你会发现名为ranking?rid=0&day=3&type=1&arc_type=0&jsonp=jsonp&callback=__jp0的一个东西,点击它,并在新生成的窗口中选择preview标签,将所有隐藏的子标签打开。你会发现所有视频的信息。
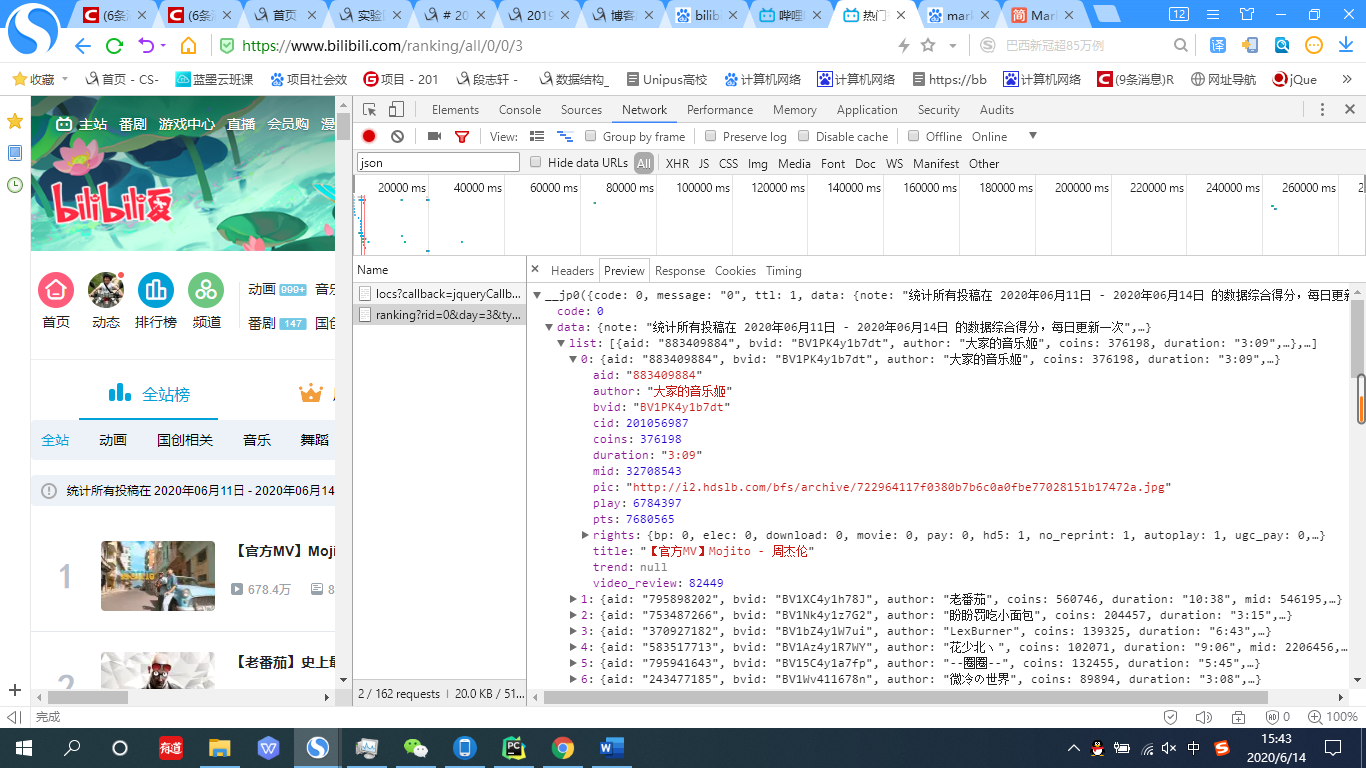
5.初步的目的就达成了,获得了可以用来爬取b站全站排行榜的网址:https://api.bilibili.com/x/web-interface/ranking?rid=0&day=3&type=1&arc_type=0
6.初步进行功能实现。
这段代码比较简单主要就是通过给定的网址获取json字符串,headers的作用主要是为了欺骗浏览器以达到伪装自己是从浏览器发出的请求。方法最后返回的是对应的json。
def get_json():
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
url = 'https://api.bilibili.com/x/web-interface/ranking?rid=0&day=3&type=1&arc_type=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
}
res = requests.get(url,headers=headers,timeout=3)
res.raise_for_status()
res.encoding = 'zh'
page_data = res.json()
print('请求响应结果:', page_data, '
')
return page_data
7.接下来要介绍一下json中内容的获取。首先在浏览器控制台中查看json的数据格式。最后了解到需要的数据在json中的data.list下。
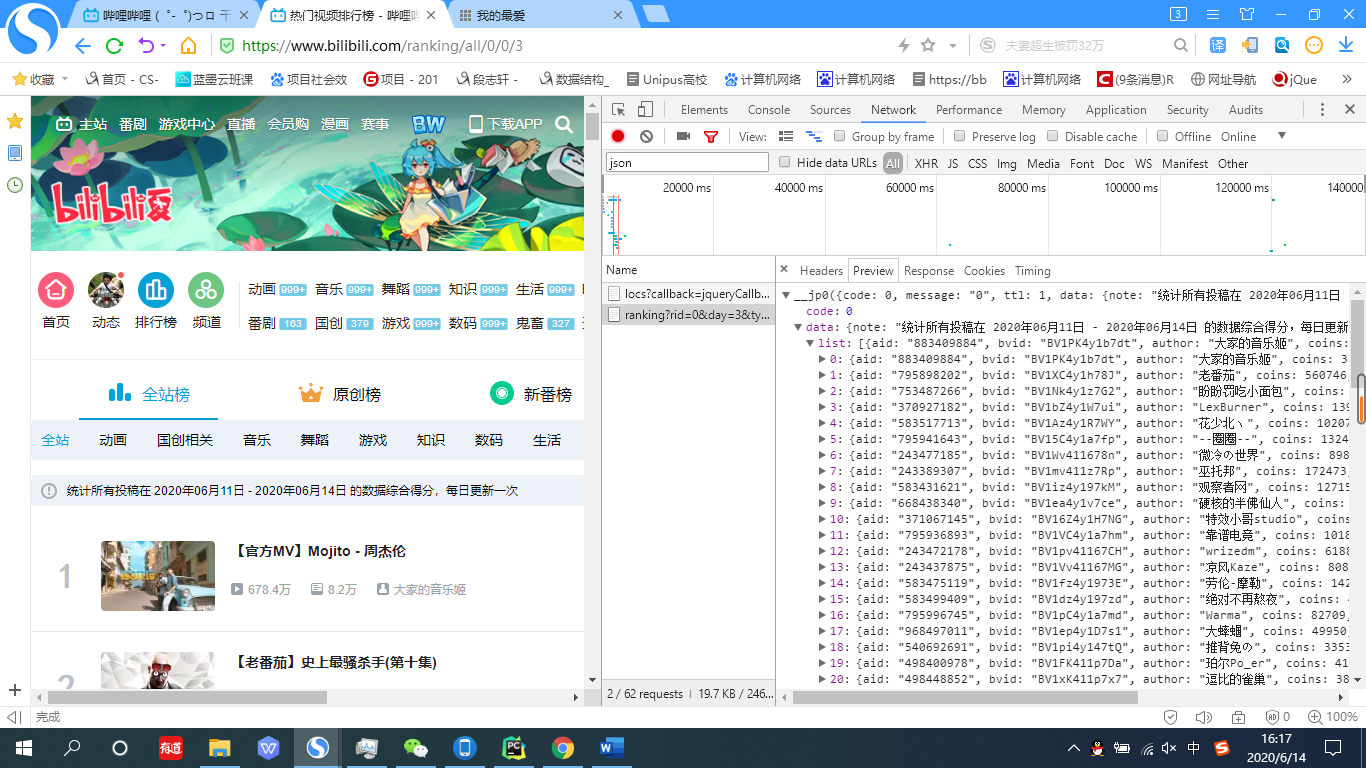
于是便有了如下的代码,此时data就是一个存放着各个视频信息的字典的列表了。
page_data = get_json() # 获取响应json
bilibili_list = page_data['data']['list']
data = get_data(bilibili_list)
8.然后就是获取列表中的值了。
通过如下代码,将字典中的值提取出来,存到一个列表中。
def get_data(bilibilis_list):
page_info_list = []
for i in bilibilis_list:
bilibili_info = []
bilibili_info.append(i['aid'])#从名称来看应该是作者的id
bilibili_info.append(i['bvid'])#从名称来看应该是作品的id
bilibili_info.append(i['cid']) # 这个是弹幕的id
bilibili_info.append(i['mid']) #这个是作者的id
bilibili_info.append(i['author'])#作者名称
bilibili_info.append(i['coins'])#z作品投币数
bilibili_info.append(i['duration'])#视频时长
bilibili_info.append(i['play'])#播放量A
bilibili_info.append(i['pts'])#这个东西在网络后台进行了初步的对比,初步判定为是b站进行综合排名的数据,不过算法应该是b站的不传之密。
bilibili_info.append(i['title'])#毫无疑问这就是视频的标题了
bilibili_info.append(i['video_review'])#这个标签我觉得是b站进行数据分析的一个选项,应该是重播次数,不过这只是猜测,毕竟也不知道当初人家是怎么设计的
page_info_list.append(bilibili_info)
return page_info_list
9.最后将由存储着各个视频信息的列表的列表通过pandas存放到pandas的dataframe数据结构中,这个就很人性化我觉得,这个dataframe是pandas包中的一个数据结构,是一个二维的数据结构,类似于表格,最后通过pandas自带的命令存入csv文件中,scv文件是一个二维的文件,其通用性比较强,可以比较容易地导入到excel中。
df = pd.DataFrame(data=data,
columns=['视频AV号', '视频BV号','弹幕id' ,'作者id','作者名称', '投币数', '视频时长', '播放量', '综合评分', '视频标题', '重放次数'])
df.to_csv('Bilibili_Data_engineer.csv', index=False)
print('bilibili排行榜信息已保存')
10.拿到数据之后,第一步算是初步完成了。接下来利用爬到的数据来获取弹幕数据。
从网络取得数据的部分就不在进行讲解了,接下来讲解利用已经获取的数据来获取弹幕,在之前获取的数据中,有一列数据是用来标明弹幕的,就是在之前的代码中的弹幕id,这个爬取弹幕我也借鉴过网上的帖子,不过在经历过多次尝试之后,还是没能找到各个教程中提及的xml文件。最后还是直接引用了教程中提供的网址。https://comment.bilibili.com/+弹幕id+.xml的方式获取到了弹幕资源
def main():
df = pd.read_csv('Bilibili_Data_engineer.csv',encoding='utf-8')
result_dic = df['弹幕id']
result_dic1 = df['视频AV号']
result_dic = list(result_dic)
result_dic1 = list(result_dic1)
bullet_screen = []
像这段代码,其作用就是将之前爬取的视频信息加以利用,df[x]这个方法可以直接通过存储的列名来调用列,最后返回的应该是series类型,series类型是pandas包定义的一个一维数据结构。可以通过list(series)方法直接将其转化为python中的list结构,这里我就进行了转化并获得了两个列表,其中分别存储着弹幕id以及与之对应的视频av号。提到av号,这是之前bilibili创建时为了迎合主流而采取的视频标识码,而随着b站(b友们亲切的称呼其为小破站)的不断强大,其自己制定了符合自己规则的视频码bv号。用两个识别码都可以唯一识别视频(亲测有效)。
给大家展示一下b站存储弹幕的xml文件的层级结构。

接下来就是要将数据从xml中提取出来了。对于python提取xml文件中的内容其实我本人也不是很了解,于是就援引了官方的例子。
for i,i1 in zip(result_dic,result_dic1):
page_data_2 = get_bullet_screen(i)
xml = page_data_2.decode()
root = ET.fromstring(xml)
for neighbor in root.iter('d'):
d = neighbor.text
if "SimHei" in d:
d=d.replace("[","")
d=d.replace("]","")
m = d.split(",")
d = m[4]
p = neighbor.attrib
str = p.get('p')
其实例大致如上,大致给大家讲解一下,ET是引用的包的化用,root就是xml文件的根节点,而root.iter则是一个通过名称查找来返回子标签的列表的一个方法。在这里我就返回了存有弹幕内容的标签d。这里在给大家讲解一下,这个if "SimHei" in root.iter的作用。因为就是之前在博文中提到的弹幕类型导致的。

如图,在前几个标签的p属性中的第二个数值都是7,这就对应了之前提到的网上给出的数据类型,其中第二个字段对应的就是弹幕类型,而当这个数值等于7的时候,表示特殊弹幕,此时d标签里的内容不再是文本了,而是一个列表,至于这个列表怎么使用无从得知。所以需要一个结构来清洗这部分数据,使其只剩下弹幕内容部分。也就是列表中对应的第五个元素,这样在之后生成词云图的时候就不会产生干扰了。接下来的内容就比较简单了将获得的数据存入dataframe结构中。使用pandas包中的.to_csv方法来将其写入到文件中。
list12 = str.split(',')
list12.append(d)
list12.append(i1)
bullet_screen.append(list12)
print(result_dic)
df = pd.DataFrame(data = bullet_screen,columns=['出现时间','弹幕模式','字号','字体颜色','时间戳','弹幕池','发送者id','历史弹幕','弹幕内容','作品id'])
#p 字段内容的含义,内容来自于网络
#第一个参数是弹幕出现的时间以秒数为单位。第二个参数是弹幕的模式1..3滚动弹幕4 5顶端弹幕6.逆向弹幕7精准定位8高级弹幕第三个参数是字号, 12
# 非常小, 16
# 特小, 18
# 小, 25
# 中, 36
# 大, 45
# 很大, 64
# 特别大
# 第四个参数是字体的颜色以HTML颜色的十进制为准第五个参数是Unix格式的时间戳。基准时间为1970 - 1 - 1 08: 00:00第六个参数是弹幕池
# 0普通池
# 1字幕池
# 2特殊池【目前特殊池为高级弹幕专用】
# 第七个参数是发送者的ID,用于“屏蔽此弹幕的发送者”功能
# 第八个参数是弹幕在弹幕数据库中rowID
# 用于“历史弹幕”功能。
df.to_csv('bilibili_bullet_screen.csv',index=False)
展示一下生成的数据
11.接下来的程序就是将得到的数据继续拿给你可视化了。这部分我主要采取的是pyechart包,因为这个包是国人进行开发的,在api的阅读上有着极强的友好度。我总共生成了两个图,一个是柱状图,是用来描述时间和弹幕数量的关系。时间采用的是整数非连续型。
让我来逐一讲解代码
这些进行画图所用的方法都在draw_graph.py文件中.
def get_data(aid):
df = pd.read_csv('bilibili_bullet_screen.csv')
print(df.columns)
grouped = df.groupby('作品id')
list = grouped.get_group(aid)
list1 = list['出现时间'].tolist()
list2 = []
上面这部分代码就是通过视频的aid来进行分组,就是将视频id相同的放在一个组里,这样是为了获取一个视频的所有弹幕。groupby这种通用的就不说了。使用groupby方法之后实际返回的类型应该是dataframegroup和dataframe类似。之后通过get_group获取aid为输入进来的视频的分组。
print(list1)
for i in list1:
new = math.floor(i)
list1.remove(i)
list2.append(new)
print(list2)
result = Counter(list2)
这一步做了一个处理,主要是获得的视频出现的时间不是整秒数,需要通过向下取整转化为正数,然后通过Counter来统计弹幕出现描述重复次数并返回Counter类型,这个Counter类型和字典类型比较相似。
list3 = []
for key, value in result.items():
list3.append((key, value))
list3.sort(key=lambda tup: tup[0])
list4 = []
list5 = []
for x, y in list3:
list4.append(x)
list5.append(y)
list6 = (list4, list5)
return list6
统计出弹幕在同一秒出现的次数之后,在使用for循环将其组成字典,然后按照出现时间从小到大排序,最后将字典的key和value分别存入列表中。最后返回一个含有key和value列表的列表。
12.接下来其实就可以考虑画柱形图了。
下面这个方法就是画柱形图的方法了。 .add_xaxis()方法是添加横轴数据的方法,将之前生成的时间和弹幕数量的两个列表进行传入,再传入标题。 .add_yaxis()方法就是添加y轴数据的方法,同样是传入一个列表。 set_global_opts()中的第一行代码主要功能就是将x周上的数据旋转15度。第二行就是设置标题。第三行就是在柱形图的下面添加一个调节条。
def draw_graph(list1,list2,title):
c = (
Bar()
.add_xaxis(
list1
)
.add_yaxis("每秒弹幕条数", list2)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title=title+"柱状图"),
datazoom_opts=opts.DataZoomOpts(),
)
.render(title+"_bar"+".html")
)
return c
生成的柱形图如下:

13.接下来进行的步骤就是通过视频号来获取弹幕内容,通过jieba进行分词,然后使用Counter来统计词频,最后返回一个列表
def get_words(aid):
df = pd.read_csv('bilibili_bullet_screen.csv')
print(df.columns)
grouped = df.groupby('作品id')
list8 = grouped.get_group(aid)
list1 = list8['弹幕内容'].tolist()
list2 = [str(i) for i in list1]
txt = "".join(list2)
seg_list = jieba.cut(txt)
c = Counter()
for x in seg_list:
if len(x) > 1 and x != '
':
c[x] += 1
c1 = dict(c)
return c1
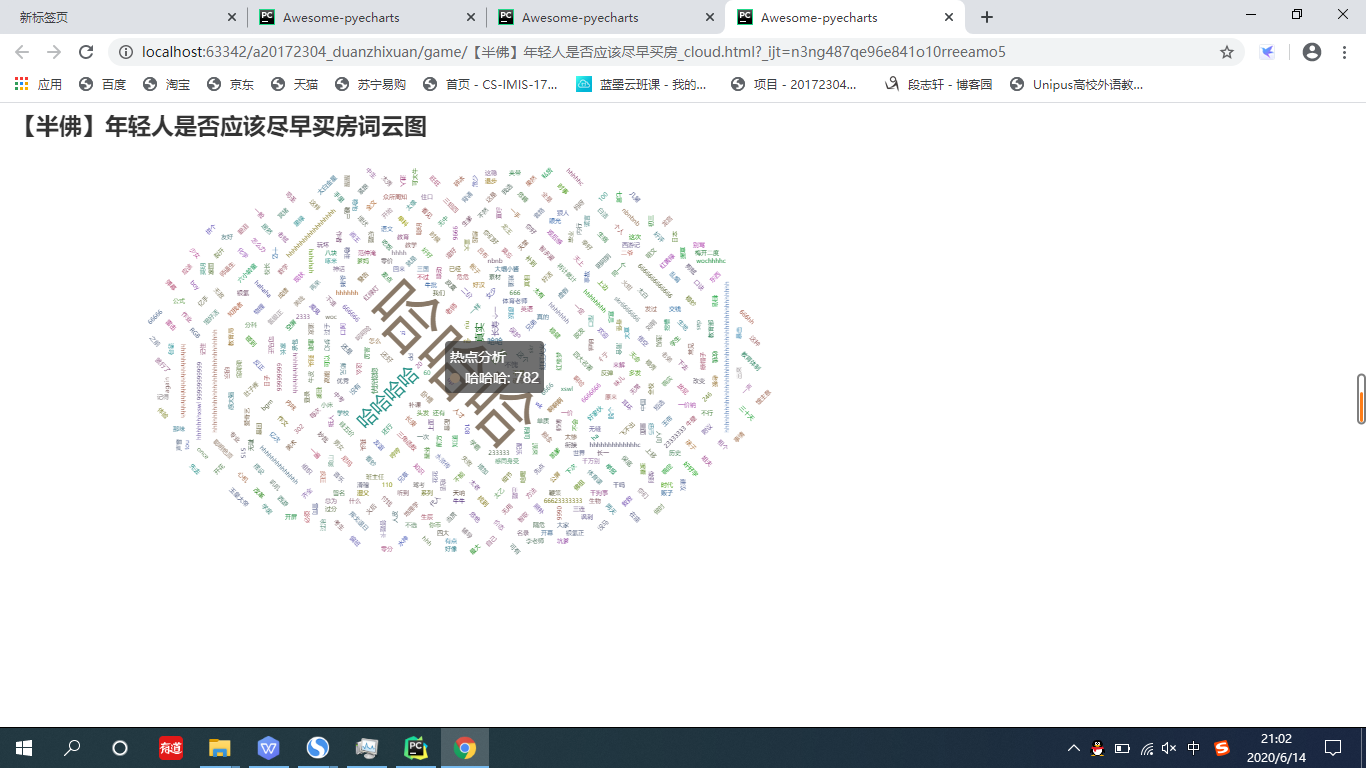
14.下面是生成词云图的方法
将刚才生成的词频字典进行传入,在下列代码中,WordCloud()类是生成词云图的类,add方法中第一个是传入的名称,第二个是存储着词频信息的字典,第三个参数是字体大小的范围。title_opts一项中是对词云图的标题进行设置,在这里我选择了使用视频的标题,并将其字体大小设置为23。
def draw_cloud_picture(text,title):
wc=(
WordCloud()
.add(series_name="热点分析", data_pair=text, word_size_range=[6, 66])
.set_global_opts(
title_opts=opts.TitleOpts(
title=title+"词云图", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
to、oltip_opts=opts.TooltipOpts(is_show=True),
)
.render(title+"_cloud"+".html")
)
return wc
生成的词云图如下:
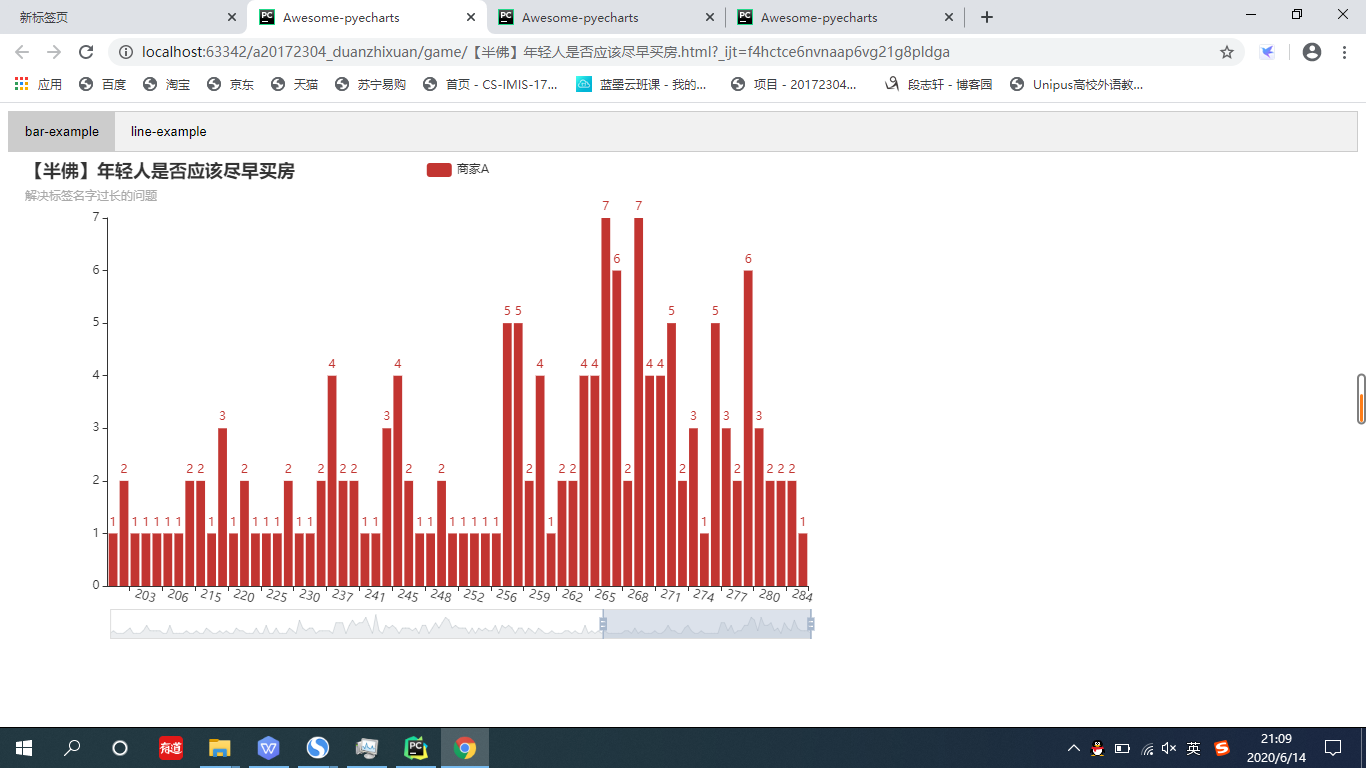
15.然后我考虑了将两张图放在一下,于是使用了pyechart中的多图展示类,tab。
这个就比较简单了,就是先声明两个图类,然后使用add进行添加。
tab = Tab()
tab.add(c,"bar-example")
tab.add(wc,"line-example")
tab.render(title+".html")
最后生成的图如下

实验结果展示及源码链接
生成弹幕文件
生成排行榜视频信息文件
[码云链接](https://gitee.com/python_programming/a20172304_duanzhixuan/tree/master/game)
其中bili.py文件是用于爬取近三天排行榜前一百的视频的数据的
bilibilibullet_screen.py文件时用于爬取弹幕视频的。
Bilibili_data_engineer.csv是用来存储生成的视频的数据的。
bilibili_bullet_screen.csv是用来存储生成的弹幕数据的。
实验感想及建议
又上了王老师的课有时熟悉的味道,严肃而又活泼,一板一眼的讲解中不时穿插着令人轻松的话语。不过给我的感觉比学java的时候要轻松了不少。感觉还是紧张一些的好,熟能生巧,书上的一千行代码不如自己手打的一百行代码,老师的讲解比较到位,答疑也很及时,就是希望老师能够多布置一些任务。这样才能让我们掌握更多的东西。