day63
参考:http://www.cnblogs.com/wupeiqi/articles/5713323.html
索引
作用:
- 约束
- 加速查找
索引:
- 主键索引:加速查找 + 不能为空 + 不能重复
- 普通索引:加速查找
- 唯一索引:加速查找 + 不能重复 (可以为空)
- 联合索引(多列):
- 联合主键索引
- 联合唯一索引
- 联合普通索引
加速查找:
快:
select * from tb where name='asdf'
select * from tb where id=999
假设:
id name email (列名称)
...
...
..
无索引:从前到后依次查找,速度慢
索引:
id 创建额外文件(某种格式存储)
name 创建额外文件(某种格式存储)
email 创建额外文件(某种格式存储) create index ix_name on userinfo3(email);
name email 创建额外文件(某种格式存储)
如:
未创建索引前:

创建索引后:

可以看出创建索引后,速度加快.
建立索引:
- a. 额外的文件保存特殊的数据结构、
- b. 查询快;插入更新删除慢 (插入时表会更新,索引表也会被更新,所以速度慢)
- c. 命中索引
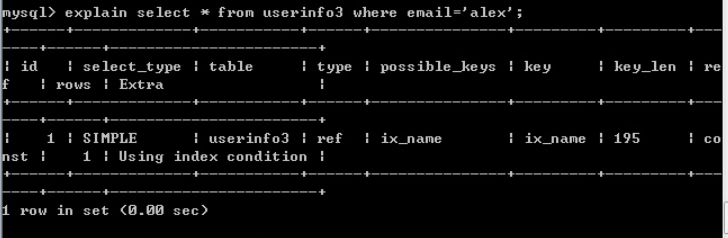
select * from userinfo3 where email='asdf'; (命中索引)
select * from userinfo3 where email like 'asdf'; (用法不当,未命中索引) 慢
...
主键索引:
主键有两个功能:加速查询 和 唯一约束(不可含null)


create table in1(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text,
index ix_name (name)
)
OR
create table in1(
nid int not null auto_increment,
name varchar(32) not null,
email varchar(64) not null,
extra text,
primary key(ni1),
index ix_name (name)
)
alter table 表名 add primary key(列名);
alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key;
普通索引:仅加速查找
可在创建表时创建,也可单独创建
create table in1(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text,
index ix_name (name)
)
create index index_name on table_name(column_name)
drop index_name on table_name;
- create index 索引名称 on 表名(列名,)
- drop index 索引名称 on 表名
唯一索引:两个功能 加速查询 和 唯一约束(可含null)
可在创建表时创建,也可单独创建
create table in1(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text,
unique ix_name (name)
)
create unique index 索引名 on 表名(列名)
drop unique index 索引名 on 表名
组合索引
组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where n1 = 'alex' and n2 = 666。
create table in3(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text
)
create index ix_name_email on in3(name,email);
最左前缀匹配
select * from userinfo3 where name='alex' and email='asdf'; (支持索引)
select * from userinfo3 where name='alex'; (支持索引)
select * from userinfo3 where email='alex@qq.com';(不支持索引)
覆盖索引:
- 在索引文件中直接获取数据

- 把多个单列索引合并使用
组合索引
- (name,email,)
select * from userinfo3 where name='alex' and email='asdf';
select * from userinfo3 where name='alex';
索引合并: (两单列索引)
- name
select * from userinfo3 where name='alex' and email='asdf';
select * from userinfo3 where name='alex';
select * from userinfo3 where email='alex';
- 创建索引
- 命中索引 ***** (索引失效)
- like '%xx'
select * from tb1 where email like '%cn';(数据量少的时候)
- 使用函数
select * from tb1 where reverse(email) = 'wupeiqi';(会用函数将所有数据计算一遍,才能判断)
- or
select * from tb1 where nid = 1 or name = 'seven@live.com';(nid是索引而name非索引则无法命中索引,速度慢)
特别的:当or条件中有未建立索引的列才失效,以下会走索引
select * from tb1 where nid = 1 or name = 'seven@live.com' and email = 'alex'(nid和email是索引,name不是)
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然...
select * from tb1 where email = 999;(慢) select * from tb1 where email = '999';(快) 虽然两者都找不到
- !=
select * from tb1 where email != 'alex'
特别的:如果是主键,则还是会走索引
select * from tb1 where nid != 123
- >
select * from tb1 where email > 'alex'
特别的:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123
select * from tb1 where num > 123
- order by
select name from tb1 order by email desc; (映射是name,不是索引,不是email,不走索引)
当根据索引排序时候,选择的映射如果不是索引,则不走索引
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc;
- 组合索引最左前缀
如果组合索引为:(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
id,email
慢:
select * from userinfo3 where name='alex'
explain select * from userinfo3 where name='alex'(name无索引)
type: ALL(全表扫描)
select * from userinfo3 limit 1;
快:
select * from userinfo3 where email='alex'(email有索引)
type: ref(走索引)