序列化
参考:https://www.cnblogs.com/yuanchenqi/articles/5732581.html
1 # dic = str({'1':'111'}) 2 # 3 # f = open('test', 'w') 4 # f.write(dic) #必须是str类型,不是set 5 6 file = open('test', 'r') 7 data = file.read()#data是字符串 8 print(eval(data)['1'])#用eval将字符串类型的data转成dict类型 9 10 print(type(data)) 11 print(type(eval(data)))
执行被注释的程序可得如下文件:
{'1': '111'}
执行未被注释的文件可得:
111 <class 'str'> <class 'dict'> Process finished with exit code 0
可以看出需要通过eval将字符串类型的数据转成dict类型的。
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
1、json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串)
(1)json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2)json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
2、json.dump()和json.load()主要用来读写json文件函数
参考:https://www.cnblogs.com/xiaomingzaixian/p/7286793.html
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
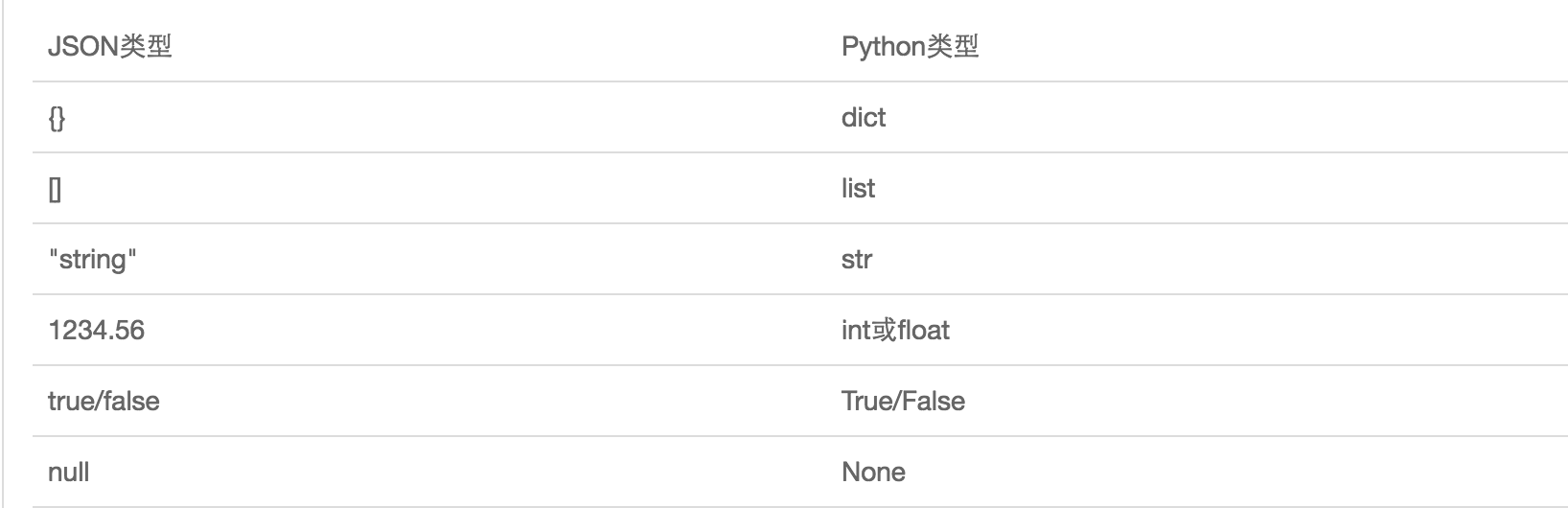
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
json_test.py(序列化)
1 import json 2 3 dict = {'name':'nizhipeng','age':'18'} 4 5 data = json.dumps(dict)#添加序列化内容 6 f = open('JSON_text', 'w') 7 f.write(data) 8 f.close()
生成文件JSON_test
{"age": "18", "name": "nizhipeng"}
JSON_load.py(反序列化)
1 import json 2 3 f = open('JSON_text', 'r') 4 5 data = f.read() 6 7 data = json.loads(data) 8 9 print(data['name'])
执行结果:
1 nizhipeng 2 3 Process finished with exit code 0
Pickle
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
pickle_test.py
1 import pickle 2 3 def foo(): 4 print('ok') 5 6 data = pickle.dumps(foo)#添加序列化内容 7 f = open('pickle_text', 'wb') #b为二进制 8 f.write(data) 9 f.close()
生成pickle_text
pickle_load.py
1 import pickle 2 3 def foo():#必须有 4 print('ok') 5 6 7 f = open('pickle_text', 'rb')#二进制形式 #注意是w是写入str,wb是写入bytes,j是'bytes' 8 9 data = f.read() 10 11 print(type(data)) 12 13 data()
执行结果:
<class 'function'> ok Process finished with exit code 0
pickle可将函数序列化(只需了解一下)。但是函数内存地址已发生改变,所以需要在pickle_load.py处,重新再写一遍。
简化的方法dump,load
json_test.py
1 import json 2 3 dict = {'name':'nizhipeng','age':'18'} 4 f = open('json_text', 'w') 5 6 # data = json.dumps(dict)#添加序列化内容 7 # f.write(data) 8 9 json.dump(dict, f)#等价于以上两行 10 11 f.close()
用dump代替dumps。
生成json_text文件。
json_load.py
1 import json 2 3 f = open('json_text', 'r') 4 5 # data = f.read() 6 # data = json.loads(data) 7 8 data = json.load(f)#等价与以上两步 9 10 print(data['name'])
执行结果:
nizhipeng
Process finished with exit code 0
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
1 import shelve 2 3 f = shelve.open('shelve_text') 4 5 # 6 f['info'] = {'name':'nizhipeng', 'age':'18'} 7 f['shopping'] = {'name':'alex', 'price':'-18'} 8 9 data = f.get('info') #info是键 10 print(data)
执行会生成一个shelve_text文件
{'name': 'nizhipeng', 'age': '18'}
Process finished with exit code 0
补充(字典)
1 d = {'name':'nizhipeng', 'age':'18'} 2 print(d['name']) 3 print(d.get('name')) 4 5 print(d.get('sex', 'male'))#如果没有则返回后面的内容,本身没有sex键
执行结果:
nizhipeng
nizhipeng
male
Process finished with exit code 0