一、协同过滤算法简介
协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。也就是常见的“猜你喜欢”,和“购买了该商品的人也喜欢”等功能。它的主要实现由:
●根据和你有共同喜好的人给你推荐
●根据你喜欢的物品给你推荐相似物品
●根据以上条件综合推荐
因此可以得出常用的协同过滤算法分为两种,基于用户的协同过滤算法(user-based collaboratIve filtering),以及基于物品的协同过滤算法(item-based collaborative filtering)。特点可以概括为“人以类聚,物以群分”,并据此进行预测和推荐。
二、协同过滤算法的关键问题
实现协同过滤算法,可以概括为几个关键步骤:
1:根据历史数据收集用户偏好
2:找到相似的用户(基于用户)或物品(基于物品)
三、基于用户的协同过滤算法描述
基于用户的协同过滤算法的实现主要需要解决两个问题,一是如何找到和你有相似爱好的人,也就是要计算数据的相似度:
计算相似度需要根据数据特点的不同选择不同的相似度计算方法,有几个常用的计算方法:
(1)杰卡德相似系数(Jaccard similarity coefficient)
其实就是集合的交集除并集
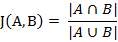
(2)夹角余弦(Cosine)
在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
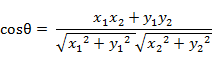
两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦:
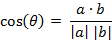
即 
(3)其余方法,例如欧式距离、曼哈顿距离等相似性度量方法可以点此了解
找到与目标用户最相邻的K个用户
我们在寻找有有相同爱好的人的时候,可能会找到许多个,例如几百个人都喜欢A商品,但是这几百个人里,可能还有几十个人与你同时还喜欢B商品,他们的相似度就更高,我们通常设定一个数K,取计算相似度最高的K个人称为最相邻的K个用户,作为推荐的来源群体。
这里存在一个小问题,就是当用户数据量十分巨大的时候,在所有人之中找到K个基友花的时间可能会比较长,而且实际中大部分的用户是和你没有什么关系的,所以在这里需要用到反查表
所谓反查表,就是比如你喜欢的商品有A、B、C,那就分别以ABC为行名,列出喜欢这些商品的人都有哪些,其他的人就必定与你没有什么相似度了,从这些人里计算相似度,找到K个人
通过这K个人推荐商品
我们假设找到的人的喜好程度如下
| 你 | A | B | C | D |
| 甲(相似度25%) | √ | √ | √ | |
| 乙(相似度80%) | √ | √ |
那么对于产品ABCD,推荐度可以计算为:
●A:1*0.25=0.25
●B:1*0.25=0.25
●C:1*0.8=0.8
●D:1*0.25+1*0.8=1.05
很明显,我们首先会推荐D商品,其次是C商品,再后是其余商品
当然我们也可以采用其他的推荐度计算方法,但是我们一定会使用得到的相似度0.25和0.80,也即一定是进行加权的计算。
算法总结
这就是基于用户的协同推荐算法,总结步骤为
1.计算其他用户的相似度,可以使用反查表除掉一部分用户
2.根据相似度找到与你嘴相似的K个用户
3.在这些邻居喜欢的物品中,根据与你的相似度算出每一件物品的推荐度
4.根据相似度推荐物品
算法存在的问题
例如一段时间内非常流行的某种商品,或者某种通用的商品,购买的人非常多,此时如果列入正常计算过程中就没有太大意义了,并且会增加负担。可以给此种商品价一个权值或者在数据预处理阶段作为脏数据处理掉。
四、算法实现
先整理网上的资料,自己动手实践后再进行编辑
我们使用的是集成在CDH集群上的spark-on-yarn方式,使用python写算法,这是在集群上运行程序的方式以及一些问题解决
在集群上运行python编写的spark应用程序时遇到的一些问题
测试1——我们自己测试的基于Python的协同过滤算法实践
主要实现由读取Hive中的数据并进行算法处理(python + spark + hive)
第一步:建立Hive的连接,并读取Hive中的数据(sql方法)
第二步:划分训练集和测试集(0.8,0.2)
第三步:利用ALS函数,设置参数,并通过训练集训练得到模型
第四步:利用测试集对训练好的模型进行测试
第五步:最后将编好的.py文件上传至服务器
第六步:使用./spark-submit –master yarn /program/wsh/readTpch1.py提交至spark进行处理。
注:通过训练测试(几千万条数据),运行了40分钟左右。由于时间较长,这此没有等上截图,具体看代码。
代码:
from pyspark.sql import HiveContext, SparkSession from pyspark.ml.evaluation import RegressionEvaluator from pyspark.ml.recommendation import ALS from pyspark.sql import Row ''' 基于spark的算法程序,在本地是不能直接运行的,将.py程序上传至服务器,进而使用spark-submit 将程序提交给spark进行处理,并得到结果 ''' #初始化 spark = SparkSession.builder.master("local").appName("WordCount").getOrCreate() hive_context = HiveContext(spark) #切换数据库至tpch hive_context.sql('use tpch') #SQL语言 sql = "select p_brand, p_type, p_size, count(distinct ps_suppkey) as supplier_cnt from partsupp, part where p_partkey = ps_partkey and p_brand <> '[BRAND]' and p_type not like '[TYPE]%' and ps_suppkey not in (select s_suppkey from supplier where s_comment like '%Customer%Complaints%') group by p_brand, p_type, p_size" #执行SQL语句,得到结果。该结果为DataFrame df = hive_context.sql(sql) #展示结果 df.show() rows = df.collect() #切分训练集和测试集 training, test = df.randomSplit([0.8, 0.2]) #使用pyspark.ml.recommendation包下的ALS方法实现协同过滤算法,并设置参数 alsExplicit = ALS(maxIter=10, regParam=0.01, userCol="supplier_cnt", itemCol="p_brand", ratingCol="p_size") #训练并得到模型 modelExplicit = alsExplicit.fit(training) #利用测试集对模型进行检测 predictionsExplicit = modelExplicit.transform(test) #结果展示 predictionsExplicit.show() evaluator = RegressionEvaluator().setMetricName("rmse").setLabelCol("rating").setPredictionCol("prediction") rmse = evaluator.evaluate(predictionsExplicit) print("Explicit:Root-mean-square error = " + str(rmse)) print("Explicit:Root-mean-square error = " + str(rmse))
测试2——这是网上别人的代码用来跑了一下
我们使用MovieLens数据集,其中每行包含一个用户、一个电影、一个该用户对该电影的评分以及时间戳。
使用默认的ALS.train() 方法,即显性反馈(默认implicitPrefs 为false)来构建推荐模型并根据模型对评分预测的均方根误差来对模型进行评估。
导入需要的包
from pyspark.ml.evaluation import RegressionEvaluator from pyspark.ml.recommendation import ALS from pyspark.sql import Row
根据数据结构创建读取示范
创建一个函数,返回即[Int, Int, Float, Long]的对象
def f(x): rel = {} rel['userId'] = int(x[0]) rel['movieId'] = int(x[1]) rel['rating'] = float(x[2]) rel['timestamp'] = float(x[3]) return rel
读取数据
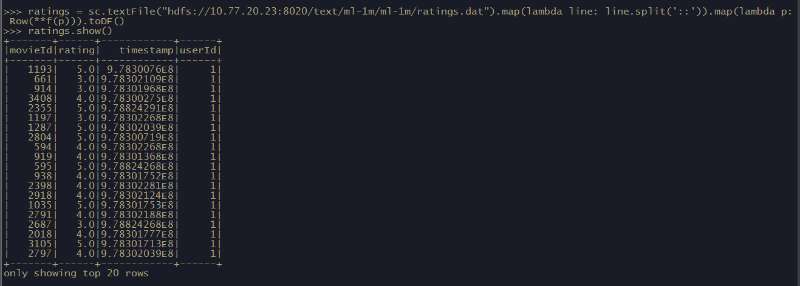
ratings = sc.textFile("hdfs://10.77.20.23:8020/text/ml-1m/ml-1m/ratings.txt").map(lambda line: line.split('::')).map(lambda p: Row(**f(p))).toDF()
然后把数据打印出来:
构建模型
training, test = ratings.randomSplit([0.8,0.2])
使用ALS来建立推荐模型,这里我们构建了两个模型,一个是显性反馈,一个是隐性反馈
alsExplicit = ALS(maxIter=5, regParam=0.01, userCol="userId", itemCol="movieId", ratingCol="rating") alsImplicit = ALS(maxIter=5, regParam=0.01, implicitPrefs=True,userCol="userId", itemCol="movieId", ratingCol="rating")
接下来,把推荐模型放在训练数据上训练:
modelExplicit = alsExplicit.fit(training)
modelImplicit = alsImplicit.fit(training)
模型预测
使用训练好的推荐模型对测试集中的用户商品进行预测评分,得到预测评分的数据集
predictionsExplicit = modelExplicit.transform(test)
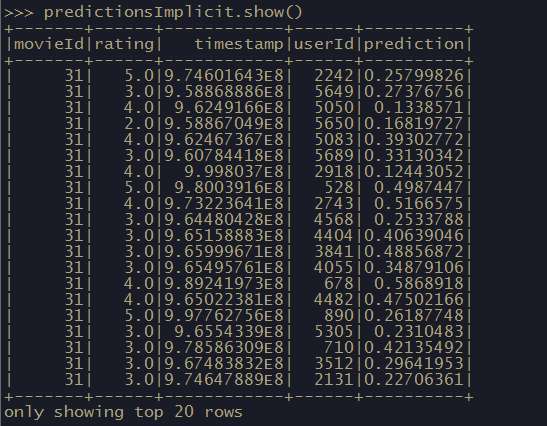
predictionsImplicit = modelImplicit.transform(test)
输出结果
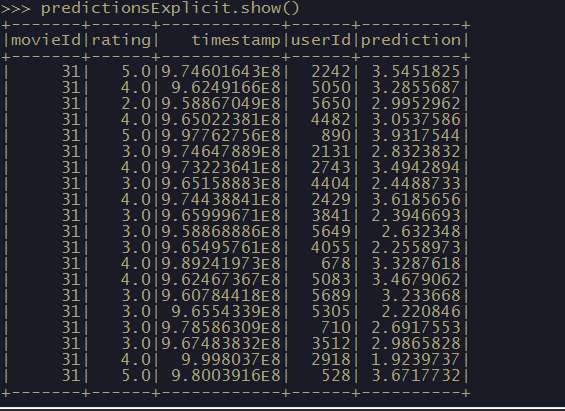
对比真实结果与预测结果
以上示例来自于 http://dblab.xmu.edu.cn/blog/1781-2/
python实现的电影推荐的协同过滤算法其他实例代码