awk -F " " '{print $1}' access.log |uniq -c|sort -unr
uniq 删除文件中重复的行
-c 在输出行前面加上每行在输入文件中出现的次数
sort 以字母序进行文本排序
-u 去除重复的行
-n 按字符串数值排序
-r 降序排序,默认为升序
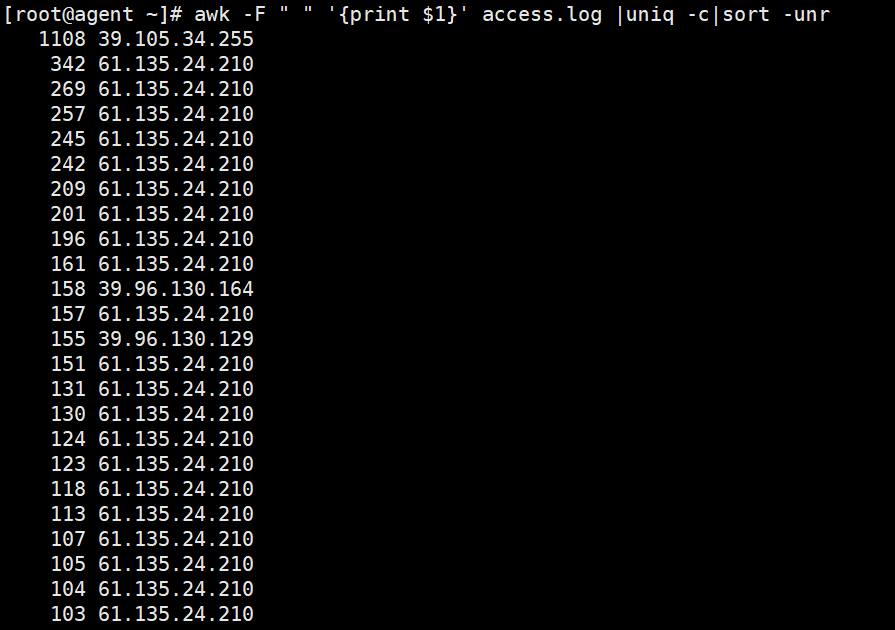
awk -F " " '{print $1}' access.log |uniq -c|sort -unr
uniq 删除文件中重复的行
-c 在输出行前面加上每行在输入文件中出现的次数
sort 以字母序进行文本排序
-u 去除重复的行
-n 按字符串数值排序
-r 降序排序,默认为升序