机器学习100天-day4,5,6,8逻辑回归

一,数据导入
import pandas as pd import numpy as np import matplotlib.pyplot as plt dataset = pd.read_csv('D:\100DaysdatasetsSocial_Network_Ads.csv') #print(dataset.head(5))
User ID Gender Age EstimatedSalary Purchased 0 15624510 Male 19 19000 0 1 15810944 Male 35 20000 0 2 15668575 Female 26 43000 0 3 15603246 Female 27 57000 0 4 15804002 Male 19 76000 0
将类别变量转为哑变量
dataset = pd.get_dummies(dataset,columns=['Gender']) print(dataset.head())
User ID Age EstimatedSalary Purchased Gender_Female Gender_Male
0 15624510 19 19000 0 0 1
1 15810944 35 20000 0 0 1
2 15668575 26 43000 0 1 0
检测是否有nan值
print(dataset.isnull().sum())
User ID 0
Age 0
EstimatedSalary 0
Purchased 0
Gender_Female 0
Gender_Male 0
dtype: int64
划分数据集
#划分数据集 from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler X = dataset[['Age','EstimatedSalary','Gender_Female','Gender_Male']] ss = StandardScaler() X = ss.fit_transform(X) Y = dataset['Purchased'] X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.25,random_state=0)
将X的数据进行归一化处理
二,逻辑回归模型
from sklearn.linear_model import LogisticRegression logistic = LogisticRegression() logistic.fit(X_train,Y_train) y_pred = logistic.predict(X_test)
三,评估预测
生成混淆矩阵
from sklearn import metrics cm = metrics.confusion_matrix(Y_test,y_pred)
print(cm) print(metrics.accuracy_score(Y_test,y_pred))
[[65 3] [ 6 26]] 0.91
混淆矩阵(confusion matrix)是机器学习尤其是统计分类中常用的用以判断分类好坏的方法,如下:
TP(True Positive): 真实为0,预测也为0
FN(False Negative): 真实为0,预测为1
FP(False Positive): 真实为1,预测为0
TN(True Negative): 真实为0,预测也为0
矩阵:
总体准确率: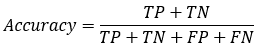
由此可理解示例中混淆矩阵和准确率的含义
四、逻辑回归详解-day8
推荐阅读文章
翻译,https://blog.csdn.net/Neuf_Soleil/article/details/81712097,链接里有原文链接