一、re.match(),从字符串的起始位置开始匹配,比如hello,匹配模式第一个字符必须为 h
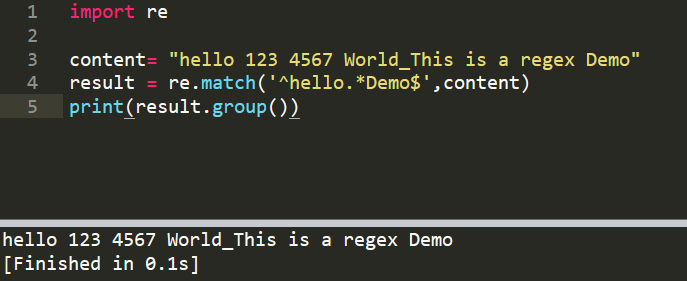
1、re.match(),模式'^hello.*Demo$',匹配字符串符合正则的所有内容
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello.*Demo$',content)
print(result.group())
2、()、group(1),匹配字符串中的某个字符串,匹配数字 (d+)
group()匹配全部,group(1)匹配第一个()
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hellos(d+)s(d+)sWorld.*Demo$',content)
print(result.group(2))
3、s只能匹配一个空格,若有多个空格呢,hello 123,用 s+ 即可
4、匹配空格、或任意字符串,.*,为贪婪模式,会影响后面的匹配,比如 .*(d+),因此用 .*? 代替s+
4.1 贪婪模式
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello.*(d+)s(d+)sWorld.*Demo$',content)
print(result.group(1))
输出 3
4.2 非贪婪模式
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hello.*?(d+).*?(d+)sWorld.*Demo$',content)
print(result.group(1))
输出123
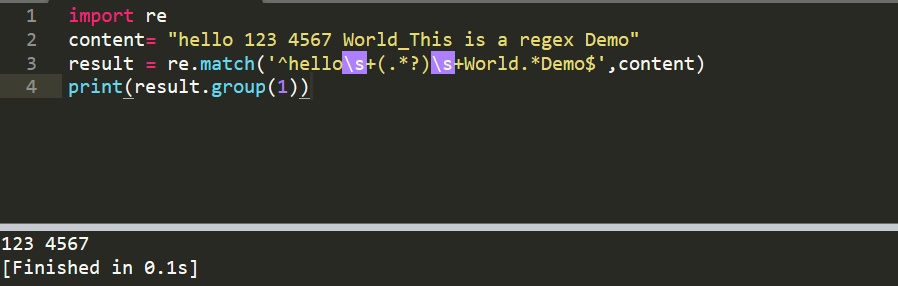
5、匹配 123 4567,(.*?)
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.match('^hellos+(.*?)s+World.*Demo$',content)
print(result.group(1))
输出 123 4567
当匹配特殊字符时,用转义,$5.00,转为后 $5.00
二、re.search(),扫描整个字符串,比如hello,匹配模式第一个不一定必须为 h,可以是 e
网上其它文章写的比较混乱,没有写出re.match与re.search之间的区别,只是写了一个re.search使用案例,无法让新手朋友深入理解各个模式之间的区别
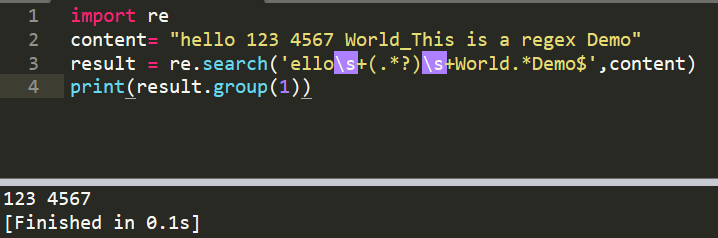
1、这里在用前面的案例,匹配 “123 4567”
import re
content= "hello 123 4567 World_This is a regex Demo"
result = re.search('ellos+(.*?)s+World.*Demo$',content) #从ello开始,re.match()必须从 h 开始
print(result.group(1))
输出 123 4567
2、匹配任意标签的内容,比如 <li data-view="4" class="active">,.*?active.*?xxxxx
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>',html,re.S) #当有多个 <li 时,唯有目标才有active,写入action即可指定此标签,.*?active.*?xxxxx
可以指定任意的标签,当active不同时,用正则re会比BeautifulSoup简单。
三、re.findall,列表语法来匹配字符串,不是 group(1)
以列表形式返回匹配的内容,语法与re.search一样
re.search:通过 group(1) 来匹配字符串
re.findall:通过列表语法来匹配字符串,不是 group(1)
re.findall('<li.*?active.*?singer="(.*?)">(.*?)</a>',html,re.S)
输出 [('齐秦', '往事随风')],列表内部是一个元组
print(result)
for x in result:
print(x[0]) #元组('齐秦', '往事随风'),对此元组的切片

四、re.compile
若多次复用某个写好的正则,用 re.compile("正则")
import re
content= """hello 12345 world_this
123 fan
"""
pattern =re.compile("hello.*fan",re.S)
result = re.match(pattern,content)
print(result)
print(result.group())