一、作业内容
作业①:
1.要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
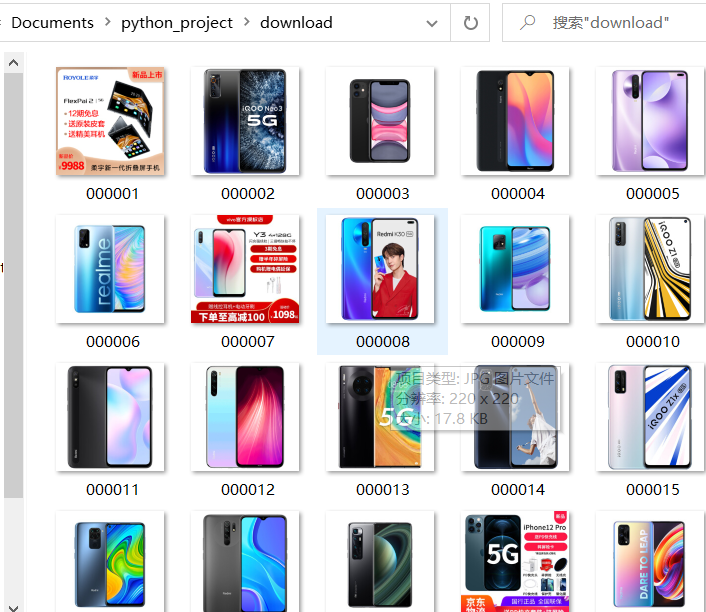
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/
关键词:学生自由选择
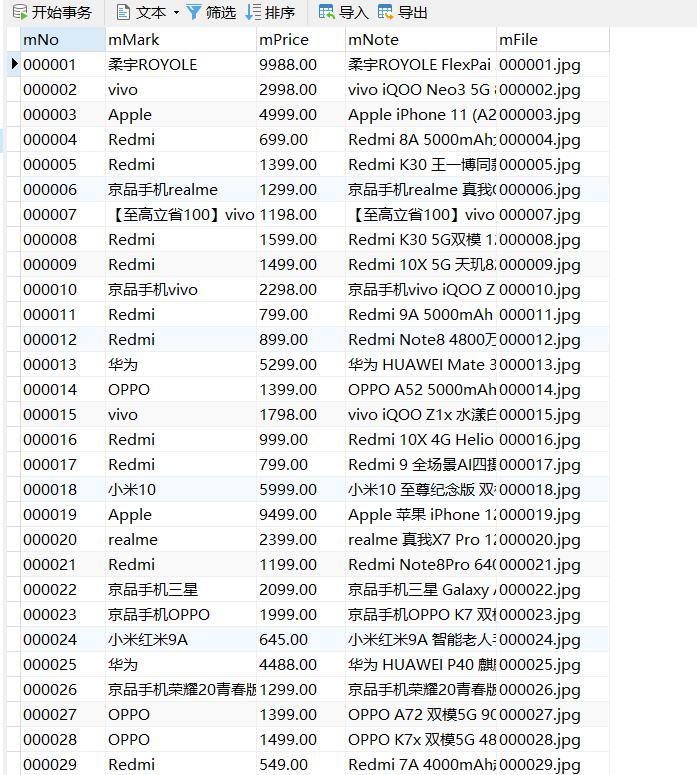
输出信息:MYSQL的输出信息如下
mNo mMark mPrice mNote mFile
000001 三星Galaxy 9199.00 三星Galaxy Note20 Ultra 5G... 000001.jpg
000002......
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class JD:
header = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072531 Minefield/3.0.2pre"
}
# 图片存储的位置
imagepath = "download"
def startUp(self, url, key):#开始将url和关键词模拟浏览器搜索爬取
chrome_options = Options()#调用chrome的浏览器
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.threads = []#线程
self.No = 0#编号
self.imgNo = 0#图片命名
try:
self.con = sqlite3.connect("phones.db")
#链接到指定数据库,事实证明是是运行的文件的下面的直接建立
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table phones")
#初始操作删除phone的数据库的所有内容
except:
pass#报错直接忽略
try:
sql = "create table phones(mNo varchar(32) primary key,mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
#所以我们只需要建一个数据库具体的表的为这句语句实现,指定为phone的表
self.cursor.execute(sql)
#表示执行上面的语句
except:
pass#报错直接忽略
except Exception as err:
print(err)#报错显示其原因
try:#处理下载的图像
if not os.path.exists(JD.imagepath):
#imagepath在JD类下所以这样表示
os.mkdir(JD.imagepath)
images = os.listdir(JD.imagepath)
for image in images:#将每一张图片合并带images路径里
s = os.path.join(JD.imagepath, image)
os.remove(s)
except Exception as err:
print(err)
self.driver.get(url)#浏览器得到地址
keyinput = self.driver.find_element_by_id("key")#浏览器根据关键词进行搜索
keyinput.send_keys(key)#模拟键盘输入
keyinput.send_keys(Keys.ENTER)#确认返回结果
def closeUp(self):#关闭数据库与浏览器
try:
self.con.commit()
self.con.close()#数据库关闭
self.driver.close()#浏览器关闭
except Exception as err:
print(err)#报错显示其原因
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
#将从浏览器爬取得到的数据插入数据库
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
#因为每次爬取的都是不同的数据,所以这个sql语句是含有参数的表示
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
#执行sql指令
except Exception as err:
print(err)#报错显示其原因
def showDB(self):
#实现在pycharm的控制台输出从浏览器导出到mysql结果
try:
con = sqlite3.connect("phones.db")
#第一步肯定是建立链接
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))#控制台显示的一排数据
cursor.execute("select mNO,mMark,mPrice,mFile,mNote from phones order by mNo")#sql语句获取数据
#第二步执行mysql语句,得到的结果用rows暂存,所以之后我们还需要将rows分隔开打印
rows = cursor.fetchall()
for row in rows:
print("%-8s%-16s%-8s%-16s%s" % (row[0], row[1], row[2], row[3], row[4]))
#分隔开打印数据
con.close()#读取完数据,关闭数据库
except Exception as err:
print(err)
def downloadDB(self, src1, src2, mFile):#仅仅下载图片
data = None#初始化为none
if src1:
try:
req = urllib.request.Request(src1, headers=JD.header)#发送请求
resp = urllib.request.urlopen(req, timeout=100)
data = resp.read()#下载
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=JD.header)#发送请求
resp = urllib.request.urlopen(req, timeout=100)
data = resp.read()#下载
except:
pass
if data:
print("download begin!", mFile)
fobj = open(JD.imagepath + "\" + mFile, "wb")#打开保存的路径
fobj.write(data)#将数据写入进去
fobj.close()#关闭文件写入通道
print("download finish!", mFile)
def processJD(self):#真正的爬取数据开始!
time.sleep(10)
try:
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
#除图片以外其他所有信息均在这个目录下
time.sleep(1)
for li in lis:
time.sleep(1)
try:#图片只能可能会出现在在image的两个属性下面
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
time.sleep(1)
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
time.sleep(1)
except:
src2 = ""
try:#除此之外price也是单独的位置
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
time.sleep(1)
except:
price = "0"
#note和mark信息存储在一个记录下需要进行分割
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东
", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东
", "")
note = note.replace(",", "")
time.sleep(1)
self.No = self.No + 1
no = str(self.No)
#为了使图片的命名更加规范,采用同位数字来表示
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.downloadDB, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
#为了节省时间没有经行翻页,但是也是试过下面的代码是正确,之前没有注释前,运行是可以得到结果,只不过最后打断继续读取图片和信息
#try:
#self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
#except:
#nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
#time.sleep(10)
#nextPage.click()
#self.processJD()
except Exception as err:
print(err)
def executeJD(self, url,key):#想是将所有功能集合在一起
#在运行的时候顺便做了统计时间的工作
starttime = datetime.datetime.now()
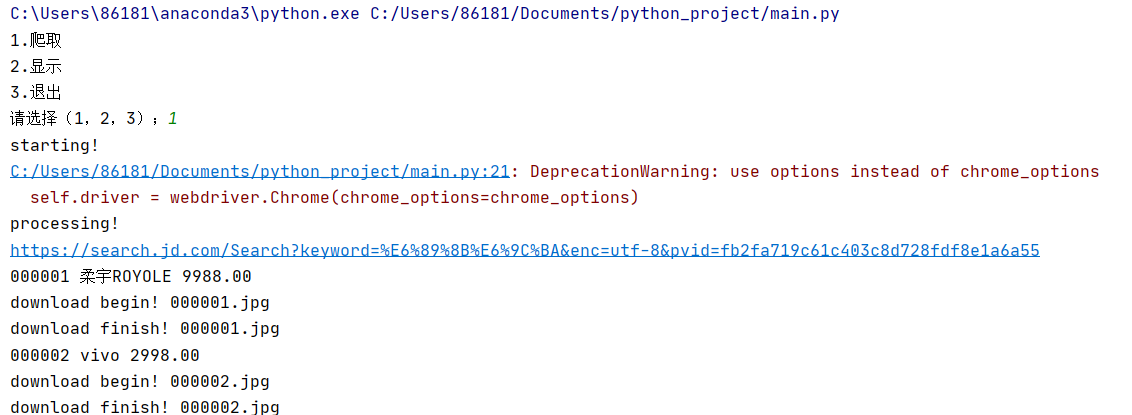
print("starting!")#提示语
self.startUp(url, key)
print("processing!")#提示语
self.processJD()
print("closing!")#提示语
self.closeUp()
for t in self.threads:
t.join()
print("complete!")#提示语
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total", elapsed, "seconds elasped")
url = "https://www.jd.com"
spider = JD()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3);")
if s == "1":
JD().executeJD(url,'手机')#没有JD()会报错因为self
continue
elif s == "2":
JD().showDB()#没有JD()会报错因为self
continue
elif s == "3":
break

2.心得:
基本上而言是PPT上的代码,所以没有什么创新,~~ 就多多注释 ~~ !
讲一讲遇到的问题和收获吧!
遇到报错的时候有时候不是代码的问题,可以尝试time.sleep就可以了
图片下载的位置是和编译文件在一起,而数据库也是不需要自己提前做什么,
基本上代码一运行,相应步骤出来就结束了
最后唯一个比较有用的就是self报错的时候是表明前面一个应该为对象,加上"()"就可以了
作业②
1.要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55
2......
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class STOCK:
header = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072531 Minefield/3.0.2pre"
}
#这个恒定不变的!
def start(self, url):#开始只需要利用url模拟浏览器搜索爬取
chrome_options = Options()#调用chrome的浏览器
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.count = 0#编号
try:
self.con = sqlite3.connect("stock.db")
#链接到指定数据库,事实证明是是运行的文件的下面的直接建立,额外再补充一下:这里的数据库也是表格
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table stock")
#初始操作删除stock的数据库的原来所有内容
except:
pass#报错直接忽略
try:
sql = "create table stock(count varchar(256) ,stockname varchar(256),num varchar(256),lastest_pri varchar(64),ddf varchar(64),dde varchar(64),cjl varchar(64),cje varchar(32),zf varchar(32),top varchar(32),low varchar(32),today varchar(32),yestd varchar(32))"
#所以我们只需要建一个数据库具体的表的为这句语句实现,指定为stock的表
self.cursor.execute(sql)
#表示执行上面的语句
except:
pass#报错直接忽略
except Exception as err:
print(err)#报错显示其原因
self.driver.get(url)#浏览器得到地址
def closeUp(self):#关闭数据库与浏览器
#这个部分和第一题是一样的
try:
self.con.commit()
self.con.close()#数据库关闭
self.driver.close()#浏览器关闭
except Exception as err:
print(err)#报错显示其原因
def insertDB(self, count,stockname,num,lastest_pri,ddf,dde,cjl,cje,zf,top,low,today,yestd):
#将从浏览器爬取得到的数据插入数据库
try:
sql = "insert into stock (count,stockname,num,lastest_pri,ddf,dde,cjl,cje,zf,top,low,today,yestd) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
#因为每次爬取的都是不同的数据,所以这个sql语句是含有参数的表示
self.cursor.execute(sql, (count,stockname,num,lastest_pri,ddf,dde,cjl,cje,zf,top,low,today,yestd))
#执行sql指令
except Exception as err:
print(err)#报错显示其原因
def showDB(self):
#实现在pycharm的控制台输出从浏览器导出到mysql结果
try:
con = sqlite3.connect("stock.db")
#第一步肯定是建立链接
cursor = con.cursor()
print("count","stockname","num","lastest_pri","ddf","dde","cjl","cje","zf","top","low","today","yestd")#控制台显示的一排数据
cursor.execute("select count,stockname,num,lastest_pri,ddf,dde,cjl,cje,zf,top,low,today,yestd from stock order by count")#sql语句获取数据
#第二步执行mysql语句,得到的结果用rows暂存,所以之后我们还需要将rows分隔开打印
rows = cursor.fetchall()
for row in rows:
print(row[0], row[1], row[2], row[3], row[4],row[5], row[6], row[7], row[8], row[9],row[10], row[11], row[12])
#分隔开打印数据
con.close()#读取完数据,关闭数据库
except Exception as err:
print(err)
def execute(self, url):
print("Starting......")
self.start(url)
print("Processing......")
self.process()
print("Closing......")
self.closeUp()
print("Completed......")
def process(self):#真正的爬取数据开始!
time.sleep(1)
try:
lis = self.driver.find_elements_by_xpath("//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr")
#除图片以外其他所有信息均在这个目录下
time.sleep(1)
for li in lis:
time.sleep(1)
stockname = li.find_element_by_xpath(".//td[@class='mywidth']/a[@href]").text
num = li.find_element_by_xpath(".//td[position()=2]/a[@href]").text
lastest_pri = li.find_element_by_xpath(".//td/span[position()=1]").text
ddf = li.find_element_by_xpath(".//td[position()=6]/span").text
dde = li.find_element_by_xpath(".//td[position()=7]/span").text
cjl = li.find_element_by_xpath(".//td[position()=8]").text
time.sleep(1)
cje = li.find_element_by_xpath(".//td[position()=9]").text
zf = li.find_element_by_xpath(".//td[position()=10]").text
top = li.find_element_by_xpath(".//td[position()=11]/span").text
low = li.find_element_by_xpath(".//td[position()=12]/span").text
today = li.find_element_by_xpath(".//td[position()=13]/span").text
yestd = li.find_element_by_xpath(".//td[position()=14]").text
time.sleep(1)
self.count = self.count + 1
count=self.count
self.insertDB(count,stockname,num,lastest_pri,ddf,dde,cjl,cje,zf,top,low,today,yestd )
except Exception as err:
print(err)
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = STOCK()
STOCK().execute(url)
STOCK().showDB()#没有()会报错因为self
分析页面
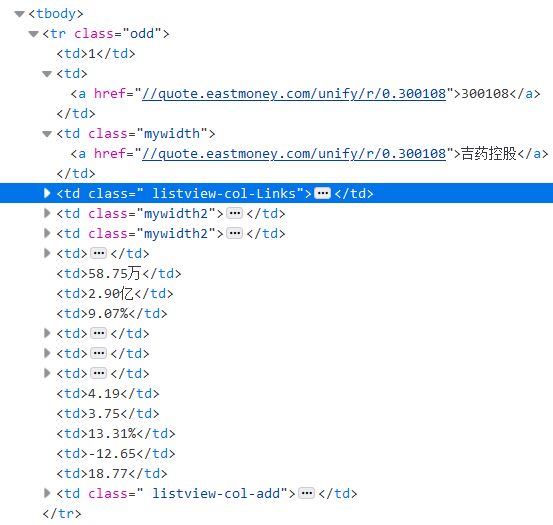
结果


2.心得:
实验代码是利用作业二的结果得到,总体来说花的时间比作业一少
(可能是因为自己一开始对selenium框架不太了解,
代码部分根据自己的需要删改了一下,修改完稍微调试一下就可以了!
遇到的问题:我是想让代码简洁写,不想要太多功能,所以一开始取消了execute,利用start和process但是报错
:driver no find&&con no find,几经调试还是不行,索性又把execute给补上,
猜测可能和函数调用机制有关,我给忘记了
作业③:
1.要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Id cCourse cCollege cTeacher cTeam cCount cProcess cBrief
1 Python数据分析与展示 北京理工大学 嵩天 嵩天 470 2020年11月17日 ~ 2020年12月29日 “我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” 运用数据是精准刻画事物、呈现发展规律的主要手段,分析数据展示规律,把思想变得更精细! ——“弹指之间·享受创新”,通过8周学习,你将掌握利用Python语言表示、清洗、统计和展示数据的能力。
2......
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class icourse:
header = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072531 Minefield/3.0.2pre"
}
#这个恒定不变的!
def start(self, url):#开始只需要利用url模拟浏览器搜索爬取
chrome_options = Options()#调用chrome的浏览器
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.id=0#编号
try:
self.con = sqlite3.connect("icourse.db")
#链接到指定数据库,事实证明是是运行的文件的下面的直接建立,额外再补充一下:这里的数据库也是表格
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table icourse")
#初始操作删除stock的数据库的原来所有内容
except:
pass#报错直接忽略
try:
sql = "create table icourse(id varchar(16) ,course varchar(64),college varchar(64),teacher varchar(64),team varchar(256),count varchar(256),process varchar(128),brief varchar(512))"
#所以我们只需要建一个数据库具体的表的为这句语句实现,指定为stock的表
self.cursor.execute(sql)
#表示执行上面的语句
except:
pass#报错直接忽略
except Exception as err:
print("start")#报错显示其原因
self.driver.get(url)#浏览器得到地
def closeUp(self):#关闭数据库与浏览器
#这个部分和第一题是一样的
try:
self.con.commit()
self.con.close()#数据库关闭
self.driver.close()#浏览器关闭
except Exception as err:
print("close")#报错显示其原因
def insertDB(self, id,course,college,teacher,team,count,process,brief):
#将从浏览器爬取得到的数据插入数据库
try:
sql = "insert into icourse (id,course,college,teacher,team,count,process,brief) values (?,?,?,?,?,?,?,?)"
#因为每次爬取的都是不同的数据,所以这个sql语句是含有参数的表示
self.cursor.execute(sql, (id,course,college,teacher,team,count,process,brief))
#执行sql指令
except Exception as err:
print("insert")#报错显示其原因
def showDB(self):
#实现在pycharm的控制台输出从浏览器导出到mysql结果
try:
con = sqlite3.connect("icourse.db")
#第一步肯定是建立链接
cursor = con.cursor()
print("id","course","college","teacher","team","count","process","brief")#控制台显示的一排数据
cursor.execute("select id,course,college,teacher,team,count,process,brief from icourse order by id")#sql语句获取数据
#第二步执行mysql语句,得到的结果用rows暂存,所以之后我们还需要将rows分隔开打印
rows = cursor.fetchall()
for row in rows:
print(row[0], row[1], row[2], row[3], row[4],row[5], row[6], row[7])
#分隔开打印数据
con.close()#读取完数据,关闭数据库
except Exception as err:
print("show")
def execute(self, url):
print("Starting")
self.start(url)
print("Processing")
self.process()
print("Closing")
self.closeUp()
print("Completed")
def process(self):#真正的爬取数据开始!
time.sleep(1)
try:
lis = self.driver.find_elements_by_xpath("//div[@class='m-course-list']/div/div[@class]")
#除图片以外其他所有信息均在这个目录下
for li in lis:
self.id = self.id + 1
id=self.id
course= li.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']").text
college =li.find_element_by_xpath(".//a[@class='t21 f-fc9']").text
count = li.find_element_by_xpath(".//span[@class='hot']").text
teacher=li.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']/a[position()=2]").text
team=li.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']").text
count= li.find_element_by_xpath(".//span[@class='hot']").text
brief = li.find_element_by_xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']").text
process=li.find_element_by_xpath(".//span[@class='txt']").text
self.insertDB(id,course,college,teacher,team,count,process,brief )
time.sleep(1)
except Exception as err:
print("process")
url = "https://www.icourse163.org/search.htm?search=%E8%89%BA%E6%9C%AF#/"
spider = icourse()
icourse().execute(url)
icourse().showDB()#没有()会报错因为self
分析页面

调试
结果
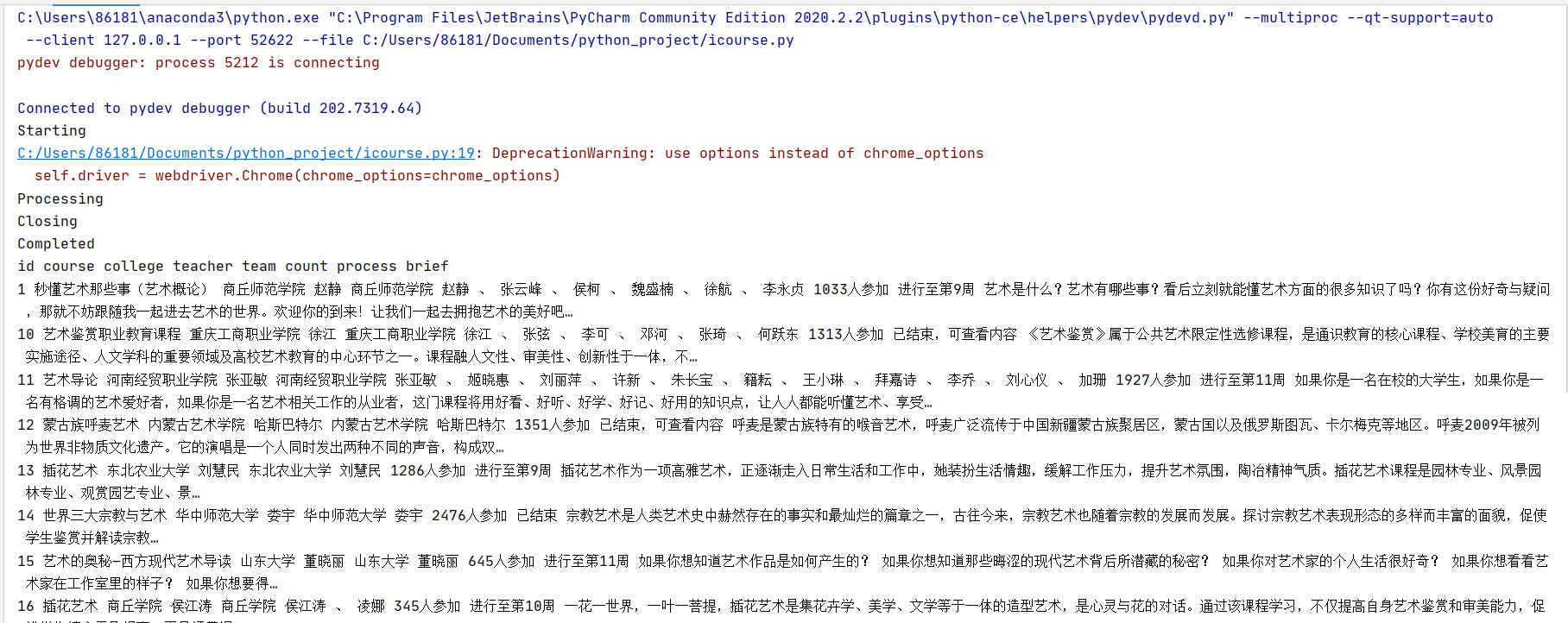
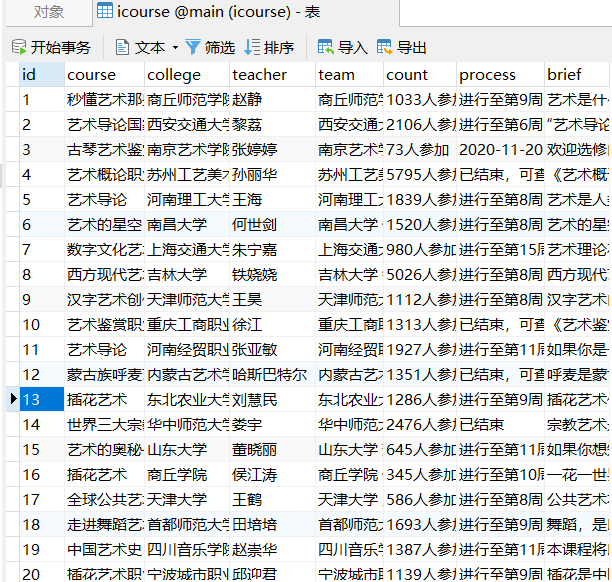
2.心得:
说句实在话,自己在这道题目用了很多讨巧的方法,
像是什么广告,虽然找到click的按钮,但是一直找不到输入的窗口
(准确的说是找到了,但是出现:list has no spen-keys,
然后我就直接用已经输了关键字的页面的url
但是对应信息的路径也太复杂,经常代码没有错误,就是爬不下来
出现结果的时候也挺让我惊喜的!
收获也是挺大的 之后也许会改进点,做完selenium感觉还是比较有趣吧!哈哈哈