大作业
![]()
内容要求
1.选一个自己感兴趣的主题。
2. 网络上爬取相关的数据。
3.进行文本分析,生成词云。
4.对文本分析结果解释说明。
5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
1、选择网址http://news.hexun.com/2017-10/31/191451193.html,爬取---【党章修改了哪些?专家帮你圈重点】这篇文章的信息。如图1所示:
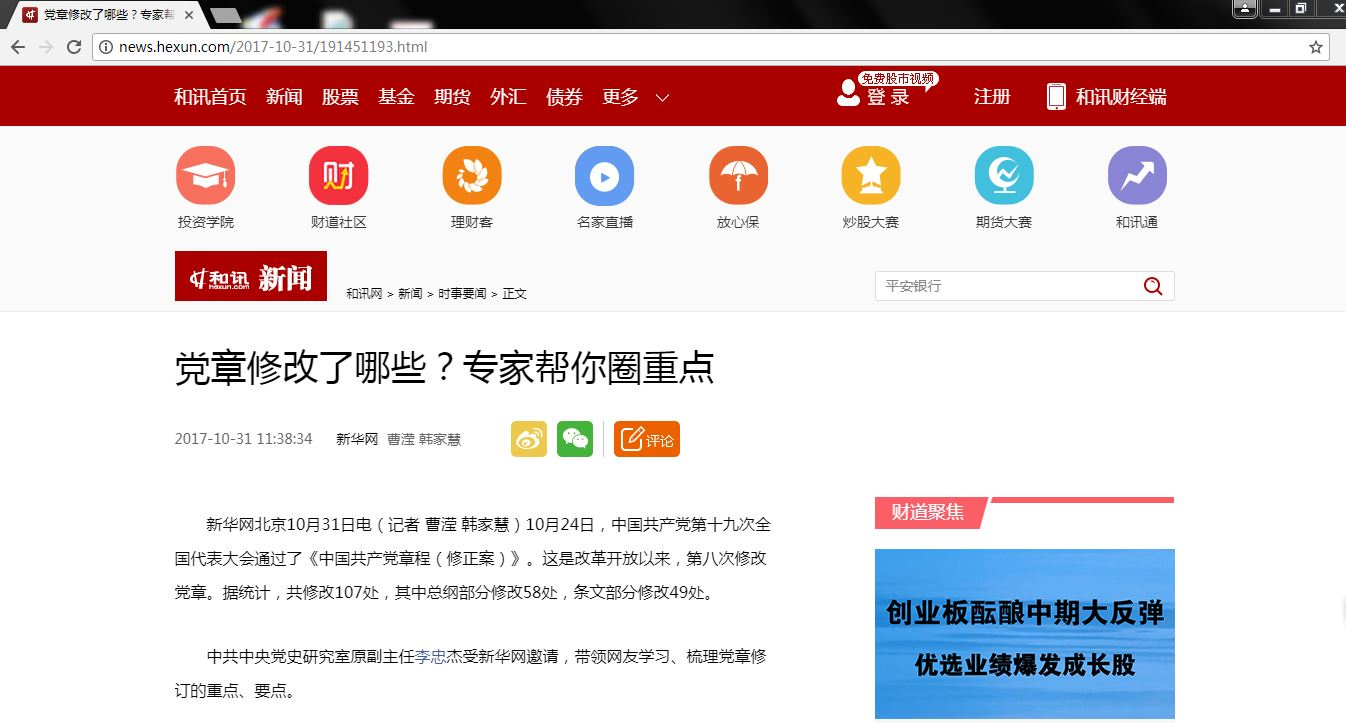
图1:选取的文章
2、按F2调出文章的代码信息,通过查看代码内容爬取【党章修改了哪些?专家帮你圈重点】的内容。如图2所示:
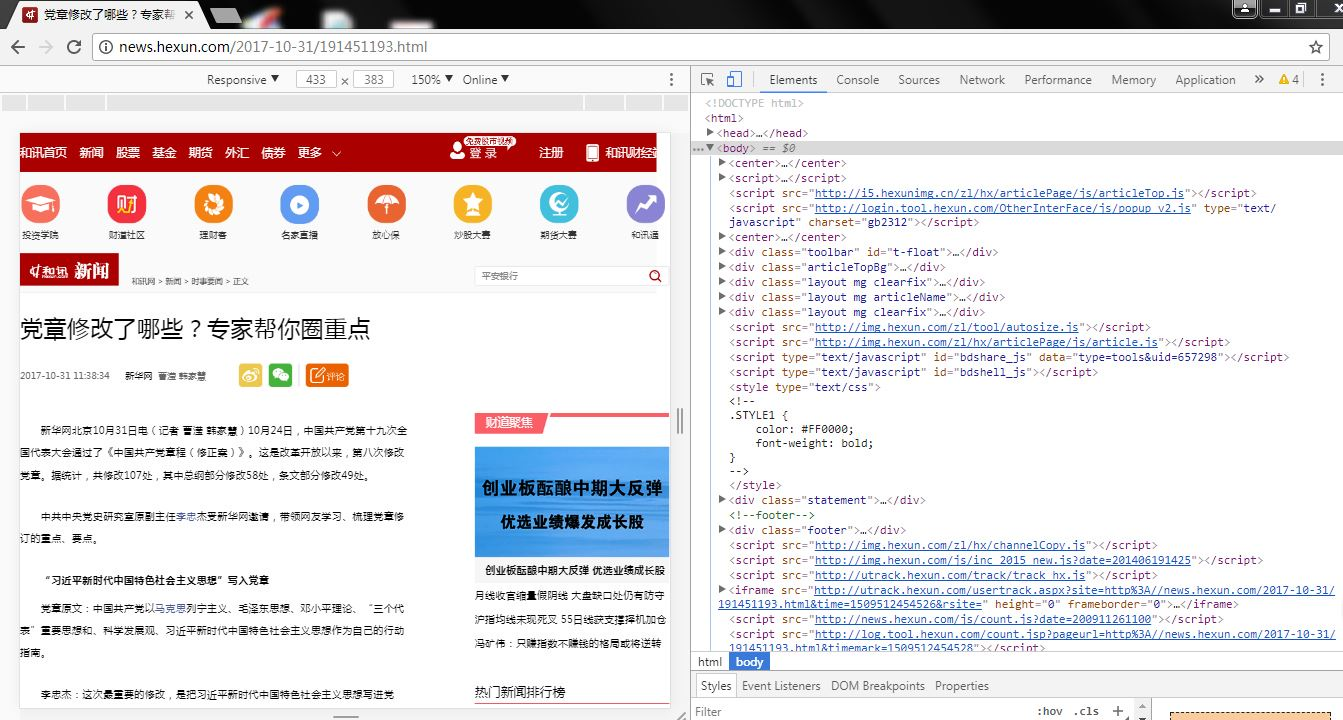
图2:调出代码信息
3、编写爬取【党章修改了哪些?专家帮你圈重点】的信息内容代码,如下代码所示:
import requests
from bs4 import BeautifulSoup
import jieba
def get(url):
res = requests.get(url)
res.encoding='gb2312'
soup = BeautifulSoup(res.text,'html.parser')
title=soup.select('title')[0].text
new=soup.select('.art_contextBox')[0].text
time=soup.select('.pr20')[0].text
print('标题:',title,' 时间:',time,' 内容:',new)
words = jieba.lcut(new)
ls = []
counts = {}
for word in words:
ls.append(word)
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0)+1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(20):
word , count = items[i]
print ("{:<10}{:>5}".format(word,count))
from wordcloud import WordCloud
import matplotlib.pyplot as plt
w=" ".join(words)
wc=WordCloud().generate(w)
plt.imshow(wc)
plt.axis("off")
plt.show()
newurl = 'http://news.hexun.com/2017-10-31/191451193.html'
print(get(newurl))
4、通过编写源代码后,爬取到了文章的具体内容。如图3所示:

图3:爬取文章内容
5、爬取到数据之后对数据进行分析和统计,通过使用jieba库,进行中文词频统计,输出的词及出现次数。如下源代码所示:
import requests
from bs4 import BeautifulSoup
import jieba
def get(url):
res = requests.get(url)
res.encoding='gb2312'
soup = BeautifulSoup(res.text,'html.parser')
new=soup.select('.art_contextBox')[0].text
words = jieba.lcut(new)
ls = []
counts = {}
for word in words:
ls.append(word)
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0)+1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(20):
word , count = items[i]
print ("{:<10}{:>5}".format(word,count))
from wordcloud import WordCloud
import matplotlib.pyplot as plt
w=" ".join(words) #键入空格以生成词云
wc=WordCloud().generate(w)
plt.imshow(wc)
plt.axis("off")
plt.show()
newurl = 'http://news.hexun.com/2017-10-31/191451193.html'
print(get(newurl))
6、通过编写代码后,获取到了中文词频统计。如下图4所示:

图4:中文词频统计
7、最后将这些数据做成词云,如图5所示:

图5:成功绘制出词云。
8、总结
从生成的词云中,我们可以看出【党章修改了哪些?专家帮你圈重点】这篇文章的重点出现的是“建设、”“中国特色”、“特色社会主义”、“党章”、“发展”等词汇。所以,我们可以猜测出这篇文章主要是讲一些关于中国特色社会主义建设的内容。