目录
一、介绍
二、连接Spark
三、创建RDD
四、RDD常用的转换 Transformation
五、RDD 常用的执行动作 Action
二、连接Spark
Spark1.3.0只支持Python2.6或更高的版本(但不支持Python3)。它使用了标准的CPython解释器,所以诸如NumPy一类的C库也是可以使用的。
通过Spark目录下的bin/spark-submit脚本你可以在Python中运行Spark应用。这个脚本会载入Spark的Java/Scala库然后让你将应用提交到集群中。你可以执行bin/pyspark来打开Python的交互命令行。
如果你希望访问HDFS上的数据,你需要为你使用的HDFS版本建立一个PySpark连接。常见的HDFS版本标签都已经列在了这个第三方发行版页面。
最后,你需要将一些Spark的类import到你的程序中。加入如下这行:
from pyspark import SparkContext, SparkConf
在一个Spark程序中要做的第一件事就是创建一个SparkContext对象来告诉Spark如何连接一个集群。为了创建SparkContext,你首先需要创建一个SparkConf对象,这个对象会包含你的应用的一些相关信息。
conf = SparkConf().setAppName(appName).setMaster(master) sc = SparkContext(conf=conf)
appName参数是在集群UI上显示的你的应用的名称。master是一个Spark、Mesos或YARN集群的URL,如果你在本地运行那么这个参数应该是特殊的”local”字符串。在实际使用中,当你在集群中运行你的程序,你一般不会把master参数写死在代码中,而是通过用spark-submit运行程序来获得这个参数。但是,在本地测试以及单元测试时,你仍需要自行传入”local”来运行Spark程序。
三、创建RDD
Spark是以RDD概念为中心运行的。RDD是一个容错的、可以被并行操作的元素集合。创建一个RDD有两个方法:在你的驱动程序中并行化一个已经存在的集合;从外部存储系统中引用一个数据集,这个存储系统可以是一个共享文件系统,比如HDFS、HBase或任意提供了Hadoop输入格式的数据来源。
并行化集合
并行化集合是通过在驱动程序中一个现有的迭代器或集合上调用SparkContext的parallelize方法建立的。为了创建一个能够并行操作的分布数据集,集合中的元素都会被拷贝。比如,以下语句创建了一个包含1到5的并行化集合:
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
分布数据集(distData)被建立起来之后,就可以进行并行操作了。比如,我们可以调用disData.reduce(lambda a, b: a+b)来对元素进行叠加。在后文中我们会描述分布数据集上支持的操作。
并行集合的一个重要参数是将数据集划分成分片的数量。对每一个分片,Spark会在集群中运行一个对应的任务。 典型情况下,集群中的每一个CPU将对应运行2-4个分片。一般情况下,Spark会根据当前集群的情况自行设定分片数量。但是,你也可以通过将第二个参 数传递给parallelize方法(比如sc.parallelize(data, 10))来手动确定分片数量。注意:有些代码中会使用切片(slice,分片的同义词)这个术语来保持向下兼容性。
一个简单的示例:
import findspark findspark.init() from pyspark import SparkContext from pyspark import SparkConf conf = SparkConf().setAppName("miniProject").setMaster("local[*]") sc=SparkContext.getOrCreate(conf) rdd=sc.parallelize([1,2,3,4,5]) rdd1=rdd.map(lambda r:r+10) #map对每一个元素操作 print(rdd1.collect())
外部数据集
PySpark可以通过Hadoop支持的外部数据源(包括本地文件系统、HDFS、 Cassandra、HBase、 亚马逊S3等等)建立分布数据集。Spark支持文本文件、 序列文件以及其他任何 Hadoop输入格式文件。
通过文本文件创建RDD要使用SparkContext的textFile方法。这个方法会使用一个文件的URI(或本地文件路径,hdfs://、s3n://这样的URI等等)然后读入这个文件建立一个文本行的集合。以下是一个例子:
>>> distFile = sc.textFile("data.txt")
建立完成后distFile上就可以调用数据集操作了。比如,我们可以调用map和reduce操作来叠加所有文本行的长度,代码如下:
distFile.map(lambda s: len(s)).reduce(lambda a, b: a + b)
在Spark中读入文件时有几点要注意:
- 如果使用了本地文件路径时,要保证在worker节点上这个文件也能够通过这个路径访问。这点可以通过将这个文件拷贝到所有worker上或者使用网络挂载的共享文件系统来解决。
- 包括textFile在内的所有基于文件的Spark读入方法,都支持将文件夹、压缩文件、包含通配符的路径作为参数。比如,以下代码都是合法的:
textFile("/my/directory")
textFile("/my/directory/*.txt")
textFile("/my/directory/*.gz")
- textFile方法也可以传入第二个可选参数来控制文件的分片数量。默认情况下,Spark会为文件的每一个块(在HDFS中块的大小默认是64MB) 创建一个分片。但是你也可以通过传入一个更大的值来要求Spark建立更多的分片。注意,分片的数量绝不能小于文件块的数量。
除了文本文件之外,Spark的Python API还支持多种其他数据格式:
- SparkContext.wholeTextFiles能够读入包含多个小文本文件的目录,然后为每一个文件返回一个(文件名,内容)对。这是与textFile方法为每一个文本行返回一条记录相对应的。
- RDD.saveAsPickleFile和SparkContext.pickleFile支持将RDD以串行化的Python对象格式存储起来。串行化的过程中会以默认10个一批的数量批量处理。
- 序列文件和其他Hadoop输入输出格式。
注意
这个特性目前仍处于试验阶段,被标记为Experimental,目前只适用于高级用户。这个特性在未来可能会被基于Spark SQL的读写支持所取代,因为Spark SQL是更好的方式。
可写类型支持
PySpark序列文件支持利用Java作为中介载入一个键值对RDD,将可写类型转化成Java的基本类型,然后使用 Pyrolite将java结果对象串行化。当将一个键值对RDD储存到一个序列文件中时PySpark将会运行上述过程的相反过程。首先将Python对象反串行化成Java对象,然后转化成可写类型。以下可写类型会自动转换:
| 可写类型 | Python类型 |
- | Text | unicode str|
- | IntWritable | int |
- | FloatWritable | float |
- | DoubleWritable | float |
- | BooleanWritable | bool |
- | BytesWritable | bytearray |
- | NullWritable | None |
- | MapWritable | dict |
数组是不能自动转换的。用户需要在读写时指定ArrayWritable的子类型.在读入的时候,默认的转换器会把自定义的ArrayWritable子 类型转化成Java的Object[],之后串行化成Python的元组。为了获得Python的array.array类型来使用主要类型的数组,用户 需要自行指定转换器。
保存和读取序列文件
和文本文件类似,序列文件可以通过指定路径来保存与读取。键值类型都可以自行指定,但是对于标准可写类型可以不指定。
>>> rdd = sc.parallelize(range(1, 4)).map(lambda x: (x, "a" * x )) >>> rdd.saveAsSequenceFile("path/to/file") >>> sorted(sc.sequenceFile("path/to/file").collect()) [(1, u'a'), (2, u'aa'), (3, u'aaa')]
保存和读取其他Hadoop输入输出格式
PySpark同样支持写入和读出其他Hadoop输入输出格式,包括’新’和’旧’两种Hadoop MapReduce API。如果有必要,一个Hadoop配置可以以Python字典的形式传入。以下是一个例子,使用了Elasticsearch ESInputFormat:
$ SPARK_CLASSPATH=/path/to/elasticsearch-hadoop.jar ./bin/pyspark >>> conf = {"es.resource" : "index/type"} # assume Elasticsearch is running on localhost defaults >>> rdd = sc.newAPIHadoopRDD("org.elasticsearch.hadoop.mr.EsInputFormat", "org.apache.hadoop.io.NullWritable", "org.elasticsearch.hadoop.mr.LinkedMapWritable", conf=conf) >>> rdd.first() # the result is a MapWritable that is converted to a Python dict (u'Elasticsearch ID', {u'field1': True, u'field2': u'Some Text', u'field3': 12345})
四、RDD常用的转换 Transformation
RDD支持两类操作:转化操作,用于从已有的数据集转化产生新的数据集;启动操作,用于在计算结束后向驱动程序返回结果。举个例子,map是一个转化操作,可以将数据集中每一个元素传给一个函数,同时将计算结果作为一个新的RDD返回。另一方面,reduce操作是一个启动操作,能够使用某些函数来聚集计算RDD中所有的元素,并且向驱动程序返回最终结果(同时还有一个并行的reduceByKey操作可以返回一个分布数据集)。
在Spark所有的转化操作都是惰性求值的,就是说它们并不会立刻真的计算出结果。相反,它们仅仅是记录下了转换操作的操作对象(比如:一个文件)。只有当一个启动操作被执行,要向驱动程序返回结果时,转化操作才会真的开始计算。这样的设计使得Spark运行更加高效——比如,我们会发觉由map操作产生的数据集将会在reduce操作中用到,之后仅仅是返回了reduce的最终的结果而不是map产生的庞大数据集。
在默认情况下,每一个由转化操作得到的RDD都会在每次执行启动操作时重新计算生成。但是,你也可以通过调用persist(或cache)方法来将RDD持久化到内存中,这样Spark就可以在下次使用这个数据集时快速获得。Spark同样提供了对将RDD持久化到硬盘上或在多个节点间复制的支持。
下面的表格列出了Spark支持的常用转化操作。欲知细节,请查阅RDD API文档(Scala, Java, Python)和键值对RDD函数文档(Scala, Java)。
转化操作 | 作用
————| ——
map(func) | 返回一个新的分布数据集,由原数据集元素经func处理后的结果组成
filter(func) | 返回一个新的数据集,由传给func返回True的原数据集元素组成
flatMap(func) | 与map类似,但是每个传入元素可能有0或多个返回值,func可以返回一个序列而不是一个值
mapParitions(func) | 类似map,但是RDD的每个分片都会分开独立运行,所以func的参数和返回值必须都是迭代器
mapParitionsWithIndex(func) | 类似mapParitions,但是func有两个参数,第一个是分片的序号,第二个是迭代器。返回值还是迭代器
sample(withReplacement, fraction, seed) | 使用提供的随机数种子取样,然后替换或不替换
union(otherDataset) | 返回新的数据集,包括原数据集和参数数据集的所有元素
intersection(otherDataset) | 返回新数据集,是两个集的交集
distinct([numTasks]) | 返回新的集,包括原集中的不重复元素
groupByKey([numTasks]) | 当用于键值对RDD时返回(键,值迭代器)对的数据集
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 用于键值对RDD时返回(K,U)对集,对每一个Key的value进行聚集计算
sortByKey([ascending], [numTasks])用于键值对RDD时会返回RDD按键的顺序排序,升降序由第一个参数决定
join(otherDataset, [numTasks]) | 用于键值对(K, V)和(K, W)RDD时返回(K, (V, W))对RDD
cogroup(otherDataset, [numTasks]) | 用于两个键值对RDD时返回(K, (V迭代器, W迭代器))RDD
cartesian(otherDataset) | 用于T和U类型RDD时返回(T, U)对类型键值对RDD
pipe(command, [envVars]) | 通过shell命令管道处理每个RDD分片
coalesce(numPartitions) | 把RDD的分片数量降低到参数大小
repartition(numPartitions) | 重新打乱RDD中元素顺序并重新分片,数量由参数决定
repartitionAndSortWithinPartitions(partitioner) | 按照参数给定的分片器重新分片,同时每个分片内部按照键排序
具体示例:
map
将函数作用于数据集的每一个元素上,生成一个分布式的数据集返回
Return a new RDD by applying a function to each element of this RDD. >>> rdd = sc.parallelize(["b", "a", "c"]) >>> sorted(rdd.map(lambda x: (x, 1)).collect()) [('a', 1), ('b', 1), ('c', 1)]
一个完整的例子:
from <span class='wp_keywordlink_affiliate'><a href="https://www.168seo.cn/tag/pyspark" title="View all posts in pyspark" target="_blank">pyspark</a></span> import SparkConf,SparkContext #配置 conf = SparkConf() #.setAppName("spark demo ").setMaster("local[2]") sc = SparkContext(conf=conf) data = range(10) print(list(data)) r1 = sc.parallelize(data) r2 = r1.map(lambda x:x+1) print(r2.collect()) sc.stop()
结果是:

filter
返回所有 funtion 返回值为True的函数,生成一个分布式的数据集返回
Return a new RDD containing only the elements that satisfy a predicate. >>> rdd = sc.parallelize([1, 2, 3, 4, 5]) >>> rdd.filter(lambda x: x % 2 == 0).collect() [2, 4]
一个完整的例子:
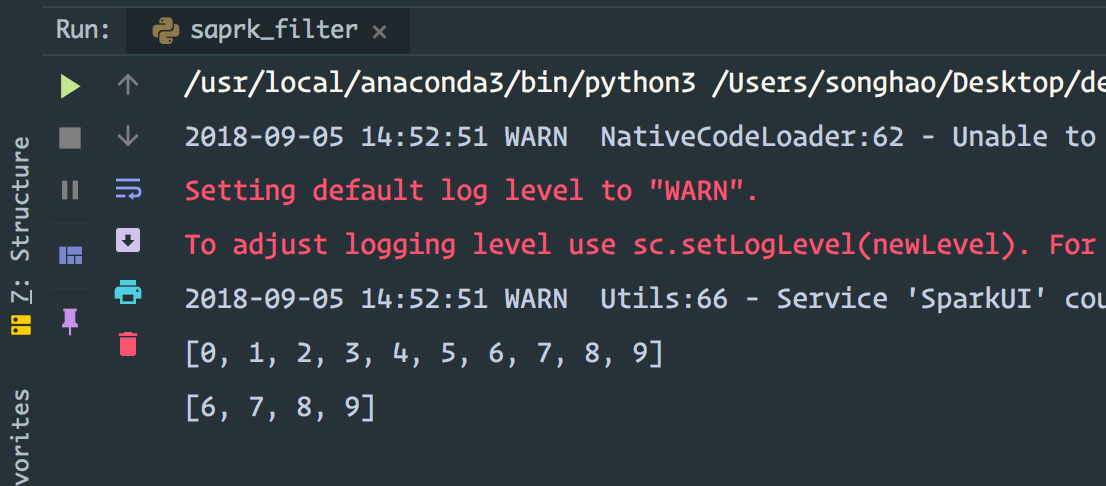
from pyspark import SparkConf,SparkContext #配置 conf = SparkConf() #.setAppName("spark demo ").setMaster("local[2]") sc = SparkContext(conf=conf) data = range(10) print(list(data)) r1 = sc.parallelize(data) r2 = r1.filter(lambda x:x>5) print(r2.collect()) sc.stop()
结果是:
flatMap
Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results.
一个完整的例子:
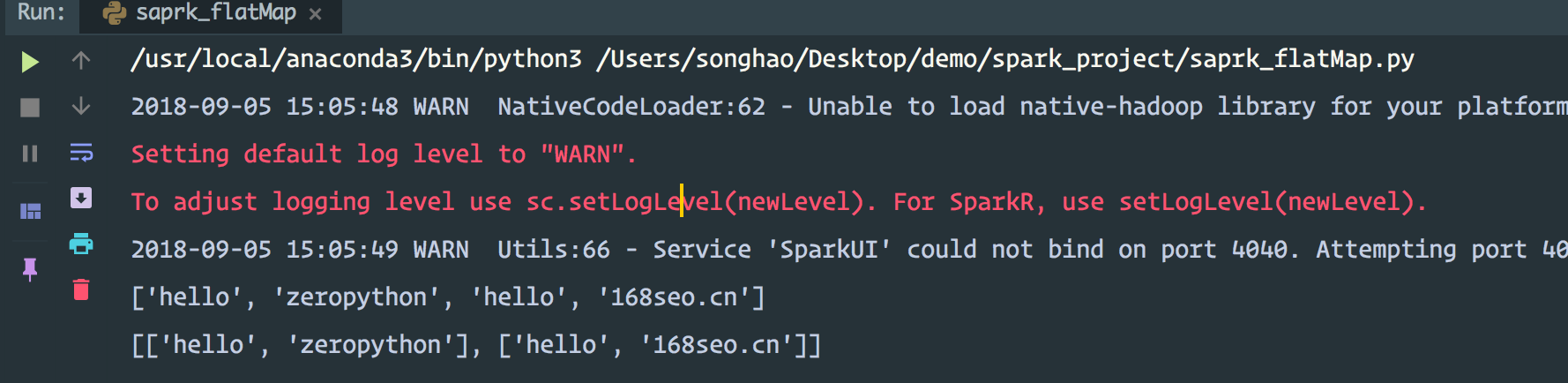
from pyspark import SparkConf,SparkContext #配置 conf = SparkConf() #.setAppName("spark demo ").setMaster("local[2]") sc = SparkContext(conf=conf) data = ["hello zeropython","hello 168seo.cn"] # print(list(data)) r1 = sc.parallelize(data) r2 = r1.flatMap(lambda x:x.split(" ")) r3 = r1.map(lambda x:x.split(" ")) print(r2.collect()) print(r3.collect()) sc.stop() RDD, and then flattening the results.
结果是:
groupBykey
按照相同key的数据分成一组
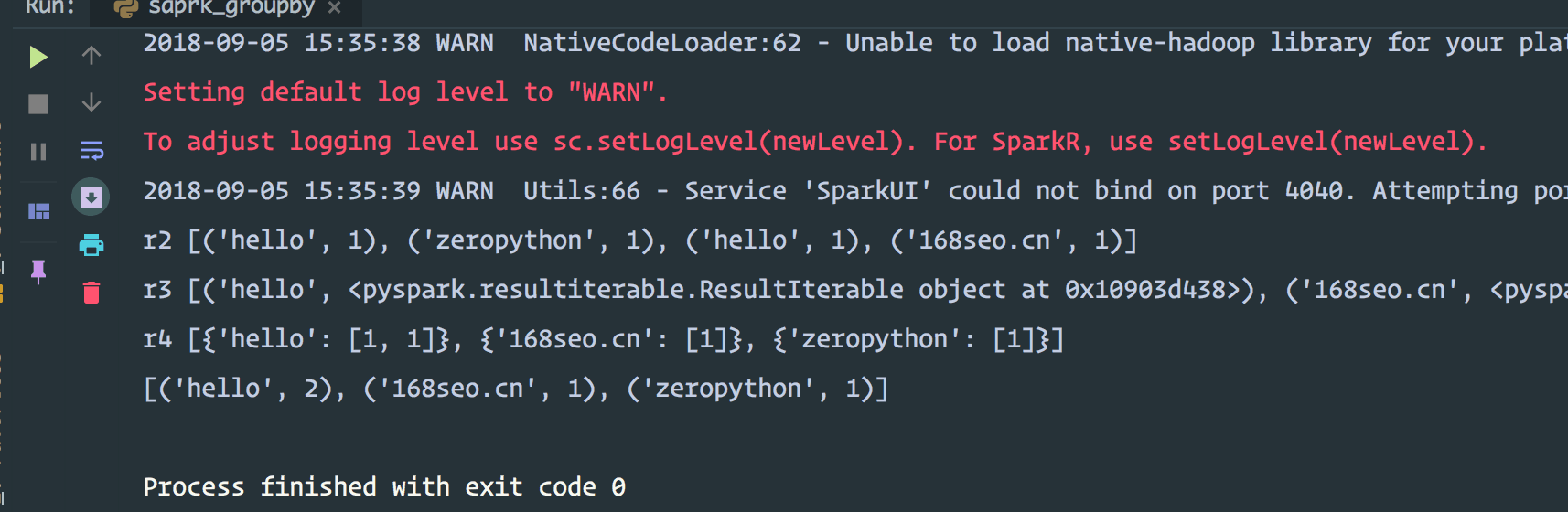
from _operator import add from pyspark import SparkConf,SparkContext #配置 conf = SparkConf() #.setAppName("spark demo ").setMaster("local[2]") sc = SparkContext(conf=conf) sc.setLogLevel("WARN") """ Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results. """ data = ["hello zeropython","hello 168seo.cn"] # print(list(data)) r1 = sc.parallelize(data) r2 = r1.flatMap(lambda x:x.split(" ")).map(lambda y:(y,1)) print("r2",r2.collect()) r3 = r2.groupByKey() print("r3",r3.collect()) r4 = r3.map(lambda x:{x[0]:list(x[1])}) print("r4",r4.collect()) print(r2.reduceByKey(add).collect()) sc.stop()
结果是:
groupBy运算
groupBy运算可以按照传入匿名函数的规则,将数据分为多个Array。比如下面的代码将intRDD分为偶数和奇数:
result = intRDD.groupBy(lambda x : x % 2).collect() print (sorted([(x, sorted(y)) for (x, y) in result]))
输出为:
[(0, [2]), (1, [1, 3, 5, 5])]
reduceBykey
把相同的key 的数据分发到一起 并进行运算
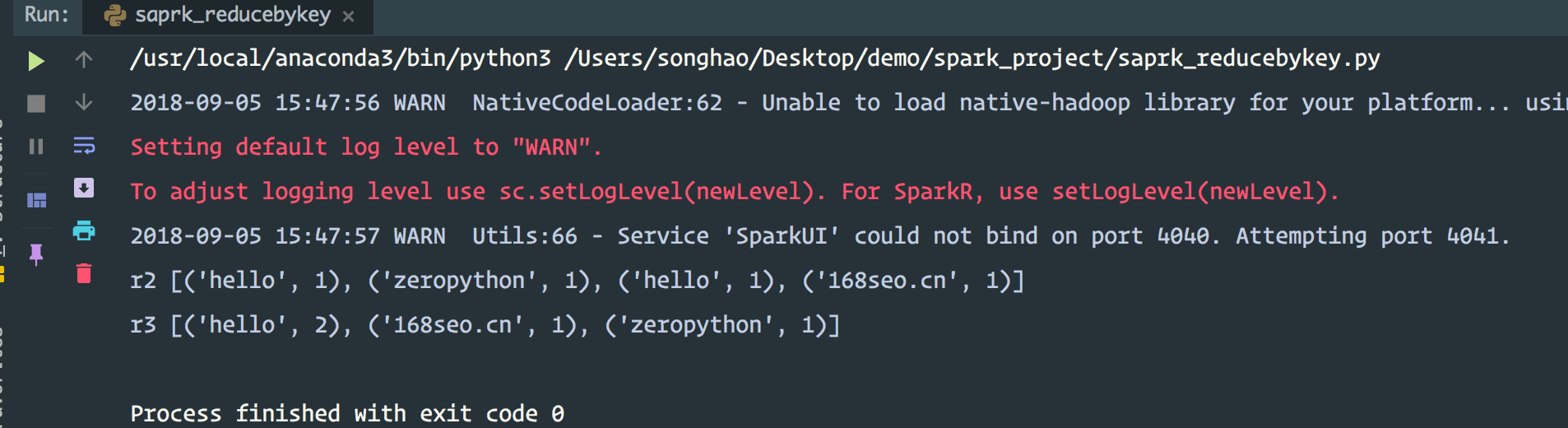
from _operator import add from pyspark import SparkConf,SparkContext #配置 conf = SparkConf() #.setAppName("spark demo ").setMaster("local[2]") sc = SparkContext(conf=conf) data = ["hello zeropython","hello 168seo.cn"] # print(list(data)) r1 = sc.parallelize(data) r2 = r1.flatMap(lambda x:x.split(" ")).map(lambda x:(x,1)) print("r2",r2.collect()) r3 = r2.reduceByKey(lambda x,y:x+y) print("r3",r3.collect()) sc.stop()
结果是:
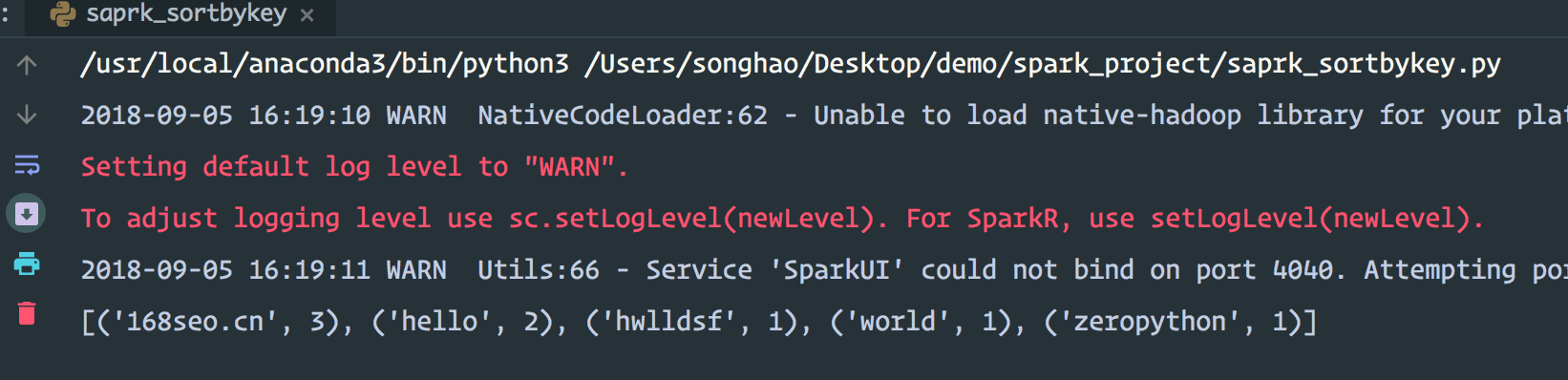
sortbykey
Sorts this RDD, which is assumed to consist of (key, value) pairs.
from _operator import add from pyspark import SparkConf,SparkContext #配置 conf = SparkConf() #.setAppName("spark demo ").setMaster("local[2]") sc = SparkContext(conf=conf) # sc.setLogLevel("FATAL") # sc.setLogLevel("ERROR") sc.setLogLevel("ERROR") data = ["hello zeropython","hwlldsf world","168seo.cn","168seo.cn","hello 168seo.cn"] # print(list(data)) r1 = sc.parallelize(data) r2 = r1.flatMap(lambda x:x.split(" ")) .map(lambda y:(y,1)) .reduceByKey(lambda x,y:x+y) .sortByKey(lambda x:x[1]) # sortByKey排序根据关键词的值进行排序 # reduceByKey 让[("a",[1,1,1,1])] 转换成 [("a",3)] print(r2.collect()) sc.stop()
结果是:
union
|
1
2
3
4
5
6
7
8
|
"""
Return the union of this RDD and another one.
>>> rdd = sc.parallelize([1, 1, 2, 3])
>>> rdd.union(rdd).collect()
[1, 1, 2, 3, 1, 1, 2, 3]
"""
|
distinct
|
1
2
3
4
5
6
7
|
"""
Return a new RDD containing the distinct elements in this RDD.
>>> sorted(sc.parallelize([1, 1, 2, 3]).distinct().collect())
[1, 2, 3]
"""
|
join
|
1
2
3
4
5
|
>>> a = sc.parallelize([("A", "a1"), ("C", "c1"), ("D", "d1"), ("F", "f1"), ("F", "f2")])
>>> b = sc.parallelize([("A", "a2"), ("C", "c2"), ("C", "c3"), ("E", "e1")])
>>> a.join(b).collect()
[('C', ('c1', 'c2')), ('C', ('c1', 'c3')), ('A', ('a1', 'a2'))]
|
leftOuterJoin
|
1
2
3
|
>>> a.leftOuterJoin(b).collect()
[('F', ('f1', None)), ('F', ('f2', None)), ('D', ('d1', None)), ('C', ('c1', 'c2')), ('C', ('c1', 'c3')), ('A', ('a1', 'a2'))]
|
rightOuterJoin
|
1
2
3
|
>>> a.rightOuterJoin(b).collect()
[('E', (None, 'e1')), ('C', ('c1', 'c2')), ('C', ('c1', 'c3')), ('A', ('a1', 'a2'))]
|
fullOuterJoin
|
1
2
3
4
|
>>> a.fullOuterJoin(b).collect()
[('F', ('f1', None)), ('F', ('f2', None)), ('D', ('d1', None)), ('E', (None, 'e1')), ('C', ('c1', 'c2')), ('C', ('c1', 'c3')), ('A', ('a1', 'a2'))]
>>>
|
randomSplit运算
randomSplit 运算将整个集合以随机数的方式按照比例分为多个RDD,比如按照0.4和0.6的比例将intRDD分为两个RDD,并输出:
|
1
2
3
4
5
6
7
|
intRDD = sc.parallelize([3,1,2,5,5])
stringRDD = sc.parallelize(['Apple','Orange','Grape','Banana','Apple'])
sRDD = intRDD.randomSplit([0.4,0.6])
print (len(sRDD))
print (sRDD[0].collect())
print (sRDD[1].collect())
|
输出为:
|
1
2
3
4
|
2
[3, 1]
[2, 5, 5]
|
多个RDD转换运算
RDD也支持执行多个RDD的运算,这里,我们定义三个RDD:
|
1
2
3
4
|
intRDD1 = sc.parallelize([3,1,2,5,5])
intRDD2 = sc.parallelize([5,6])
intRDD3 = sc.parallelize([2,7])
|
并集运算
可以使用union函数进行并集运算:
|
1
2
|
print (intRDD1.union(intRDD2).union(intRDD3).collect())
|
输出为:
|
1
2
|
[3, 1, 2, 5, 5, 5, 6, 2, 7]
|
交集运算
可以使用intersection进行交集运算:
|
1
2
|
print(intRDD1.intersection(intRDD2).collect())
|
两个集合中只有一个相同元素5,所以输出为:
|
1
2
|
[5]
|
差集运算
subtract(减去 去除)
可以使用subtract函数进行差集运算:
|
1
2
|
print (intRDD1.subtract(intRDD2).collect())
|
由于两个RDD的重复部分为5,所以输出为[1,2,3]:
|
1
2
|
[2, 1, 3]
|
笛卡尔积运算
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员
笛卡尔积又叫笛卡尔乘积,是一个叫笛卡尔的人提出来的。 简单的说就是两个集合相乘的结果。
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
可以使用cartesian函数进行笛卡尔乘积运算:
|
1
2
|
print (intRDD1.cartesian(intRDD2).collect())
|
由于两个RDD分别有5个元素和2个元素,所以返回结果有10各元素:
|
1
2
|
[(3, 5), (3, 6), (1, 5), (1, 6), (2, 5), (2, 6), (5, 5), (5, 6), (5, 5), (5, 6)]
|
五、RDD 常用的执行动作 Action
下面的表格列出了Spark支持的部分常用启动操作。欲知细节,请查阅RDD API文档(Scala, Java, Python)和键值对RDD函数文档(Scala, Java)。
启动操作 | 作用
reduce(func) | 使用func进行聚集计算,func的参数是两个,返回值一个,两次func运行应当是完全解耦的,这样才能正确地并行运算
collect() | 向驱动程序返回数据集的元素组成的数组
count() | 返回数据集元素的数量
first() | 返回数据集的第一个元素
take(n) | 返回前n个元素组成的数组
takeSample(withReplacement, num, [seed]) | 返回一个由原数据集中任意num个元素的suzuki,并且替换之
takeOrder(n, [ordering]) | 返回排序后的前n个元素
saveAsTextFile(path) | 将数据集的元素写成文本文件
saveAsSequenceFile(path) | 将数据集的元素写成序列文件,这个API只能用于Java和Scala程序
saveAsObjectFile(path) | 将数据集的元素使用Java的序列化特性写到文件中,这个API只能用于Java和Scala程序
countByCount() | 只能用于键值对RDD,返回一个(K, int) hashmap,返回每个key的出现次数
foreach(func) | 对数据集的每个元素执行func, 通常用于完成一些带有副作用的函数,比如更新累加器(见下文)或与外部存储交互等
Action(执行):触发Spark作业的运行,真正触发转换算子的计算
Pyspark rdd 常用的转换 Transformation Pyspark(二)
https://www.168seo.cn/pyspark/24806.html

|
1
2
3
|
intRDD = sc.parallelize([3,1,2,5,5])
stringRDD = sc.parallelize(['Apple','Orange','Grape','Banana','Apple'])
|
基本“动作”运算
读取元素
可以使用下列命令读取RDD内的元素,这是Actions运算,所以会马上执行:
|
1
2
3
4
5
6
7
8
9
|
#取第一条数据
print (intRDD.first())
#取前两条数据
print (intRDD.take(2))
#升序排列,并取前3条数据
print (intRDD.takeOrdered(3))
#降序排列,并取前3条数据
print (intRDD.takeOrdered(3,lambda x:-x))
|
输出为:
|
1
2
3
4
5
|
3
[3, 1]
[1, 2, 3]
[5, 5, 3]
|

统计功能
可以将RDD内的元素进行统计运算:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#统计
print (intRDD.stats())
#最小值
print (intRDD.min())
#最大值
print (intRDD.max())
#标准差
print (intRDD.stdev())
#计数
print (intRDD.count())
#求和
print (intRDD.sum())
#平均
print (intRDD.mean())
|
输出为:
RDD Key-Value基本“转换”运算
Spark RDD支持键值对运算,Key-Value运算时mapreduce运算的基础,本节介绍RDD键值的基本“转换”运算。
初始化
我们用元素类型为tuple元组的数组初始化我们的RDD,这里,每个tuple的第一个值将作为键,而第二个元素将作为值。
作为值
|
1
2
|
kvRDD1 = sc.parallelize([(3,4),(3,6),(5,6),(1,2)])
|
得到key和value值
可以使用keys和values函数分别得到RDD的键数组和值数组:
|
1
2
3
|
print (kvRDD1.keys().collect())
print (kvRDD1.values().collect())
|
输出为:

筛选元素
可以按照键进行元素筛选,也可以通过值进行元素筛选,和之前的一样,使用filter函数,这里要注意的是,虽然RDD中是以键值对形式存在,但是本质上还是一个二元组,二元组的第一个值代表键,第二个值代表值,所以按照如下的代码既可以按照键进行筛选,我们筛选键值小于5的数据:
|
1
2
|
print (kvRDD1.filter(lambda x:x[0] < 5).collect())
|
输出为:
|
1
2
|
[(3, 4), (3, 6), (1, 2)]
|
同样,将x[0]替换为x[1]就是按照值进行筛选,我们筛选值小于5的数据:
|
1
2
|
print (kvRDD1.filter(lambda x:x[1] < 5).collect())
|
输出为:
|
1
2
|
[(3, 4), (1, 2)]
|
值运算
我们可以使用mapValues方法处理value值,下面的代码将value值进行了平方处理:
|
1
2
|
print (kvRDD1.mapValues(lambda x:x**2).collect())
|
输出为:
|
1
2
|
[(3, 16), (3, 36), (5, 36), (1, 4)]
|
按照key排序
可以使用sortByKey按照key进行排序,传入参数的默认值为true,是按照从小到大排序,也可以传入参数false,表示从大到小排序:
|
1
2
3
4
|
print (kvRDD1.sortByKey().collect())
print (kvRDD1.sortByKey(True).collect())
print (kvRDD1.sortByKey(False).collect())
|
输出为:
|
1
2
3
4
|
[(1, 2), (3, 4), (3, 6), (5, 6)]
[(1, 2), (3, 4), (3, 6), (5, 6)]
[(5, 6), (3, 4), (3, 6), (1, 2)]
|
合并相同key值的数据
使用reduceByKey函数可以对具有相同key值的数据进行合并。比如下面的代码,由于RDD中存在(3,4)和(3,6)两条key值均为3的数据,他们将被合为一条数据:
|
1
2
|
print (kvRDD1.reduceByKey(lambda x,y:x+y).collect())
|
输出为
|
1
2
|
[(1, 2), (3, 10), (5, 6)]
|
多个RDD Key-Value“转换”运算
初始化
首先我们初始化两个k-v的RDD:
|
1
2
3
|
kvRDD1 = sc.parallelize([(3,4),(3,6),(5,6),(1,2)])
kvRDD2 = sc.parallelize([(3,8)])
|
内连接运算
join运算可以实现类似数据库的内连接,将两个RDD按照相同的key值join起来,kvRDD1与kvRDD2的key值唯一相同的是3,kvRDD1中有两条key值为3的数据(3,4)和(3,6),而kvRDD2中只有一条key值为3的数据(3,8),所以join的结果是(3,(4,8)) 和(3,(6,8)):
|
1
2
|
print (kvRDD1.join(kvRDD2).collect())
|
输出为:
|
1
2
|
[(3, (4, 8)), (3, (6, 8))]
|
左外连接
使用leftOuterJoin可以实现类似数据库的左外连接,如果kvRDD1的key值对应不到kvRDD2,就会显示None
|
1
2
|
print (kvRDD1.leftOuterJoin(kvRDD2).collect())
|
输出为:
|
1
2
|
[(1, (2, None)), (3, (4, 8)), (3, (6, 8)), (5, (6, None))]
|
右外连接
使用rightOuterJoin可以实现类似数据库的右外连接,如果kvRDD2的key值对应不到kvRDD1,就会显示None
|
1
2
|
print (kvRDD1.rightOuterJoin(kvRDD2).collect())
|
输出为:
|
1
2
|
[(3, (4, 8)), (3, (6, 8))]
|
删除相同key值数据
使用subtractByKey运算会删除相同key值得数据:
|
1
2
|
print (kvRDD1.subtractByKey(kvRDD2).collect())
|
结果为:
|
1
2
|
[(1, 2), (5, 6)]
|
Key-Value“动作”运算
读取数据
可以使用下面的几种方式读取RDD的数据:
|
1
2
3
4
5
6
7
8
9
|
#读取第一条数据
print (kvRDD1.first())
#读取前两条数据
print (kvRDD1.take(2))
#读取第一条数据的key值
print (kvRDD1.first()[0])
#读取第一条数据的value值
print (kvRDD1.first()[1])
|
输出为:
|
1
2
3
4
5
|
(3, 4)
[(3, 4), (3, 6)]
3
4
|
按key值统计:
使用countByKey函数可以统计各个key值对应的数据的条数:
|
1
2
|
print (kvRDD1.countByKey().collect())
|
输出为:
|
1
2
|
defaultdict(<type 'int'>, {1: 1, 3: 2, 5: 1})
|
lookup查找运算
使用lookup函数可以根据输入的key值来查找对应的Value值:
|
1
2
|
print (kvRDD1.lookup(3))
|
输出为:
|
1
2
|
[4, 6]
|
持久化操作
spark RDD的持久化机制,可以将需要重复运算的RDD存储在内存中,以便大幅提升运算效率,有两个主要的函数:
持久化
使用persist函数对RDD进行持久化:
|
1
2
|
kvRDD1.persist()
|
在持久化的同时我们可以指定持久化存储等级:

首先我们导入相关函数:
|
1
2
|
from pyspark.storagelevel import StorageLevel
|
在scala中可以直接使用上述的持久化等级关键词,但是在pyspark中封装为了一个类,
StorageLevel类,并在初始化时指定一些参数,通过不同的参数组合,可以实现上面的不同存储等级。StorageLevel类的初始化函数如下:
|
1
2
3
4
5
6
7
|
def __init__(self, useDisk, useMemory, useOffHeap, deserialized, replication=1):
self.useDisk = useDisk
self.useMemory = useMemory
self.useOffHeap = useOffHeap
self.deserialized = deserialized
self.replication = replication
|
那么不同的存储等级对应的参数为:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
StorageLevel.DISK_ONLY = StorageLevel(True, False, False, False)
StorageLevel.DISK_ONLY_2 = StorageLevel(True, False, False, False, 2)
StorageLevel.MEMORY_ONLY = StorageLevel(False, True, False, False)
StorageLevel.MEMORY_ONLY_2 = StorageLevel(False, True, False, False, 2)
StorageLevel.MEMORY_AND_DISK = StorageLevel(True, True, False, False)
StorageLevel.MEMORY_AND_DISK_2 = StorageLevel(True, True, False, False, 2)
StorageLevel.OFF_HEAP = StorageLevel(True, True, True, False, 1)
"""
.. note:: The following four storage level constants are deprecated in 2.0, since the records
will always be serialized in Python.
"""
StorageLevel.MEMORY_ONLY_SER = StorageLevel.MEMORY_ONLY
""".. note:: Deprecated in 2.0, use ``StorageLevel.MEMORY_ONLY`` instead."""
StorageLevel.MEMORY_ONLY_SER_2 = StorageLevel.MEMORY_ONLY_2
""".. note:: Deprecated in 2.0, use ``StorageLevel.MEMORY_ONLY_2`` instead."""
StorageLevel.MEMORY_AND_DISK_SER = StorageLevel.MEMORY_AND_DISK
""".. note:: Deprecated in 2.0, use ``StorageLevel.MEMORY_AND_DISK`` instead."""
StorageLevel.MEMORY_AND_DISK_SER_2 = StorageLevel.MEMORY_AND_DISK_2
""".. note:: Deprecated in 2.0, use ``StorageLevel.MEMORY_AND_DISK_2`` instead."""
|
取消持久化
使用unpersist函数对RDD进行持久化:
|
1
2
|
kvRDD1.unpersist()
|
整理回顾
哇,有关pyspark的RDD的基本操作就是上面这些啦,想要了解更多的盆友们可以参照官网给出的官方文档:http://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD
今天主要介绍了两种RDD,基本的RDD和Key-Value形式的RDD,介绍了他们的几种“转换”运算和“动作”运算,整理如下:
refer:
https://www.168seo.cn/pyspark/24806.html