一、hadoop支持Lzo压缩配置
1)hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译,编译步骤如下。
2)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
[atone@hadoop102 common]$ pwd /opt/module/hadoop-2.7.2/share/hadoop/common [atone@hadoop102 common]$ ls hadoop-lzo-0.4.20.jar
3)同步hadoop-lzo-0.4.20.jar到hadoop103、hadoop104
[atone@hadoop102 common]$ xsync hadoop-lzo-0.4.20.jar
4)core-site.xml增加配置支持LZO压缩
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>io.compression.codecs</name> <value> org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec </value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property> </configuration>
5)同步core-site.xml到hadoop103、hadoop104
[atone@hadoop102 hadoop]$ xsync core-site.xml
6)启动及查看集群
[atone@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [atone@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
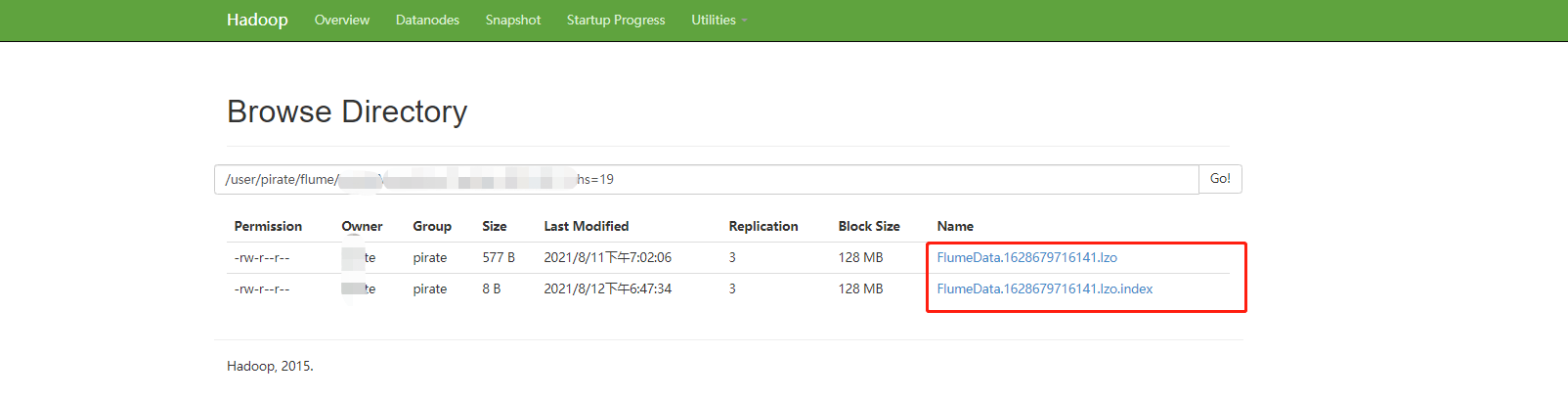
7)创建lzo文件的索引,lzo压缩文件的可切片特性依赖于其索引,故我们需要手动为lzo压缩文件创建索引。若无索引,则整个lzo文件的切片只有一个。
使用的是hadoop-lzo依赖中的工具类来为lzo压缩文件创建索引,索引文件与压缩文件在同一路径下,后缀名为.lzo.index;
示例命令:
hadoop jar /home/pirate/programs/hadoop/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /user/pirate/flume/hmtft/MoneyFlow_Test/
参考:
Linux中编译hadoop-lzo使hadoop能够支持lzo
二、配置Hive支持lzo
在$HIVE_HOME/conf/hive-site.xml文件中设置如下参数,使得Hive进行查询时使用压缩功能,具体使用的压缩算法默认与Hadoop中的配置相同,当然也有相应的参数可以进行覆盖:
<!-- 设置hive语句执行输出文件是否开启压缩,具体的压缩算法和压缩格式取决于hadoop中 设置的相关参数 --> <!-- 默认值:false --> <property> <name>hive.exec.compress.output</name> <value>true</value> <description> This controls whether the final outputs of a query (to a local/HDFS file or a Hive table) is compressed. The compression codec and other options are determined from Hadoop config variables mapred.output.compress* </description> </property> <!-- 控制多个MR Job的中间结果文件是否启用压缩,具体的压缩算法和压缩格式取决于hadoop中 设置的相关参数 --> <!-- 默认值:false --> <property> <name>hive.exec.compress.intermediate</name> <value>true</value> <description> This controls whether intermediate files produced by Hive between multiple map-reduce jobs are compressed. The compression codec and other options are determined from Hadoop config variables mapred.output.compress* </description> </property>
3.oozie支持lzo
应该把oozie引用的hive-site.xml更新到集群即可(待测。。)
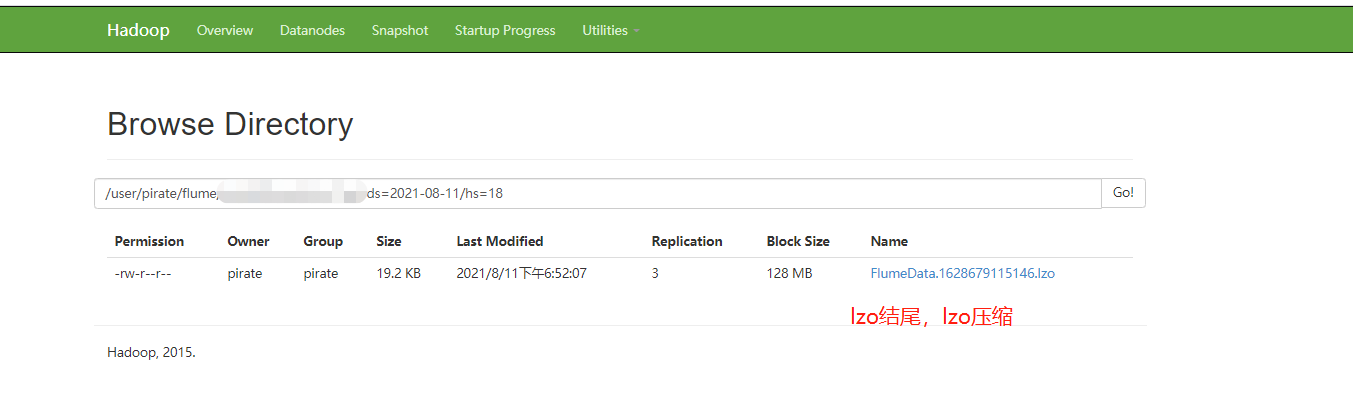
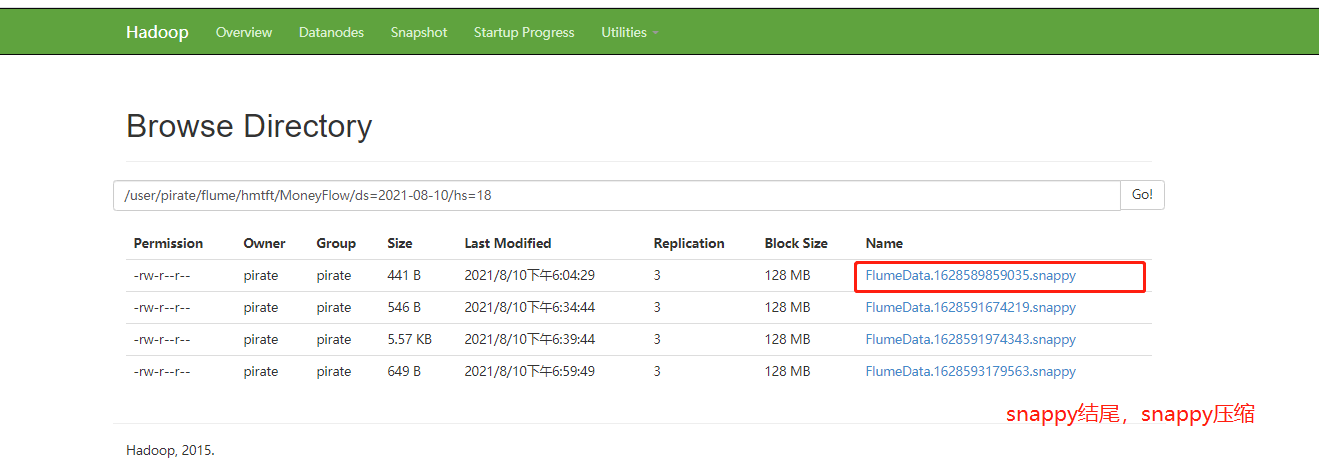
4.Flume采集到HDFS采用lzo压缩:
注:需要把hadoop相关配置文件copy到flume/conf下
project.sources= log-type project.channels= log-type project.sinks= log-type #source project.sources.log-type.type = org.apache.flume.source.kafka.KafkaSource project.sources.log-type.batchSize = 500000 project.sources.log-type.batchDurationMillis = 300000 project.sources.log-type.kafka.bootstrap.servers = kafka0:9092,kafka1:9092,kafka2:9092 project.sources.log-type.kafka.topics = project-udplog-log-type project.sources.log-type.kafka.consumer.group.id = project-udplog-log-type-t4 project.sources.log-type.kafka.consumer.auto.offset.reset = earliest ## channel project.channels.log-type.type = memory #project.channels.log-type.checkpointDir = /home/pirate/programs/flume/checkpoint/project/log-type #project.channels.log-type.dataDirs = /home/pirate/programs/flume/data/project/log-type/ #project.channels.log-type.maxFileSize = 2146435071 project.channels.log-type.capacity = 1000000 project.channels.log-type.transactionCapacity = 1000000 project.channels.log-type.keep-alive = 60 ## sinlog-type project.sinks.log-type.type = hdfs project.sinks.log-type.hdfs.path = hdfs://mycluster/user/pirate/flume/project/Log-Type/ds=%Y-%m-%d/hs=%H/ project.sinks.log-type.hdfs.batchSize = 500000 #project.sinks.log-type.hdfs.fileType = DataStream project.sinks.log-type.hdfs.callTimeout=60000 project.sinks.log-type.hdfs.threadsPoolSize = 100 project.sinks.log-type.hdfs.codeC = lzop # 注意:1.这里用 lzop;否则:创建 hive 外部分区表映射到相关路径,无法查询数据(待测) 2.也可以直接指定为snappy压缩,hive建表映射不需要更改,文本格式就能读取到 project.sinks.log-type.hdfs.fileType = CompressedStream #开启压缩 ## project.sources.log-type.channels = log-type project.sinks.log-type.channel= log-type project.sinks.log-type.hdfs.minBlockReplicas=1
启动:
nohup /home/atone/programs/flume/bin/flume-ng agent -n project -c $flume/conf/ -f /home/atone/programs/flume/job/test-snappy.conf -Dflume.monitoring.type=http -Dflume.monitoring.port=34550 -Dflume.root.logger=WARN,LOGFILE -Dflume.log.file=./test_flume_log.log 2>&1 &
结果示例: