1. ASCII和Ansi编码
字符内码(charcter code)指的是用来代表字符的内码
.读者在输入和存储文档时都要使用内码,内码分为
单字节内码 -- Single-Byte character sets
(SBCS),可以支持256个字符编码.
双字节内码 -- Double-Byte character sets)
(DBCS),可以支持65000个字符编码.
前者即为ASCII编码,后者对应ANSI.
至于简体中文编码GB2312,实际上它是ANSI的一个代
码页936
2.Unicode符号集
正如上一节所说,世界上存在着多种编码方式,同一个二
进制数字可以被解释成不同的符号。因此,要想打开一个
文本文件,就必须知道它的编码方式,否则用错误的编码
方式解读,就会出现乱码。为什么电子邮件常常出现乱码
?就是因为发信人和收信人使用的编码方式不一样。而
Unicode就是这样一种编码:它包含了世界上所有的符号,
并且每一个符号都是独一无二的。比如,U+0639表示阿拉
伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉
字“严”。具体的符号对应表,可以查询unicode.org,或
者专门的汉字对应表 。很多人都说Unicode编码,但其实
Unicode是一个符号集(世界上所有符号的符号集),而不
是一种新的编码方式。
但是正因为Unicode包含了所有的字符,而有些国家的字符
用一个字节便可以表示,而有些国家的字符要用多个字节
才能表示出来。即产生了两个问题:第一,如果有两个字
节的数据,那计算机怎么知道这两个字节是表示一个汉字
呢?还是表示两个英文字母呢?第二,因为不同字符需要
的存储长度不一样,那么如果Unicode规定用2个字节存储
字符,那么英文字符存储时前面1个字节都是0,这就大大
浪费了存储空间。
上面两个问题造成的结果是:1)出现了unicode的多种存
储方式,也就是说有许多种不同的二进制格式,可以用来
表示unicode。2)unicode在很长一段时间内无法推广,直
到互联网的出现。
3.UTF-16
说到 UTF 必须要提到 Unicode(Universal Code 统一码
),ISO 试图想创建一个全新的超语言字典,世界上所有
的语言都可以通过这本字典来相互翻译。可想而知这个字
典是多么的复杂,关于 Unicode 的详细规范可以参考相应
文档。Unicode 是 Java 和 XML 的基础,下面详细介绍
Unicode 在计算机中的存储形式。
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。
UTF-16 用两个字节来表示 Unicode 转化格式,这个是定
长的表示方法,不论什么字符都可以用两个字节表示,两
个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符
非常方便,每两个字节表示一个字符,这个在字符串操作
时就大大简化了操作,这也是 Java 以 UTF-16 作为内存
的字符存储格式的一个很重要的原因。
4.UTF-8
UTF-16 统一采用两个字节表示一个字符,虽然在表示上非
常简单方便,但是也有其缺点,有很大一部分字符用一个
字节就可以表示的现在要两个字节表示,存储空间放大了
一倍,在现在的网络带宽还非常有限的今天,这样会增大
网络传输的流量,而且也没必要。而 UTF-8 采用了一种变
长技术,每个编码区域有不同的字码长度。不同类型的字
符可以是由 1~4 个字节组成。
UTF-8 有以下编码规则:
如果一个字节,最高位(第 8 位)为 0,表示这是一个
ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是
UTF-8 了。
如果一个字节,以 11 开头,连续的 1 的个数暗示这个字
符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字
符的首字节。
5.GBK/GB2312/GB18030
GBK和GB2312都是针对简体字的编码,只是GB2312只支持六
千多个汉字的编码,而GBK支持1万多个汉字编码。而
GB18030是用于繁体字的编码。汉字存储时都使用两个字节
来储存。
总的来说:
ASCII编码:用来表示英文,它使用1个字节表示,其中第
一位规定为0,其他7位存储数据,一共可以表示128个字符
。
拓展ASCII编码:用于表示更多的欧洲文字,用8个位存储
数据,一共可以表示256个字符
GBK/GB2312/GB18030:表示汉字,用两个字节表示。
GBK/GB2312表示简体中文,GB18030表示繁体中文。
Unicode编码:包含世界上所有的字符,是一个字符集。
UTF-8:是Unicode字符的实现方式之一,它使用1-4个字节
表示一个符号,根据不同的符号而变化字节长度。
UTF-16:
UTF-8:是Unicode字符的实现方式之一,它使用2个字节表
示一个符号
关于乱码:
乱码问题的产生最根本的原因就是使用错误的字符集解码字节流或者将给定的字符串用错误的字符集编码成错误字节流造成的,例如”中文”两个汉字,如果用ISO8859-1字符集将其编码为字节流,因为这个字符集不支持中文,所以就会出错,输出结果为3f3f,其意义就是??。再例如”中文”二字的GBK的字节流为d6 d0 ce c4,可是我们要是用不兼容的字符集去解码,例如用ISO8859-1或者UTF-8,这随后产生的字符串就是乱码,或者是其他的某个字符。
解决java编程中出现乱码的方法:
从开发Java程序到运行Java程序的过程中都存在着编码问题,所以要想避免乱码产生,就必须了解在其中任何时候的编码处理的情况。
1、源代码:在编写java源代码的时候,我们必须把编写的文本保存在文件中,这个时候不管用什么编辑器,都存在一个问题,就是以什么样的字符集将这些源代码(包含汉字)保存到文件中,大部分编辑器都会通过系统的环境变量得到系统的当前默认字符集,编辑器就会使用这个字符集将我们编写的源代码保存到文件中。一般我们的中文Windows系统的默认字符集是GB18030,AIX英文环境的默认字符集是ISO8859-1,AIX中文环境的默认字符集是IBM-eucCN。
2、编译:在编译.java文件的时候如果使用默认处理,则javac会使用系统当前的默认字符集去读取源文件,将源文件的内容转换为UTF-8编码,然后在进行编译,这时我们也可以通过-encoding参数指定一个字符集,让javac使用我们指定的字符集去读取源代码然后在转换为UTF-8,然后编译。编译以后产生的class文件内部所有的中文字符都是用UTF-8的字符集进行编码的,这就是Java程序能处理任何国家文字的原因。
3、运行时:Java程序在运行时,需要使用程序内部定义的中文字符串,也可能会使用从外部读取的中文字符串,这些经过处理,可能都会输出到程序外部,在这些 过程中都涉及到编码的转换,程序内部定义的字符串都是用UTF-8存储的。而从外部读取和输出到程序外部的输出又使用什么字符集进行处理呢?在我们没有在 程序中特别指定的情况下,JVM会根据系统属性确定使用哪个字符集,这个系统属性的名称为file.encoding,我们可以在启动java程序的时候通过-D参数设定这个值,如果没有设定,JVM会根据系统环境变量确定这个系统属性,一般我们的中文Windows系统的默认字符集是GB18030,AIX英文环境的默认字符集是ISO8859-1,AIX中文环境的默认字符集是IBM-eucCN。这样JVM在处理输入数据的时候就会把字节流根据这个参数进行解码,然后转成UTF-8格式,在Java程序内部处理,然后再根据这个参数把处理后的数据编码,输出到程序外部。这就是Java程序运行时字符集的使用情况。
现在有一个问题,我们平时都是Windows的中文环境下做开发,然后拿到AIX系统上去运行,AIX系统的默认语言环境是英文环境,这样就会出现乱码,分析过程如下:源文件编码格式为GB18030,默认编译,也采用GB18030读取源文件,正常转换为UTF-8,生成class文件,运行时没有进行特殊设置,语言环境为英文环境,默认编码为ISO8859-1,这样在输出中文的时候会把正常的UTF-8表示的汉字用ISO8859-1的字符集去编码生成字节流,因为ISO8859-1不支持汉字,结果输出的都是’?’。可是这个时候却发现,由外界输入给java程序的中文字符,却能正常输出,这又是为什么,其实这个也是运行时的默认字符集ISO8859-1造成的,Java程序运行时,在读取外部进入的字节流的时候,如果使用默认的读取方式,也是使用ISO8859-1的字符集进行解码处理,这样中间的处理过程中,中文都已经不是原来的中文了,也就是说我们这个时候处理根本不是我们认为的中文,而是一对乱码,虽然是乱码,但是其中的信息却没有丢失,在处理完后,在经过一次ISO8859-1的编码,又还原为正常的GB18030的编码输出,所有没有出现乱码。我们以前的解决方法是,在编译原文件的时候指定参数-encoding ISO8859-1,让编译器用ISO8859-1的字符集去解码源文件编译,然后运行程序,这时再输出程序的内部中文字符串也不是乱码了。看起来一切都解决了,可是却没有从根本上解决问题,class文件变得比平常大很多,程序中用到中文越多,class文件变大的越快。而且其中的中文信息也变味了。
另一个问题,如果我们正常编译程序,在AIX系统上线设定为中文环境,然后再运行Java程序,这样既不会使程序变大,也不会使中文变味,可是用了一段时间又发现问题了,处理过程中如果遇到偏僻的中文字,还是乱码,原因是AIX的中文环境使用的字符集是IBM-eucCN,我认为可能是这个字符集缺少偏僻汉字,无法解释其内容,所以偏僻字变成了乱码了。
最后的解决办法是,在Windows中文环境下正常编写原程序,用默认的方式编译生成class文件,或者编译时指定参数-encoding GB18030,这样汉字都能正常解释并转换为UTF-8存储在class文件中,在运行的时候,我们需要制定参数,java –Dfile.encoding=GB18030 。。。。。,系统环境使用默认英文即可,这样JVM就不会根据系统的环境设定默认字符集,而是所有输入输出都使用我们指定的字符集,这样不但解决了英文环境下的中文输出问题,而且还解决了偏僻字的显示问题。
结论是,如果是源代码乱码,原因是保存源代码的时候的编码方式与打开源代码的时候的编码方式不一致,这时只需要转换编辑器的编码方式与保存时候的编码方式一致即可解决乱码问题;如果是编译的时候出现乱码,javac会使用系统当前的默认字符集去读取源文件,所以需要将编码方式改为系统默认的编码方式;如果是运行时产生乱码,就需要在运行java程序的时候加上指令java –Dfile.encoding= **(运行平台的默认字符集)即可
例子:
源代码乱码
保存时编码方式为:ANSI

将编码方式改为utf-8时,源代码出现乱码

但这时候编译正常通过并没有问题

原因是虽然修改编码方式,但是并没有改变源代码保存时候的编码方式,他仍然是以系统
默认的编码方式保存的,虽然在编辑器上看起来乱码,但在编译的时候以系统默认的字符集去编译是不会产生乱码的。
编译乱码:
上面例子如果我转换了编码方式,把他转为utf-8编码
其编译就会出错。
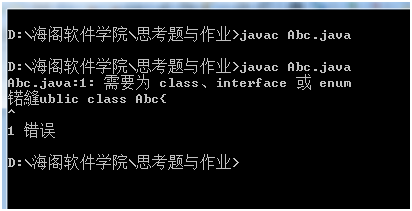
转回ANSI又能编译通过

运行时异常,由于笔者手头上没有别的运行系统了,就不再示范,请读者自行试验。
关于io操作时候的乱码现象,也是由于编码方式与解码方式不同造成的,下面给出几个例子

此例程是以utf8的编码方式写进文件,以utf16的解码方式读取文件,导致输出乱码:

如果改回utf8的解码方式:


显示正常,同理,如果写入时候的编码方式不一样,也会造成乱码:

以utf16的编码方式读取的test再以utf8的编码方式写进test2,结果造成乱码
还有其他一些例子不再一一列子,读者请自行尝试。