- 认识Spark SQL
- 认识Spark Streaming
Spark SQL
Competitor
- Hive
- Apache Drill
- Amazon EMR
Data Sources
- JSON
- CSV
- Parquet
- Hive
Adventage
- Optimizations
- Predicate push down
- Column pruning
- Uniform API
- Eazy to change between SQL and RDD
实战示例
// define data
import sqlContext.implicits._
case class Company(name: String, employeeCount: Int, isPublic: Boolean)
val companies = List(
Company("ABC Corp", 25, false),
Company("XYZ Inc", 5000
, true),
Company("Sparky", 400, true),
Company("Tech Retail", 1000, false),
Company("Some Place", 75, false)
)
// read data from collection
val companiesDF = companies.toDF
val companiesDF = sqlContext.createDataFrame(companies)
companiesDF.show
// read data from file
val companiesJsonDF = sqlContext.read.json("file:///Data/Companies.json")
val companiesJsonDF = sqlContext.format("json").load("file:///Data/Companies.json")
companiesJsonDF.printSchema
// union two val
val allCompaniesDF = companiesDF.unionAll(companiesJsonDF)
val companiesJsonIntDF = companiesJsonDF.select($"name", $"employeeCount".cast("int").as("employeeCount"), $"isPublic")
val allCompaniesDF = companiesDF.unionAll(companiesJsonIntDF)
allCompaniesDF.groupBy(allCompaniesDF.col("isPublic")).agg(avg("employeeCount")).show
allCompaniesDF.where($"employeeCount" > 1000).show
allCompaniesDF.where(allCompaniesDF.col("employeeCount").gt(1000))
// output result
import org.apache.spark.sql.Row
allCompaniesDF.map(company=>company(0).asInstanceOf[String]).foreach(println)
allCompaniesDF.write.json("file:///Data/all.json")
allCompaniesDF.registerTempTable("Companies")
// use SQL query directly
sql("SELECT * FROM Companies").show
sql("SELECT AVG(employeeCount) AS AverageEmpCount FROM Companies GROUP BY isPublic").show
sql("CACHE TABLE Companies")
sql("CACHE LAZY TABLE Companies")
Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
Streaming顾名思义,即实时流数据处理。
举例,比如某工厂有一套精密仪器设备,需要全天24小时监控各个机器的各项指标,温度,质量,流量,等等元数据,然后再做进一步模型计算。数据每30s采集一次,如果等每天收工再处理,不仅耗时,而且也不及时。所以需要实时地计算并展示,这就用到了实时流数据处理。
Spark和Spark Streaming最大的区别是
- 前者是每天的数据不停地过来,但是“不处理”,堆在一个地方,最后统一处理。相当于数据是“离线”的。
- 后者是数据实时过来,实时处理。这里多了一个按照一定时间间隔,对数据进行拆分的过程。
处理过程
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
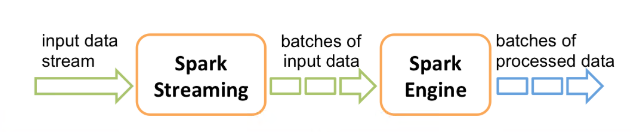
基本框架
Spark Streaming的框架,最常见的是kafka+Spark Streaming。

Spark Streaming其实是将连续的数据离散化,持久化,然后进行批量处理的操作。
DStreams
Discretized Streams (DStreams): It represents a continuous stream of data, either the input data stream received from source, or the processed data stream generated by transforming the input stream.
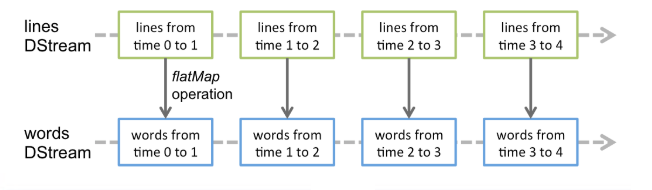
DStreams,是一个很重要的抽象概念,可以看作一组RDDs序列,处理逻辑都相同,唯一的不同是时间维度。
为什么要有这个概念?因为在Spark Streaming中,大量的操作都是基于DStreams,如下:
var twitterStream = TwitterUtils.createStream(ssc, None)
twitterStream.flatMap(tweet=>getHashTags(tweet))
.countByValueAndWindow(Seconds(15), Seconds(10))
.map(tagCountTuple=>tagCountTuple.swap)
.transform(rdd=>rdd.sortByKey(false))
.print
注:任何对DStream的操作都会转变为对底层RDD的操作(通过算子)。
Persistence
- calling
persist()to persist every RDD of that DStream in memory - DStreams generated by window-based operations are automatically persisted in memory, without the developer calling persist().
- For input streams that receive data over the network (such as, Kafka, sockets, etc.), the default persistence level is set to replicate the data to two nodes for fault-tolerance.
- unlike RDDs, the default persistence level of DStreams keeps the data serialized in memory.
Reference
- Spark Streaming Guild: https://spark.apache.org/docs/latest/streaming-programming-guide.html
- Spark Streaming Post: https://www.cnblogs.com/fishperson/p/10447033.html