编写 调试具有多个段的程序
1.将下面的程序编译、连接,用Debug加载、跟踪。
assume cs:code, ds:data, ss:stack
data segment
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h
data ends
stack segment
dw 0, 0, 0, 0, 0, 0, 0, 0
stack ends
code segment
start:mov ax,stack
mov ss, ax
mov sp,16
mov ax, data
mov ds, ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
我们先编译,连接一下
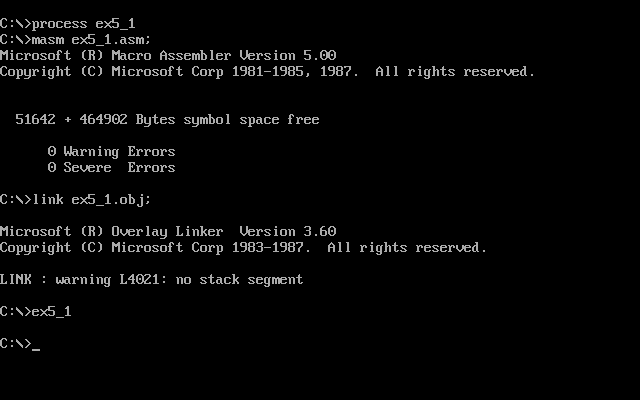
然后用Debug加载,跟踪,并用r命令查看cx保存的程序段的长度为42h
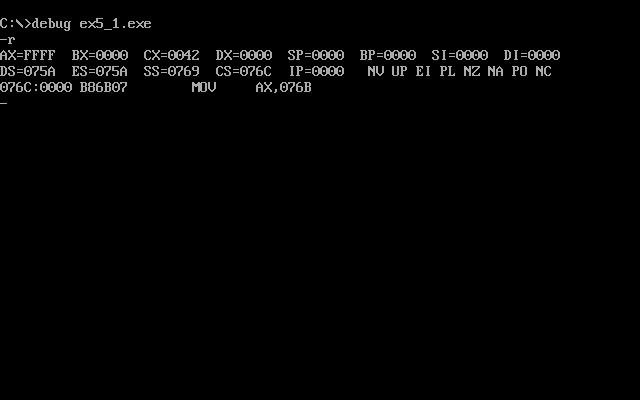
根据代码我们可以知道,ds和ss内各有8个字数据,也就各占了16个字节,总共占了32个字节,转化为16进制,就是0020h,那么,我们反汇编就到(0042h-0020h)=0022h,如图
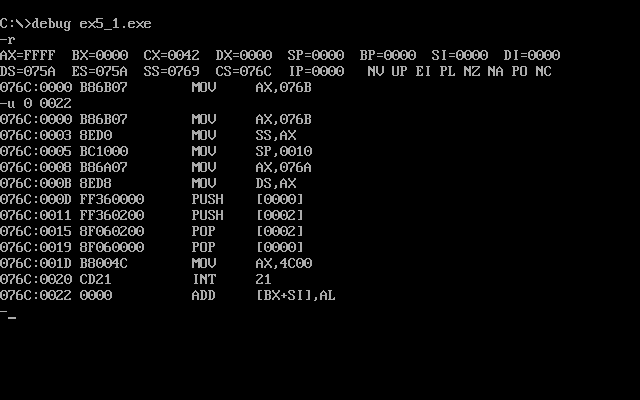
实验要求我们查看程序返回前的数据,那么我们就用g命令将程序执行到001dh,如图
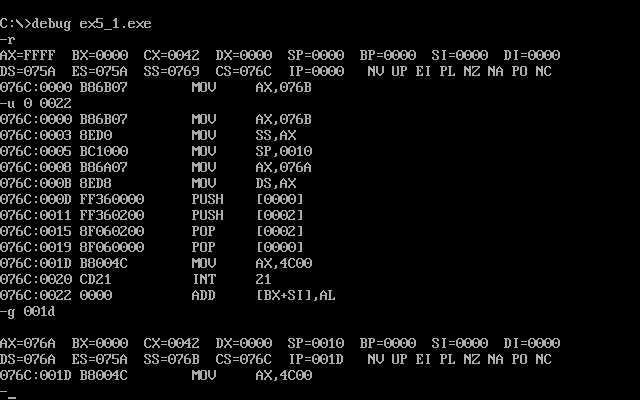
然后用d命令查看data段内的数据
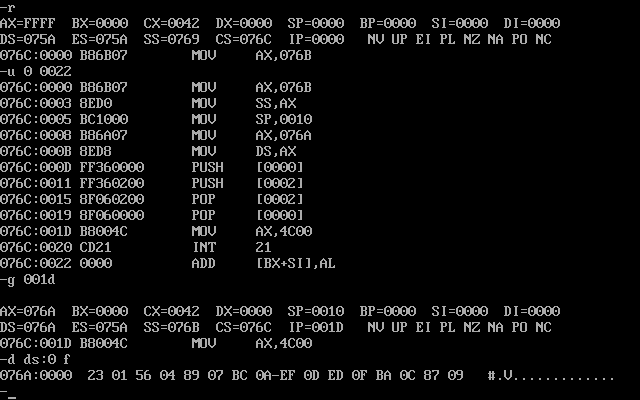
- CPU执行程序,程序返回前,data段中的数据如图所示

在经历了line18~line21的程序后它没有发生变化,主要原因是pop是改变了[0]和[2]的先后顺序,如果先pop[0]的话,data段前4个字节的数据就会变成56 04 23 01了
- CPU执行程序,程序返回前,cs=076C、ss=076B,ds=076A
- 设程序加载后,code段的段地址为X,则data段的段地址为X-2,stack段的段地址为X-1.(这是根据第二问的答案推测得出)。
2.将下面的程序编译、连接,用Debug加载、跟踪
assume cs:code, ds:data, ss:stack
data segment
dw 0123h, 0456h
data ends
stack segment
dw 0, 0
stack ends
code segment
start:mov ax,stack
mov ss, ax
mov sp,16
mov ax, data
mov ds, ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
编译连接跟踪同第一个实验
因为代码段和第一个实验一样,所以它们的长度也是一样的,我们直接可以得出0022h并且用g命令执行到001dh
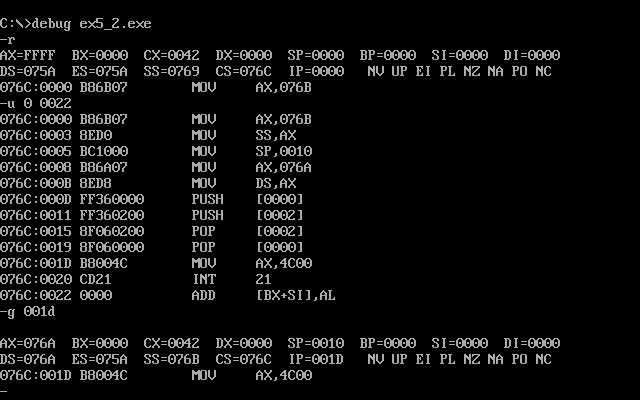
然后用d命令查看data内的数据
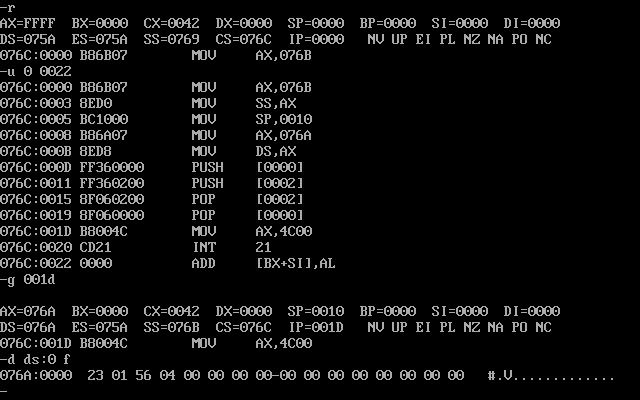
它并没有变化,理由同第一个实验
- CPU执行程序,程序返回前,data段中的数据如图所示

- CPU执行程序,程序返回前,cs=076C、ss=076B,ds=076A
- 设程序加载后,code段的段地址为X,则data段的段地址为X-2,stack段的段地址为X-1.(这与实验一并没有什么不同)
- 对于如下定义的段
name segment
...........
name ends
如果段中的数据占N个字节,则程序加载后,该段实际占有空间为多少?
做这题时,我们先看看第二个实验的代码,line2~line4可看出,data段内的数据只占4个字节,而line6~line8也可看出stack段内的数据只占4个字节,可是,我们跟踪时发现,cx保存的程序段的长度依旧是42h

那么根据第一个实验推理,我们可以得出,data段占有的空间是16个字节,同时,第一个实验中data段的数据有16个字节,cx也是42h,那么,依此延伸,我们猜测1<=N<=16时,data段占有的空间为16个字节,N>16时,我们改变一下数据
现在data段内的数据占18个字节,接下来跟踪一下看看cx保存的程序段的长度为多少
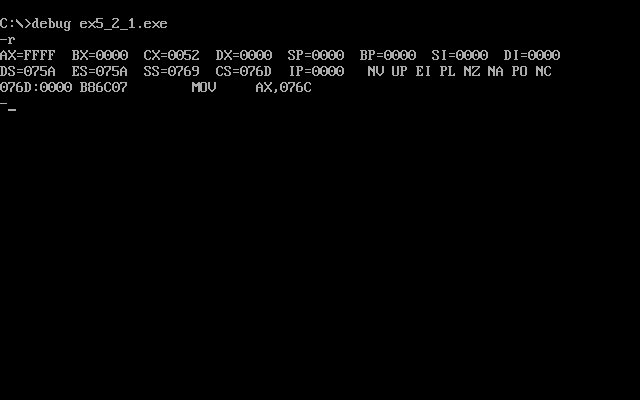
可见,cx=52h,那么data段占有空间为32个字节,以此推理,当段中的数据占N个字节,则程序加载后,该段实际占有的空间为((N+15)/16)×16,此处(N+15)/16取小于该数的最大整数。
那么第四题的答案就得出来了。
当然,网上有更加正经的答案,但我不大明白,只能用这种方法计算出答案。
在8086CPU架构上,段是以paragraph(16-byte)对齐的。程序默认以16字节为边界对齐,所以不足16字节的部分数据也要填够16字节。“对齐”是alignment,这种填充叫做padding。16字节成一小段,称为节(参考来源https://blog.csdn.net/friendbkf/article/details/48212887)
3.将下面的程序编译、连接,用Debug加载、跟踪。
assume cs:code, ds:data, ss:stack
code segment
start:mov ax,stack
mov ss, ax
mov sp,16
mov ax, data
mov ds, ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
data segment
dw 0123h, 0456h
data ends
stack segment
dw 0,0
stack ends
end start
我们省略掉相同的操作,直接查看吧
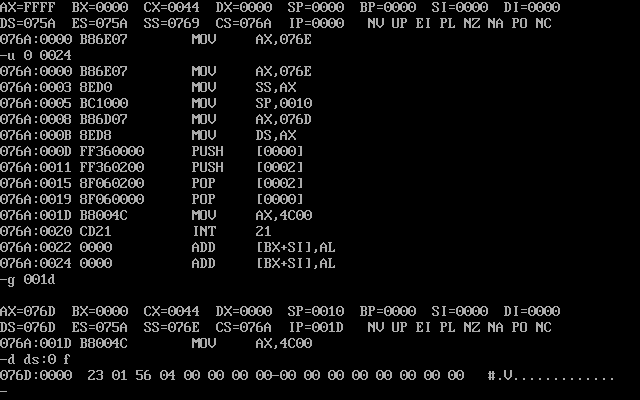
- CPU执行程序,程序返回前,data段中的数据如图所示

- CPU执行程序,程序返回前,cs=076A、ss=076E,ds=076D
- 设程序加载后,code段的段地址为X,则data段的段地址为X+3,stack段的段地址为X+4.(data段与stack段依旧按顺序排列,但code段与data段隔开了两个段,以及cx保存的程序段的长度多了两个字节,但不知道多在哪里,此处存疑)
4.如果将1、2、3题中的最后一条伪指令“end start”改为“end”(也就是说,不指明程序的入口),则哪个程序任然可以正确执行?请说明原因。
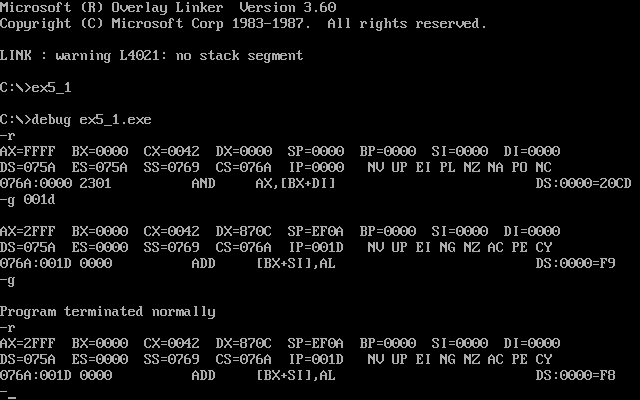
第一个程序可运行,但结果不同
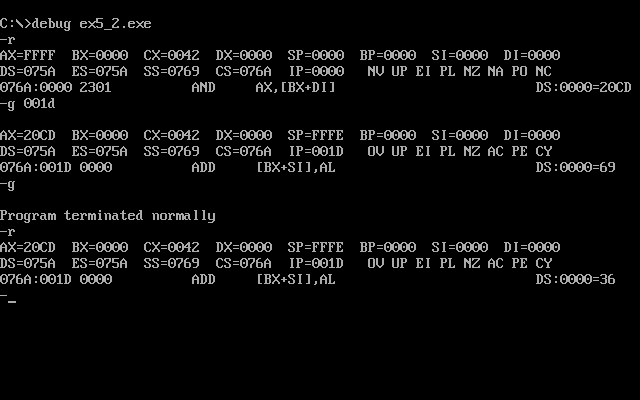
第二个程序结果也是不一样的
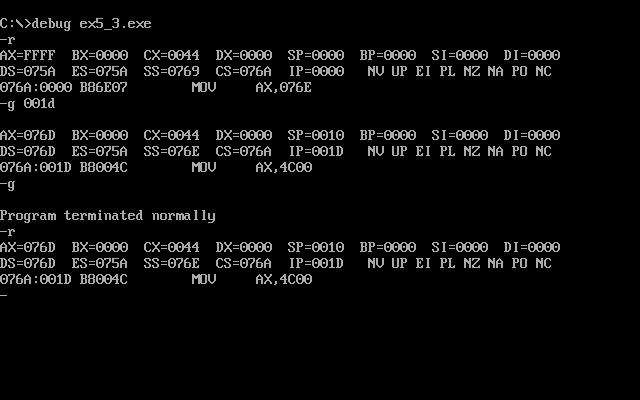
第三个程序没有任何改变
第三个程序可以正常执行,因为在不指明程序入口的情况下,程序入口默认SA+10h:0,即ds:0,第三个程序入口地址正好指向程序入口,而1、2两个程序入口地址指向数据存储的地方,无法正常执行。
5.程序如下,编写code段中的代码,将a段和b段中的数据依次相加,将结果存入到c段中。
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment ; 在集成软件环境中,请将此处的段名称由c→改为c1或其它名称
db 8 dup(0)
c ends ; 改的时候要成对一起修改
code segment
start:
;?
code ends
end start
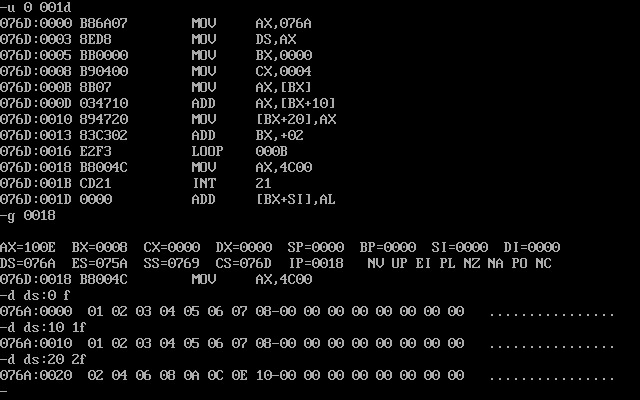
我们看看line3、line7和line11,他们使用db的存储方式,即只能存储byte单字节,也就是说每一段的数据只占8个字节,但根据第三个实验,我们知道,每一段所占的空间仍是16个字节,所以a段的地址为a:0,b段为a:10h,c段为a:20h,那么添加的代码如下
mov ax,a
mov ds,ax
mov bx,0
mov cx,4
s: mov ax,ds:[bx]
add ax,ds:[bx+10h]
mov ds:[bx+20h],ax
add bx,2
loop s
mov ax,4c00h
int 21h
最后结果如图
6.程序如下,编写code段中的代码,用push指令将a段中的前8个字型数据,逆序存储到b段中。
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh
a ends
b segment
dw 8 dup(0)
b ends
code segment
start:
;?
code ends
end start
首先我们设置栈段,ss为b,因为b内存储了8个字数据,所以有16个字节,栈顶的初始位置为ss:10h,栈底的初始位置为ss:e,然后设置数据段ds为a,然后用push将a段内的数据压栈,我所加的代码如下
mov ax,b
mov ss,ax
mov sp,10h
mov ax,a
mov ds,ax
mov bx,0
mov cx,8
s: push ds:[bx]
add bx,2
loop s
mov ax,4c00h
int 21h
最终运行结果如下
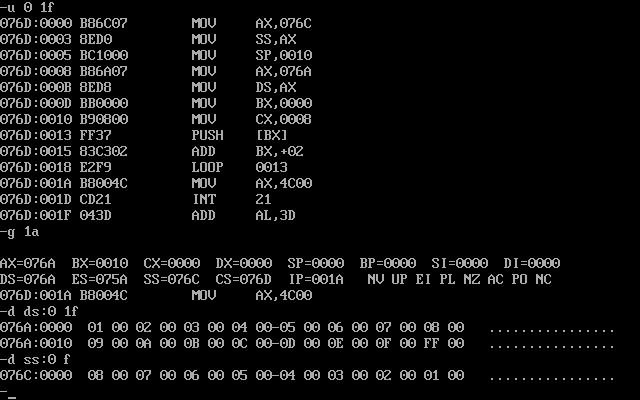
可见,程序成功将数据逆序存入b段内。