针对大量并行数据的处理(DLP),有SIMD和MIMD两种结构,
SIMD:能效比方面更好,对程序员编程更加友好,顺序编程的思想。
MIMD:性能更高,但是对硬件资源要求很大。
所以针对个人移动设备,SIMD更加适合。
SIMD有三种实现过的体系结构:
向量体系结构:比较容易理解,就是通过将分散数据变为向量,然后再统一运算的方式。
缺点是会增大芯片面积,要求硬件能够提供较大的DRAM带宽。
SIMD指令集变种:特别是针对浮点运算,通过SIMD的指令集扩展,来提高性能。从MMX(多媒体指令扩展)一直发展到现在的
AVX(高级向量扩展)
GPU结构,潜在性能高于目前多数的多核计算机,GPU的很多特性与向量体系结构基本类似,但是GPU有自己的一些特征。
在GPU中,不仅有GPU及其图形存储器,还有系统处理器和系统存储器。
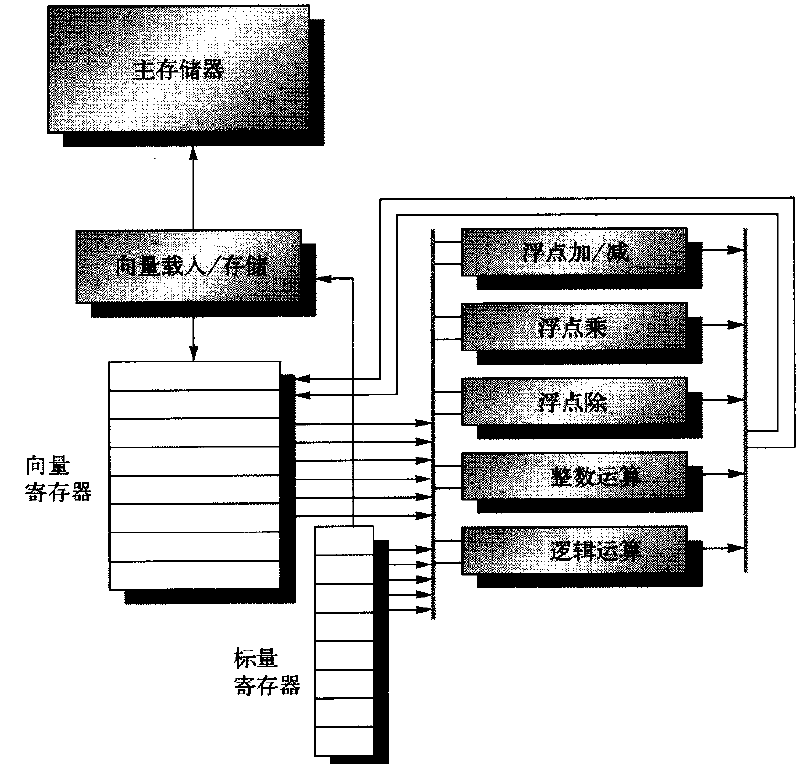
向量体系结构:
在向量体系结构中,操作获得存储器散布的多个数据元素,将他们放在自己的一个大型顺序寄存器堆中,然后再对这些寄存器堆
中的数据进行向量操作,从而实现对散布独立元素的数十个"寄存器----寄存器"操作。
这些大型的顺序寄存器堆相当于是编译器控制的缓冲区,一方面隐藏存储器延时,一方面充分利用存储器带宽,这些数据向量的
载入和存储都是尝试流水化的,从而将延时分散到N个元素上,进一步减少存储器延时时间。
以VMIPS为例来进行说明:
它的标量部分是MIPS结构,在加上MIPS的向量逻辑扩展部分组成。
向量寄存器:VMIPS有8个向量寄存器,每个向量寄存器保留64个元素,每个运算64bit。重点是需要提供足够的端口来保证
可以将数据连接到向量功能单元的输入输出口。(一组交叉交换器,16个读端口和8个写端口)
向量功能单元:每个单元都是完全实现流水化。重点是需要有控制单元来检测冒险,包括功能单元的结构性冒险,又包括寄存器
访问的数据冒险。
向量载入/存储单元:VMIPS向量载入与存储器操作时完全流水化的,在初始延时之后,可以在一个时钟周期,移动一个向量寄存器
这个单元还会处理标量载入和存储。
标量寄存器:标量寄存器可以提供数据,作为向量功能单元的输入,也可以将数据传送给向量载入/存储单元,
向量体系结构的优点:一方面可以提高性能,一方面不需要高度乱序超标量处理器的设计复杂度。
采用向量指令,系统可以同时对很多元素进行操作,所以功能单元可以采用慢而宽的设计方式。以较低功率获得高性能。
由于各个元素的相互独立,不需要进行高成本的相关性检查。
向量本身可以容纳不同大小的数据,例如,一个向量寄存器可以容纳64个64位元素,128个32位元素。所以向量体系结构可以
用在多媒体应用和科学应用方面。
以一运算为例,Y = a x X + Y
a为标量,X,Y为向量。如果使用MIPS结构,则需要加入loop,而且乘运算和加运算之间存在流水线互锁的问题。
如果使用VMIPS结构,可以大幅的缩减动态指令数据,且只有在向量载入和存储的时候,可能会有流水线停顿。
当代码经过编译器,额可以生成向量指令时,我们将这种代码称为可向量化和已向量化。
向量长度寄存器(VLR),VLR控制着所有向量运算的长度,包括向量载入和存储。特定向量运算在编译时是未知的,所以
需要VLR寄存器来表示,当前的向量长度。
最大向量长度(MVL),确定了体系结构中一个向量最多的元素数目。这个参数意味着向量寄存器的长度可以随着计算机的发展
而增大,不需要改变指令集。多媒体扩展SIMD没有对MVL对应的参数,所以每次增加向量长度,需要改变指令集。
如果在编译中,发现需要的向量长度比MVL大,可以将循环分为两部分,外循环和内循环。
代码向量化程度不高的两个主要原因是,循环内存在条件(控制相关),稀疏矩阵。
针对存在条件控制的情况,比较常见的是通过向量遮罩控制来实现,
向量遮罩寄存器,任何向量指令都只会针对符合特定条件的向量元素来执行,即这些元素在向量遮罩寄存器中相应项目为1。
清楚向量遮罩寄存器会将其置为全1,后续向量指令将针对所有向量元素运算。
向量处理器与GPU的一个区别就是他们处理条件语句的方式不同,向量处理器将遮罩寄存器作为体系结构状态的一部分。
依靠编译器来显示的控制遮罩寄存器。但是GPU则使用硬件来控制软件无法看到的内部遮罩寄存器。
内存组:为向量载入/存储提供带宽
为了能够给向量处理单元提供足够的数据,大多数的向量处理器都使用存储器组,允许多个独立访问,而不是进行简单的存储器交错。
原因:
1)向量计算机每个时钟周期,都可以进行多个载入和存储操作。存储器系统需要有多个组,并能够独立控制对这些组的寻址。
2)多数向量计算机支持载入和存储非连续数据字的功能,此时需要进行独立组寻址,而不是交叉寻址。
3)向量计算机支持多个共享同一存储器系统的处理器,每个处理器会产生自己的寻址流。
步幅
向量中的相邻元素字在内存中的位置可能不一定是连续的,对于那些要收集到一个寄存器的元素,他们之间的距离称为步幅。
for (i = 0; i < 100; i = i+1)
for (j = 0; j < 100; j = j+1)
{
for (k = 0; k < 100; k = k+1)
A[i][j] = A[i][j] + B[i][k] * D[k][j];
}
矩阵D的步幅是100个双字,矩阵B的步幅是1个双字
稀疏矩阵的处理
稀疏矩阵:其中K和M为索引向量
for (i = 0; i < n; i = i+1)
A[K[i]] = A[K[i]] + C[M[i]]
用于支持稀疏矩阵的主要机制是采用索引向量的集中---分散操作。
集中操作时取得索引向量,并在该向量中提取元素,结果得到向量寄存器中的一个密集向量
之后使用同一索引向量,通过分散存储操作,以扩展方式存储这一稀疏向量
尽管索引载入与存储(集中与分散)操作都可以流水化,但是由于存储器组在开始执行指令时是未知的。
所以它们的运行速度远低于非索引载入或存储操作。而且访问位置可能存在冲突,因此每次访问都会招致严重的延迟。
在GPU中,所有的载入操作都是集中,所有的存储都是分散。GPU需要将这些集中与分散操作转换为更高效的存储器单位步幅访问。
向量体系结构编程
向量体系结构的优势在于编译器可以在编译时告诉程序员:某段代码是否可以向量化,以及为什么不能向量化。
当前,以向量模式运行的程序能否成功,其主要影响因素是程序本身的结构:循环是否有真正的数据相关,是否能够调整它们的结构等。