概述
redis是一种nosql数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,并且他比memcached支持更多的数据结构
redis使用场景:
实时更新并且不重要的数据储存
- 登录会话存储:存储在
redis中,与memcached相比,数据不会丢失。 - 排行版/计数器:比如一些秀场类的项目,经常会有一些前多少名的主播排名。还有一些文章阅读量的技术,或者新浪微博的点赞数等。
- 作为消息队列:比如
celery就是使用redis作为中间人。 - 当前在线人数:还是之前的秀场例子,会显示当前系统有多少在线人数。
- 一些常用的数据缓存:比如我们的
BBS论坛,板块不会经常变化的,但是每次访问首页都要从mysql中获取,可以在redis中缓存起来,不用每次请求数据库。 - 把前200篇文章缓存或者评论缓存:一般用户浏览网站,只会浏览前面一部分文章或者评论,那么可以把前面200篇文章和对应的评论缓存起来。用户访问超过的,就访问数据库,并且以后文章超过200篇,则把之前的文章删除。
- 好友关系:微博的好友关系使用
redis实现。 - 发布和订阅功能:可以用来做聊天软件。
redis安装与进入
1)编译安装(5.0版本)
wget http://download.redis.io/releases/redis-5.0.0.tar.gz #如果报错connect refused则是因为httpd服务未打开 tar -zxvf redis-5.0.0.tar.gz yum install gcc yum install gcc-c++ cd redis-5.0.0 && make && make install
make test #检测是否有问题,如果出现You need tcl 8.5 or newer in order to run the Redis test,则需要安装
yum -y install tcl #安装后再重新检测(这两步不是必须的)
在redis-5.0.0的目录下移动redis.conf到/usr/local下 cp src/redis-server /usr/bin/ cp src/redis-cli /usr/bin/
去配置文件更改bind和daemonize yes (默认为no)
重启redis: redis-server 配置文件(redis.conf)&并执行:redis-cli -p 6379 -h 更改的ip
2)yum安装
yum install redis -y (3.2版本)
重启redis并编辑配置文件:更改bind
再执行:redis-cli -p 6379 -h 更改的ip
一、redis字符串
1)添加 (set key value) #如果重新赋值则会覆盖
set username mama
2) 查看 (get key)
get username #--->'mama'
3) 删除 (del key)
del username (mama) #再查看显示nil
4)查看过期时间
先设置添加的过期时间 set username mama ex 30 #ex + 时间(s) ttl username #查看过期时间 #如果时间超了或者没设置时间则显示 (integer) -1
5)查看当前redis中的所有key 进入redis后,默认在o库。
keys *
6)进入其他数据库
select index (下标)
二、列表操作(key)
在列表左边添加元素: lpush key value 将值value插入到列表key的表头。如果key不存在,一个空列表会被创建并执行lpush操作。当key存在但不是列表类型时,将返回一个错误。 在列表右边添加元素: rpush key value 将值value插入到列表key的表尾。如果key不存在,一个空列表会被创建并执行RPUSH操作。当key存在但不是列表类型时,返回一个错误。 查看列表中的元素: lrange key start stop 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,如果要左边的第一个到最后的一个lrange key 0 -1。 #0-1 列表内所有元素 移除列表中的元素: 移除并返回列表key的头元素: lpop key 移除并返回列表的尾元素: rpop key 指定返回第几个元素: lindex key index #下标 将返回key这个列表中,索引为index的这个元素。 获取列表中的元素个数: llen key 如: llen languages 删除指定的元素: lrem key count value 如: lrem languages 0 php 根据参数 count 的值,移除列表中与参数 value 相等的元素。count的值可以是以下几种: count > 0:从表头开始向表尾搜索,移除与value相等的元素,数量为count。 count < 0:从表尾开始向表头搜索,移除与 value相等的元素,数量为count的绝对值。 count = 0:移除表中所有与value 相等的值。
三、set集合的操作:
添加元素: sadd 集合 value1 value2.... 如: sadd team xiaotuo datuo
WRONGTYPE Operation against a key holding the wrong kind of value
#如果出现这种报错则是因为设置的key与前面的设置冲突了
查看元素: smembers set 如: smembers team 移除元素: srem set value #value不存在也不报错 如: srem team xiaotuo datuo 查看集合中的元素个数: scard set 如: scard team1 获取多个集合的交集: sinter set1 set2 如: sinter team1 team2 获取多个集合的并集: sunion set1 set2 如: sunion team1 team2 获取多个集合的差集: sdiff set1 set2 如: sdiff team1 team2
四、hash,哈希操作
添加一个新值:(hset 表 字段 内容) hset key field value 如: hset website baidu baidu.com 将哈希表key中的域field的值设为value。 如果key不存在,一个新的哈希表被创建并进行 HSET操作。如果域 field已经存在于哈希表中,旧值将被覆盖。
获取哈希中的field对应的值: hget key field #hget(表 字段) 如: hget website baidu
删除key中的某个field: #hdel 表 字段 hdel key field 如: hdel website baidu
获取某个哈希中所有的field和value: #hgetall 表 hgetall key 如: hgetall website
hkeys key #获取字段下所有的内容 如: hkeys website
获取某个哈希中所有的值: hvals key #字段中所有内容 如: hvals website
判断哈希中是否存在某个field: #需要field中存在值 hexists key field 如: hexists website baidu
获取哈希中总共的键值对: hlen key #hlen 表名 如: hlen website
12.事物操作:Redis事务可以一次执行多个命令,事务具有以下特征:
- 隔离操作:事务中的所有命令都会序列化、按顺序地执行,不会被其他命令打扰。
- 原子操作:事务中的命令要么全部被执行,要么全部都不执行。
-
开启一个事务:
multi
以后执行的所有命令,都在这个事务中执行的。
- 执行事务:
exec
会将在multi和exec中的操作一并提交。
- 取消事务:
discard
会将multi后的所有命令取消。
- 监视一个或者多个
key:
watch key...
监视一个(或多个)key,如果在事务执行之前这个(或这些) key被其他命令所改动,那么事务将被打断。
- 取消所有
key的监视:
unwatch
13.发布/订阅操作:(同一台主机上)
- 给某个频道发布消息:
publish channel message #设置发布端,只需要执行发送命令,就可以解放出来
- 订阅某个频道的消息:
subscribe channel #订阅端负责接收信息
持久化
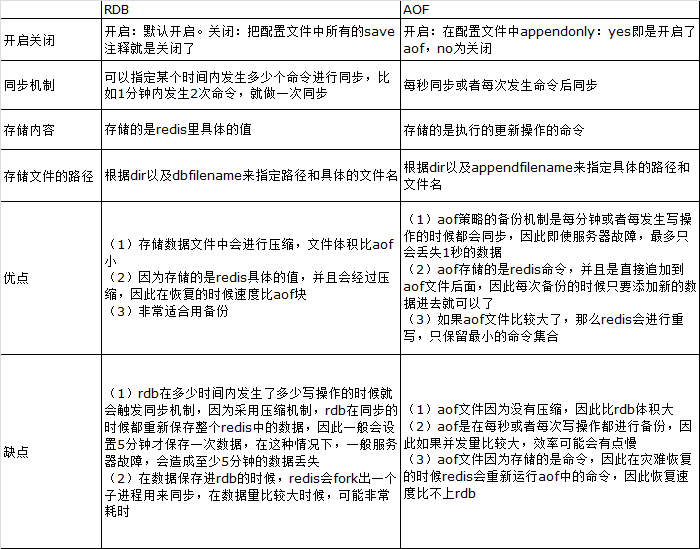
redis提供了两种数据备份方式,一种是RDB,另外一种是AOF,以下将详细介绍这两种备份策略
1、前言
最近在项目中使用到Redis做缓存,方便多个业务进程之间共享数据。由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化),另外一种是AOF持久化(原理是将Reids的操作日志以追加的方式写入文件)。那么这两种持久化方式有什么区别呢,改如何选择呢?网上看了大多数都是介绍这两种方式怎么配置,怎么使用,就是没有介绍二者的区别,在什么应用场景下使用。
2、二者的区别
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。

AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

3、二者优缺点
RDB存在哪些优势呢?
1). 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2). 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
3). 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4). 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
RDB又存在哪些劣势呢?
1). 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2). 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
AOF的优势有哪些呢?
1). 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
2). 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3). 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
4). AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
AOF的劣势有哪些呢?
1). 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
2). 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
二者选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 eventually consistent的意思了。不过生产环境其实更多都是二者结合使用的。
4、常用配置
RDB持久化配置
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
AOF持久化配置
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
5.如果需要自己添加密码可以在requirepass行下面添加:
requirepass ' 密码'
进入redis数据库后执行命令会需要密码认证,执行: auth ‘密码’ 即可
6.yum安装redis,或者需要自己设置进入ip的时候可以进入redis.conf配置文件,执行:
bind 本机ip(本来时127.0.0.1)
7.有的程序需要取消保护模式:
protection-mode no(本来是yes)