HDFS详细介绍
分布式文件系统设计思路
- 概述
只有一台机器时的文件查找:hello.txt /export/servers/hello.txt
如果有多台机器时的文件查找:hello.txt node02 /export/servers/hello.txt
为了解决数据丢失的问题,引入副本机制,保证数据不会丢失
如果对文件进行切块存储,那么元数据信息又要继续变化
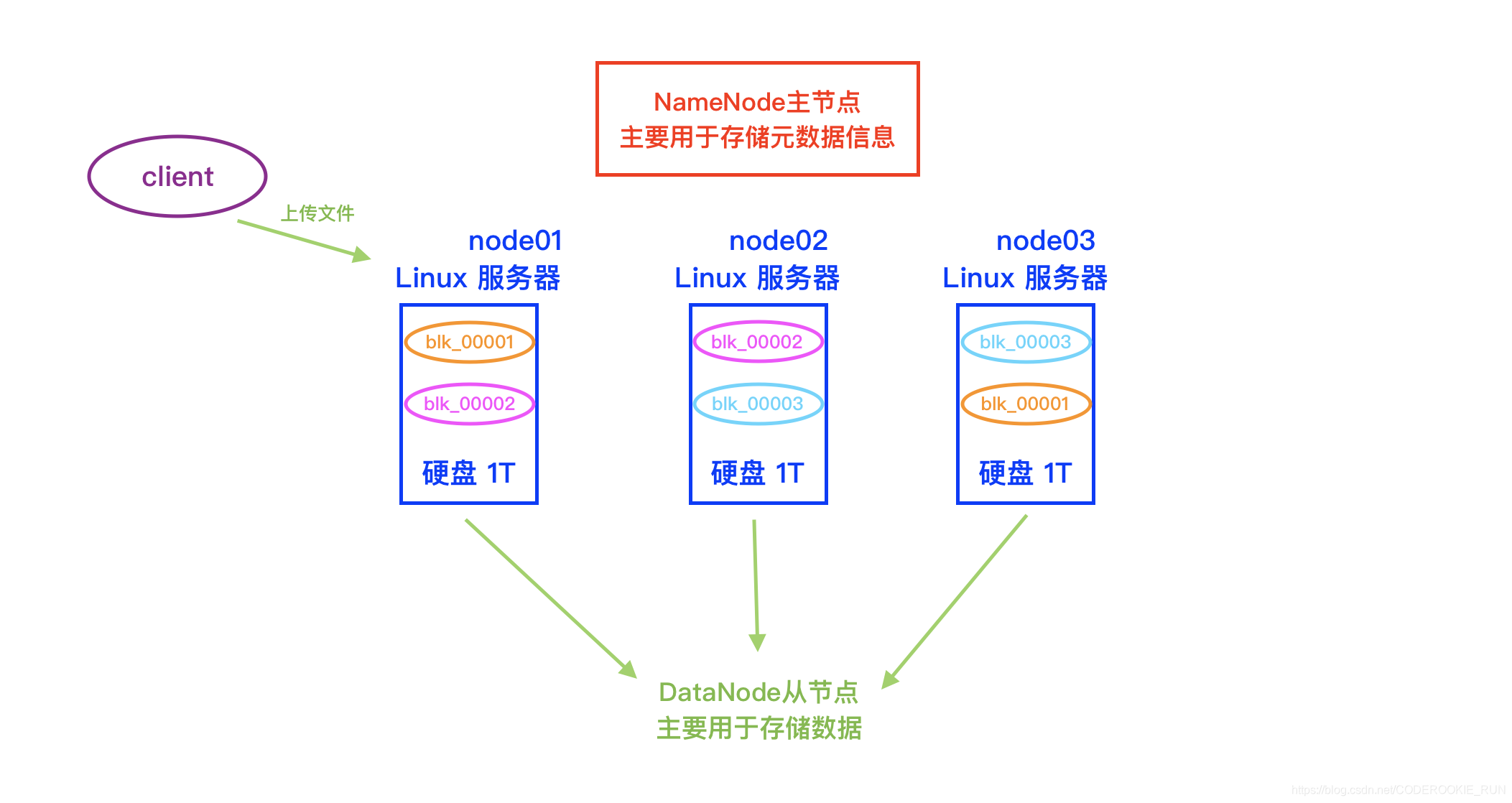
blk元数据信息的记录
blk_00001 node01 node03 /export/servers/blk_00001
blk_00002 node02 node01 /export/servers/blk_00002
blk_00003 node03 node02 /export/servers/blk_00003
- 概念简图
文件系统基本介绍
- 概览

- 重点了解
Local:本地文件系统
HDFS:分布式文件系统(最重要)
HSFTP:FTP文件系统 ftp:// 可以做文件的上传下载
WebHDFS:浏览器操作文件系统,可以允许我们通过浏览器上传、下载、修改HDFS上面的文件
HDFS文件系统的设计目标
- 概述
1.硬件错误,特别是硬盘的损坏是常态(副本机制解决)
2.数据流访问,所有的访问都是访问大量的数据,使用IO流一直操作,追求的是稳定,不是效率
3.大数据集,假设所有存储到hdfs的数据都是海量的数据,不擅长处理小文件(因为一个小文件会占用一个元数据,元数据都存储在内存当中,大量的小文件会产生大量的元数据,导致占用NameNode大量内存)
4.简单的相关模型,假设文件是一次写入,多次读取,不会有频繁的更新(比较擅长存储一些历史数据)
5.移动计算比移动数据便宜
6.多种软硬件的可移植性
HDFS基础架构图
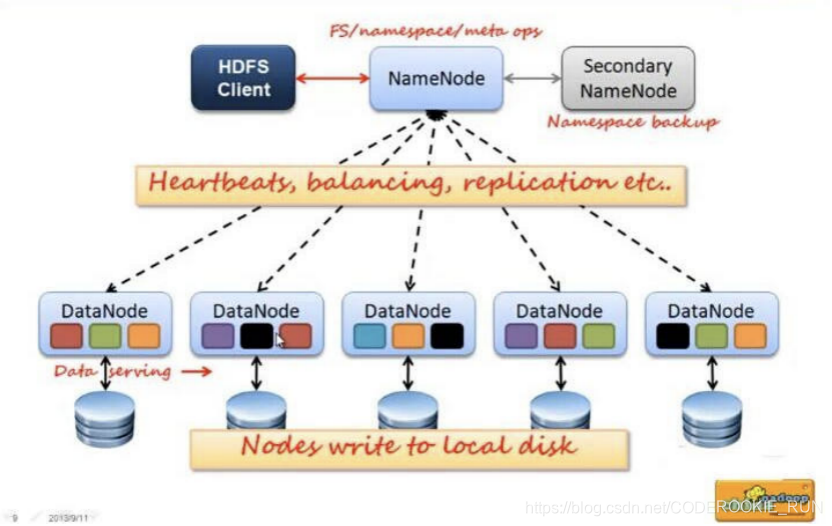
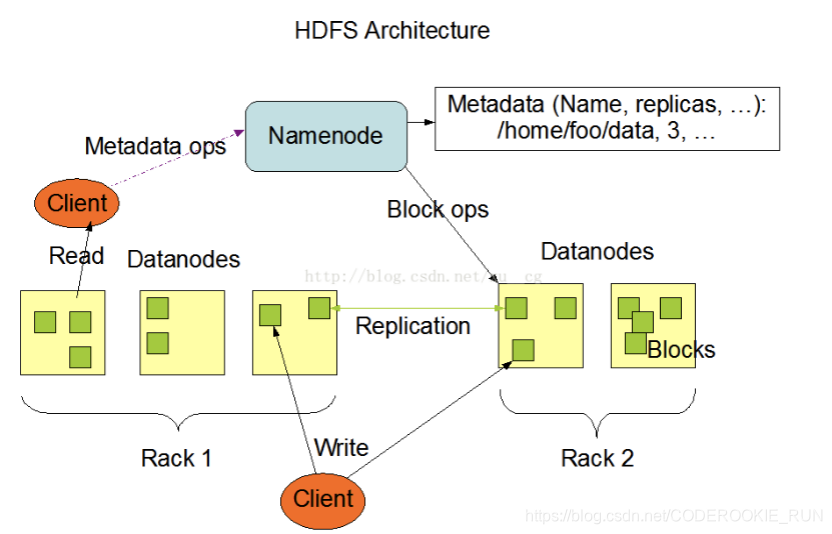
- NameNode和DataNode总结概述
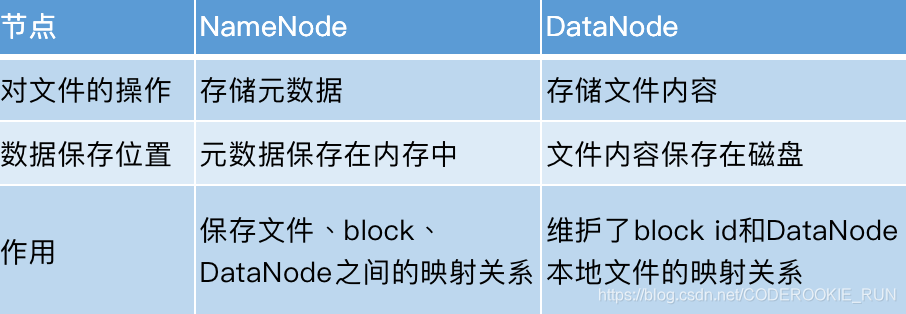
NameNode主要负责管理文件系统的名字空间(namespace)以及客户端对文件的访问,还有存储元数据。DataNode则主要负责处理用户的读写数据。NameNode的元数据保存在两个地方,一个是内存,一个是磁盘。(磁盘存的是元数据的快照,如果快照非常大,停机再启动代价会非常大)
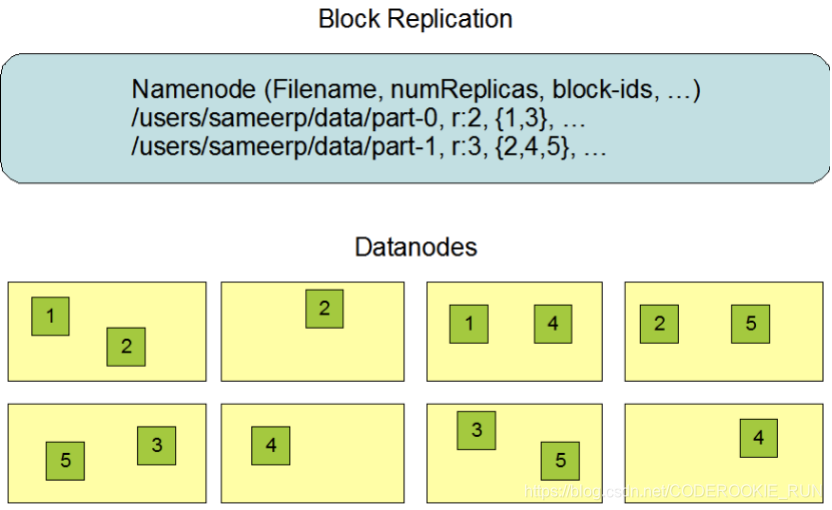
文件副本机制和block块存储
- 图解
- 概述
数据副本的存放机制:NameNode会首先找离客户端最近(跨交换机最少的)的一台机器上传block块,然后再去做备份。
NameNode负责数据block块的复制。(定期检测block的副本数,如果不够3个,就进行复制)
bolck块的大小,可以根据实际工作当中的文件特性来调整,如果都是一些大文件,可以微调block块的大小。这么做的原因可以举例来说明:
128M的bolck块:300M的文件会分成3个block块,要占用3个元数据
256M的block块,300M的文件只会分成2个block块,只需要占用2个元数据
这样可以有效节省NameNode的内存空间,这也是HDFS更擅长处理大文件的原因之一。
块缓存:distributedCache 可以用来实现我们的文件的缓存。
hdfs的权限验证:采用了与linux类似的权限验证机制,权限验证比较弱(防止好人做错事,不能阻止坏人做坏事)(HDFS相信你告诉我你是谁,你就是谁)
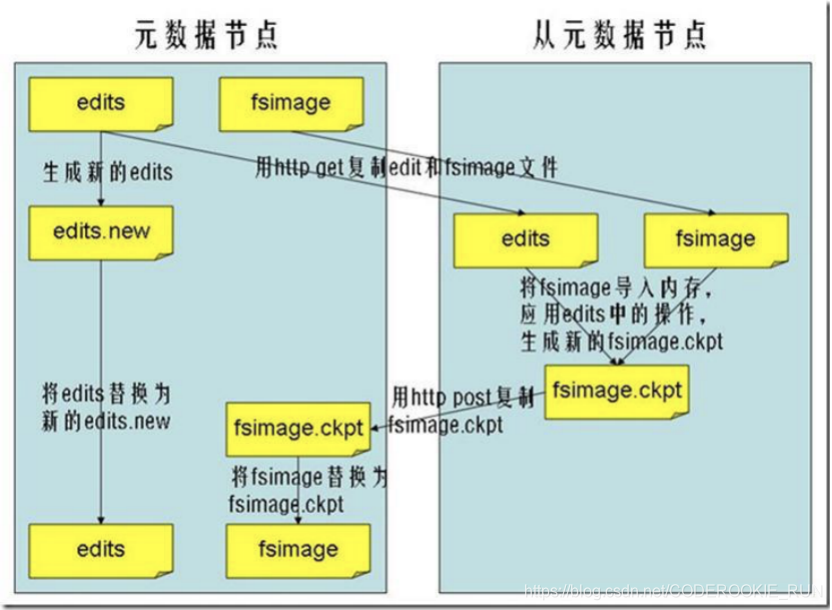
FSImage与edits
- 概述
FSImage保存的是一份最完整的元数据信息(一份比较完整的元数据信息,存放在两个地方,一个是磁盘,一个是内存)。HDFS文件可以保存多少数据,取决于NameNode的内存大小,所以HDFS推荐存储大量的大文件,不擅长存储小文件。
edits保存的是最近一段时间操作的元数据信息。
如何确定edits和fsimage合并了?
如果efits文件达到1G大小,合并一下
如果一直没有达到1G大小,达到一个小时就合并一下。
而完成合并操作的是SecondaryNameNode
- FSimage文件当中的文件信息查看
官方文档地址:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.14.0/hadoop-project-dist/hadoop-hdfs/HdfsImageViewer.html


- edits当中的文件信息查看
官方文档地址:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.14.0/hadoop-project-dist/hadoop-hdfs/HdfsEditsViewer.html


HDFS文件的写入过程和读取过程
- 写入过程
-
block块复制机制
第一个block块保存在本机
第二个block块保存在同一个交换机下的另一台机器
第三个block块保存在不同的交换机下的机器
block块存满之后,反向的校验机制会给客户端一个相应,告诉客户端第一个block已经保存,可以上传第二个block块……「block块ack机制」 -
读取过程
- 寻找block策略
第一个找离客户端最近的block块找最近一次“心跳”的DataNode进行读取 - 如果block块读取到一半的时候抛错了怎么办?
客户端会重新请求NameNode找出出错block的副本,找副本重新读,没有断点续传的功能