目录
流量日志分析网站整体架构模块的整体步骤为下图

关于数据采集模块和数据预处理的开发在【Hadoop离线基础总结】网站流量日志数据分析系统末尾已经写了,想了解可以点击查看。
数据仓库设计
-
维度建模概述
维度建模 (dimensional modeling) 是专门用于分析型数据库、数据仓库、数据集市建模(数据集市可以理解为是一种"小型数据仓库")的方法。
维度表 (dimension) 就是对数据按类别、区域等各个角度进行分析,比如有一个实例:今天下午白某在星巴克花40元喝了一杯星冰乐。以消费为主题对这段信息可以提取四个维度:时间维度 (今天下午)、地点维度 (星巴克)、价格维度 (40元)、商品维度 (星冰乐)。所以一般情况下维度表信息比较固定,且数据量小。
事实表 (fact table) 包含了与各维度表相关联的外键,并通过JOIN方式与维度表关联。事实表的度量通常是数值类型,且记录数会不断增加,表规模迅速增长。
数据仓库的主导功能是面向分析,以查询为主,不涉及数据更新操作,所以不需要严格遵守规范化设计原则。事实表的设计是以能够正确记录历史信息为准则,维度表的设计是以能够以合适的角度来聚合主题内容为准则。 -
维度建模的三种模式
1.星型模式
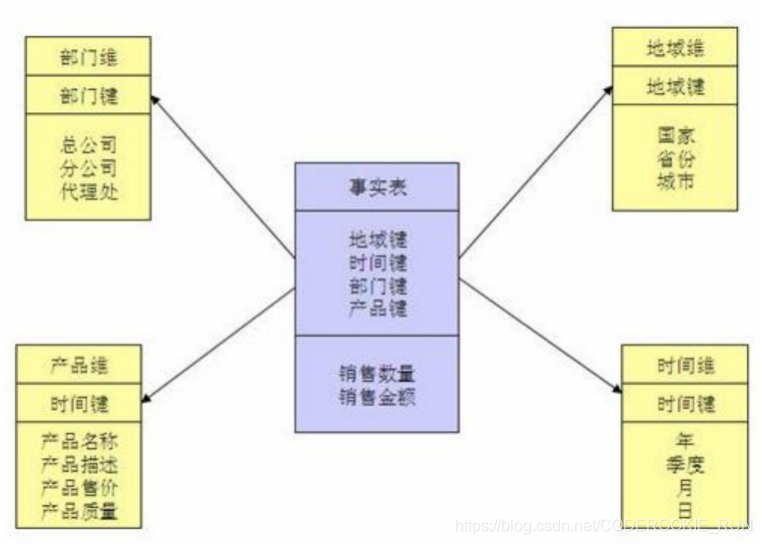
星型模式 (Star Schema) 是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样,是最常用的维度建模方式。
特点:
1.维度表只和事实表关联,维度表之间没有关联
2.每个维度表主键为单列,且该主键放置在事实表中,作为两边连接的外键
3.以事实表为核心,维表围绕核心呈星形分布
2.雪花模式
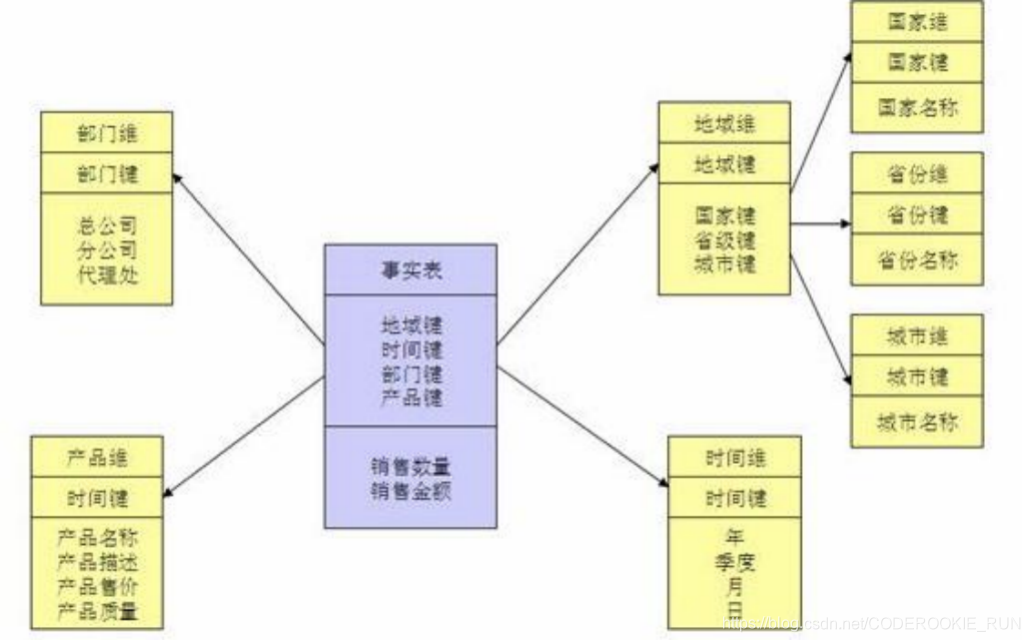
雪花模式 (Snowflake Schema) 是对星形模式的扩展。雪花模式的维度表可以拥有其他维度表的,虽然这种模型相比星型更规范一些,但是由于这种模型不太容易理解,维护成本比较高,而且性能方面需要关联多层维表,性能也比星型模型要低。所以一般不是很常用。
3.星座模式
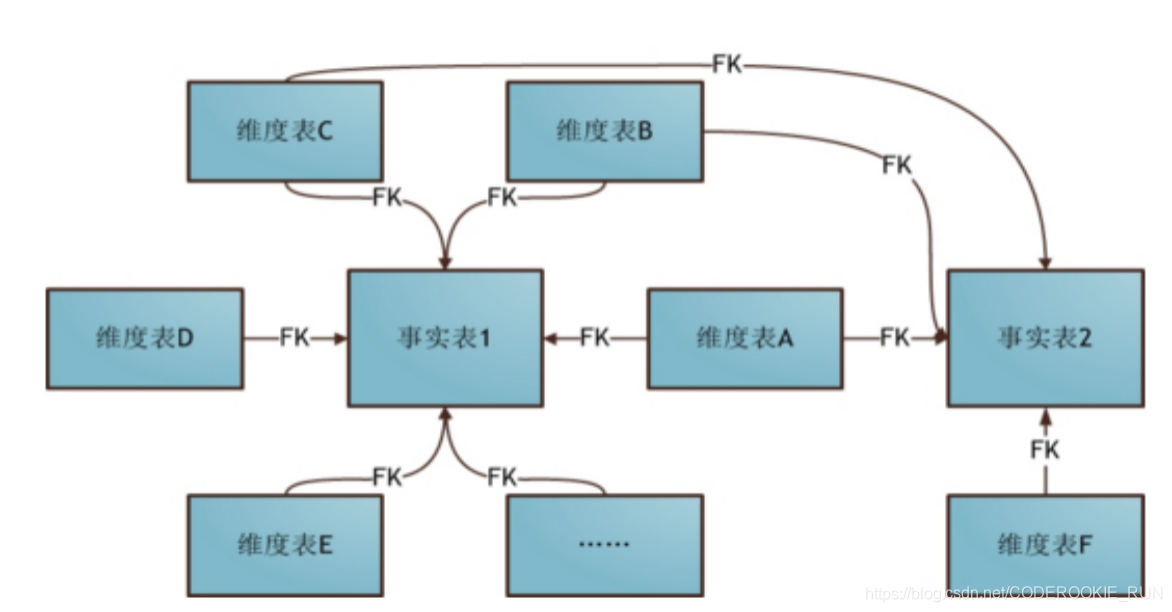
星座模式是星型模式延伸而来,星型模式是基于一张事实表的,而星座模式是基于多张事实表的,而且共享维度信息。在业务发展后期,绝大部分维度建模都采用的是星座模式。 -
本项目中数据仓库的设计

为了方便统计,将time_local拆分为daystr,timestr,month,day,hour五个字段,将http_referer拆分为ref_host,ref_path,ref_query,ref_query_id四个字段
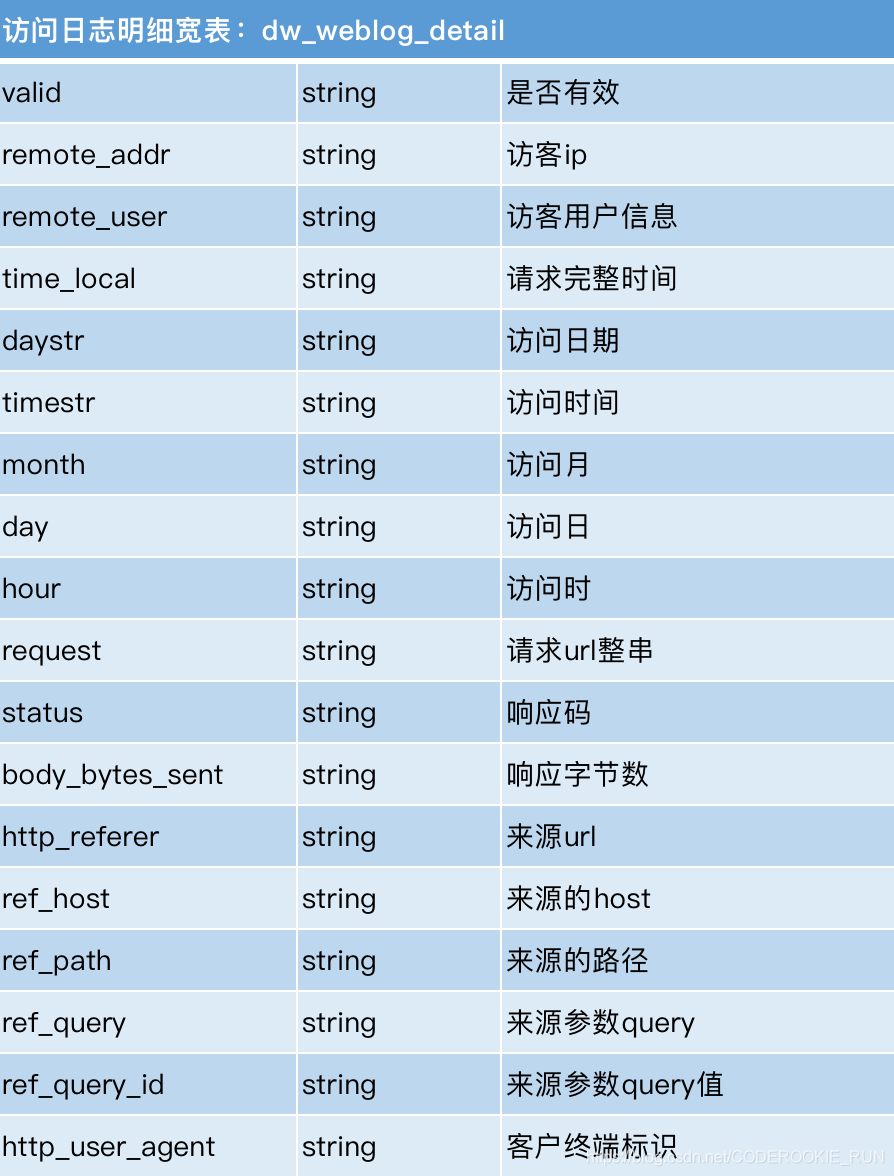
ETL开发
-
创建ODS层数据表
- 原始日志数据表
create database weblog;create table ods_weblog_origin( valid string, remote_addr string, remote_user string, time_local string, request string, status string, body_bytes_sent string, http_referer string, http_user_agent string) partitioned by (datestr string) row format delimited fields terminated by '�01'; - 点击流模型pageviews表
create table ods_click_pageviews( session string, remote_addr string, remote_user string, time_local string, request string, visit_step string, page_staylong string, http_referer string, http_user_agent string, body_bytes_sent string, status string) partitioned by (datestr string) row format delimited fields terminated by '�01'; - 点击流模型visit表
create table ods_click_stream_visit( session string, remote_addr string, inTime string, outTime string, inPage string, outPage string, referal string, pageVisits int) partitioned by (datestr string) row format delimited fields terminated by '�01';
- 原始日志数据表
-
导入ODS层数据
- 导入清洗结果数据到贴源数据表ods_weblog_origin
LOAD DATA LOCAL inpath '/export/servers/weblog/weblogout' overwrite INTO TABLE ods_weblog_origin PARTITION ( datestr = '20130918' ); - 导入点击流模型pageviews数据到ods_click_pageviews表
LOAD DATA LOCAL inpath '/export/servers/weblog/pageView' overwrite INTO TABLE ods_click_pageviews PARTITION ( datestr = '20130918' ); - 导入点击流模型visit数据到ods_click_stream_visit表
生产环境中应该将数据load命令写在脚本中,然后配置在azkaban定时运行,注意运行的时间点,应该在预处理数据完成之后。LOAD DATA LOCAL inpath '/export/servers/weblog/visit' overwrite INTO TABLE ods_click_stream_visit PARTITION ( datestr = '20130918' );
- 导入清洗结果数据到贴源数据表ods_weblog_origin
-
生成ODS层明细宽表
- 建明细表ods_weblog_detail
CREATE TABLE ods_weblog_detail( valid string, --有效标识 remote_addr string, --来源IP remote_user string, --用户标识 time_local string, --访问完整时间 daystr string, --访问日期 timestr string, --访问时间 month string, --访问月 day string, --访问日 hour string, --访问时 request string, --请求的url status string, --响应码 body_bytes_sent string, --传输字节数 http_referer string, --来源url ref_host string, --来源的host ref_path string, --来源的路径 ref_query string, --来源参数query ref_query_id string, --来源参数query的值 http_user_agent string --客户终端标识 ) partitioned BY ( datestr string ); - 通过查询插入数据到明细宽表 ods_weblog_detail中
- 抽取refer_url到中间表 t_ods_tmp_referurl
lateral view要和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据。CREATE TABLE t_ods_tmp_referurl AS SELECT a.*,b.* FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple ( regexp_replace ( http_referer, """, "" ), 'HOST','PATH','QUERY','QUERY:id' ) b AS host,path,query,query_id; - 抽取转换time_local字段到中间表明细表 t_ods_tmp_detail
CREATE TABLE t_ods_tmp_detail AS SELECT b.*, substring( time_local, 0, 10 ) AS daystr, substring( time_local, 12 ) AS timestr, substring( time_local, 6, 2 ) AS month, substring( time_local, 9, 2 ) AS day, substring( time_local, 11, 3 ) AS hour FROM t_ods_tmp_referurl b; - 可以将上面两个合成一个sql语句
INSERT INTO TABLE ods_weblog_detail PARTITION ( datestr = '20130918' ) SELECT c.valid,c.remote_addr,c.remote_user,c.time_local, substring( c.time_local, 0, 10 ) AS daystr, substring( c.time_local, 12 ) AS timestr, substring( c.time_local, 6, 2 ) AS month, substring( c.time_local, 9, 2 ) AS day, substring( c.time_local, 11, 3 ) AS hour, c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent FROM ( SELECT a.valid,a.remote_addr,a.remote_user,a.time_local,a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent, b.ref_host,b.ref_path,b.ref_query,b.ref_query_id FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple ( regexp_replace ( http_referer, """, "" ), 'HOST','PATH','QUERY','QUERY:id' ) b AS ref_host,ref_path,ref_query,ref_query_id ) c; - 不能这么写,会报错
报错信息:Line 1:18 Cannot insert into target table because column number/types are different ‘‘20130918’’: Table insclause-0 has 18 columns, but query has 19 columns.INSERT INTO TABLE ods_weblog_detail PARTITION (datestr='20130918') SELECT c.*, substring( c.time_local, 0, 10 ) AS daystr, substring( c.time_local, 12 ) AS timestr, substring( c.time_local, 6, 2 ) AS month, substring( c.time_local, 9, 2 ) AS day, substring( c.time_local, 11, 3 ) AS hour FROM ( SELECT a.*,b.* FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple ( regexp_replace ( http_referer, """, "" ),'HOST','PATH','QUERY','QUERY:id' ) b AS ref_host,ref_path,ref_query,ref_query_id ) c;
- 抽取refer_url到中间表 t_ods_tmp_referurl
- 建明细表ods_weblog_detail
统计分析开发
-
流量分析
-
统计每小时的PVS(pageView访问量)
- 创建统计每小时PVS表
CREATE TABLE dw_pvs_everyhour_oneday ( month string, day string, hour string, pvs BIGINT ) partitioned BY ( datestr string ); - 统计每小时的PVS
INSERT INTO TABLE dw_pvs_everyhour_oneday PARTITION (datestr = '20130918') SELECT a.month AS month, a.day AS day, a.hour AS hour,count(*) AS pvs FROM ods_weblog_detail a WHERE a.datestr = '20130918' GROUP BY a.month,a.day,a.hour; - 查询结果
+--------------------------------+------------------------------+-------------------------------+------------------------------+----------------------------------+--+ | dw_pvs_everyhour_oneday.month | dw_pvs_everyhour_oneday.day | dw_pvs_everyhour_oneday.hour | dw_pvs_everyhour_oneday.pvs | dw_pvs_everyhour_oneday.datestr | +--------------------------------+------------------------------+-------------------------------+------------------------------+----------------------------------+--+ | 09 | 18 | 06 | 111 | 20130918 | | 09 | 18 | 07 | 1010 | 20130918 | | 09 | 18 | 08 | 2052 | 20130918 | | 09 | 18 | 09 | 1374 | 20130918 | | 09 | 18 | 10 | 568 | 20130918 | | 09 | 18 | 11 | 571 | 20130918 | | 09 | 18 | 12 | 621 | 20130918 | | 09 | 18 | 13 | 531 | 20130918 | | 09 | 18 | 14 | 514 | 20130918 | | 09 | 18 | 15 | 759 | 20130918 | | 09 | 18 | 16 | 475 | 20130918 | | 09 | 18 | 17 | 382 | 20130918 | | 09 | 18 | 18 | 262 | 20130918 | | 09 | 18 | 19 | 390 | 20130918 | | 09 | 18 | 20 | 211 | 20130918 | | 09 | 18 | 21 | 213 | 20130918 | | 09 | 18 | 22 | 351 | 20130918 | | 09 | 18 | 23 | 382 | 20130918 | | 09 | 19 | 00 | 312 | 20130918 | | 09 | 19 | 01 | 324 | 20130918 | | 09 | 19 | 02 | 546 | 20130918 | | 09 | 19 | 03 | 552 | 20130918 | | 09 | 19 | 04 | 569 | 20130918 | | 09 | 19 | 05 | 540 | 20130918 | | 09 | 19 | 06 | 150 | 20130918 | +--------------------------------+------------------------------+-------------------------------+------------------------------+----------------------------------+--+
- 创建统计每小时PVS表
-
统计每天的PVS
- 创建统计每天PVS的表
CREATE TABLE dw_pvs_everyday ( month string, day string, pvs BIGINT ) partitioned BY ( datestr string ); - 统计每天的PVS
INSERT INTO TABLE dw_pvs_everyday PARTITION (datestr = '20130918') SELECT a.month AS month, a.day AS day,COUNT(*) AS pvs FROM ods_weblog_detail a WHERE a.datestr = '20130918' GROUP BY a.month,a.day; - 查询结果
+--------+------+--------+--+ | month | day | pvs | +--------+------+--------+--+ | 09 | 18 | 10777 | | 09 | 19 | 2993 | +--------+------+--------+--+
- 创建统计每天PVS的表
-
统计每小时各来访url产生的pv量
- 创建表
CREATE TABLE dw_pvs_referer_everyhour ( referer_url string, referer_host string, month string, day string, hour string, pv_referer_cnt BIGINT ) partitioned BY ( datestr string ); - 统计每小时各来访url产生的pv量
INSERT INTO TABLE dw_pvs_referer_everyhour PARTITION (datestr='20130918') SELECT http_referer,ref_host,month,day,hour,count(1) AS pv_referer_cnt FROM ods_weblog_detail GROUP BY http_referer,ref_host,month,day,hour HAVING ref_host IS NOT NULL ORDER BY hour asc,day asc,month asc,pv_referer_cnt desc; - 查询结果(limit 10)
+--------+------+-------+-------------------+----------------------------------------------------+-----------------+--+ | month | day | hour | referer_host | referer_url | pv_referer_cnt | +--------+------+-------+-------------------+----------------------------------------------------+-----------------+--+ | 09 | 18 | 06 | blog.fens.me | "http://blog.fens.me/mongodb-replica-set/" | 20 | | 09 | 18 | 06 | blog.fens.me | "http://blog.fens.me/vps-ip-dns/" | 19 | | 09 | 18 | 06 | blog.fens.me | "http://blog.fens.me/nodejs-grunt-intro/" | 7 | | 09 | 18 | 06 | blog.fens.me | "http://blog.fens.me/nodejs-socketio-chat/" | 7 | | 09 | 18 | 06 | blog.fens.me | "http://blog.fens.me/wp-content/themes/silesia/style.css" | 7 | | 09 | 18 | 06 | blog.fens.me | "http://blog.fens.me/nodejs-async/" | 5 | | 09 | 18 | 06 | www.angularjs.cn | "http://www.angularjs.cn/A00n" | 2 | | 09 | 18 | 06 | blog.fens.me | "http://blog.fens.me/nodejs-express3/" | 2 | | 09 | 18 | 06 | www.angularjs.cn | "http://www.angularjs.cn/" | 1 | | 09 | 18 | 06 | www.google.com | "http://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=6&cad=rja&ved=0CHIQFjAF&url=http%3A%2F%2Fblog.fens.me%2Fvps-ip-dns%2F&ei=j045UrP5AYX22AXsg4G4DQ&usg=AFQjCNGsJfLMNZnwWXNpTSUl6SOEzfF6tg&sig2=YY1oxEybUL7wx3IrVIMfHA&bvm=bv.52288139,d.b2I" | 1 | +--------+------+-------+-------------------+----------------------------------------------------+-----------------+--+
- 创建表
-
统计每小时各来访host的产生的pv数并排序
- 建表
CREATE TABLE dw_pvs_refererhost_everyhour ( ref_host string, month string, day string, hour string, ref_host_cnts BIGINT ) partitioned BY ( datestr string ); - 统计每小时各来访host的产生的pv数并排序
INSERT INTO TABLE dw_pvs_refererhost_everyhour PARTITION ( datestr = '20130918' ) SELECT ref_host,month,day,hour,count(1) AS ref_host_cnts FROM ods_weblog_detail GROUP BY ref_host,month,day,hour HAVING ref_host IS NOT NULL ORDER BY hour ASC,day ASC,month ASC,ref_host_cnts DESC; - 查询结果
+--------+------+-------+--------------------+----------------+--+ | month | day | hour | ref_host | ref_host_cnts | +--------+------+-------+--------------------+----------------+--+ | 09 | 18 | 06 | blog.fens.me | 68 | | 09 | 18 | 06 | www.angularjs.cn | 3 | | 09 | 18 | 06 | www.google.com | 2 | | 09 | 18 | 06 | www.baidu.com | 1 | | 09 | 18 | 06 | cos.name | 1 | | 09 | 18 | 07 | blog.fens.me | 711 | | 09 | 18 | 07 | www.google.com.hk | 20 | | 09 | 18 | 07 | www.angularjs.cn | 20 | | 09 | 18 | 07 | www.dataguru.cn | 10 | | 09 | 18 | 07 | www.fens.me | 6 | +--------+------+-------+--------------------+----------------+--+
- 建表
-
统计pv总量最大的来源TOPN
- 首先需要了解一下hive 中窗口函数的用法
在hive的窗口函数中可以简单了解 - 统计一天内每小时各来访的host的url的topN
CREATE TABLE dw_pvs_refhost_topn_everyhour( hour string, toporder string, ref_host string, ref_host_cnts string) partitioned by (datestr string);INSERT INTO TABLE dw_pvs_refhost_topn_everyhour PARTITION (datestr = '20130918') SELECT t.hour,t.od,t.ref_host,t.ref_host_cnts FROM ( SELECT ref_host,ref_host_cnts,CONCAT(month,day,hour) AS hour, ROW_NUMBER() over ( PARTITION by CONCAT(month,day,hour) ORDER BY ref_host_cnts DESC) od FROM dw_pvs_refererhost_everyhour ) t WHERE od<=3;
- 首先需要了解一下hive 中窗口函数的用法
-
人均浏览页数
- 第一步:先求有多少人,用一个ip地址来代表一个人,那么就是对ip地址去重
SELECT count(DISTINCT(remote_addr)) FROM ods_weblog_detail;+-------+--+ | _c0 | +-------+--+ | 1027 | +-------+--+ - 第二步:求浏览页数总数,再用页数总数除以ip去重数
SELECT '20130918',SUM(b.pvs)/COUNT(b.remote_addr) FROM ( SELECT remote_addr,count(1) AS pvs FROM ods_weblog_detail WHERE datestr = '20130918' GROUP BY remote_addr ) b;
- 第一步:先求有多少人,用一个ip地址来代表一个人,那么就是对ip地址去重
-
-
受访分析
- 各页面PV(每个页面受到多少次访问)——使用request字段来代表我们访问的页面
SELECT request AS request,COUNT(request) AS request_counts FROM ods_weblog_detail GROUP BY request HAVING request IS NOT NULL ORDER BY request_counts DESC LIMIT 20;+----------------------------------------------------+-----------------+--+ | request | request_counts | +----------------------------------------------------+-----------------+--+ | / | 3139 | | /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 | 361 | | /wp-includes/js/jquery/jquery.js?ver=1.10.2 | 358 | | /js/baidu.js | 318 | | /wp-admin/admin-ajax.php | 308 | | /js/google.js | 308 | | /wp-content/themes/silesia/js/jquery.cycle.all.min.js | 293 | | /wp-content/themes/silesia/functions/js/shortcode.js | 290 | | /wp-content/themes/silesia/js/load.js | 290 | | /wp-includes/js/comment-reply.min.js?ver=3.6 | 285 | | /feed/ | 263 | | /wp-content/themes/silesia/style.css | 255 | | /wp-content/themes/silesia/functions/css/shortcodes.css | 254 | | /wp-content/themes/silesia/images/slide-bg.png | 238 | | /wp-content/themes/silesia/images/natty-logo.png | 238 | | /wp-content/themes/silesia/images/crubms-div.png | 238 | | /wp-content/themes/silesia/images/ico-twitter.png | 236 | | /wp-content/themes/silesia/images/home-ico.png | 236 | | /wp-content/themes/silesia/images/ico-meta.gif | 235 | | /wp-content/themes/silesia/images/sprites/post-type.png | 233 | +----------------------------------------------------+-----------------+--+ - 热门页面统计——统计20130918分区里面受访页面的top10
- 创建热门表
CREATE TABLE dw_hotpages_everyday( day stirng, url string, pvs string); - 热门页面统计
INSERT INTO TABLE dw_hotpages_everyday SELECT '20130918',a.request,a.request_counts FROM( SELECT request AS request,COUNT(request) AS request_counts FROM ods_weblog_detail WHERE datestr='20130918' GROUP BY request HAVING request IS NOT NULL ) a ORDER BY a.request_counts DESC LIMIT 10;+-----------+----------------------------------------------------+-------+--+ | day | url | pvs | +-----------+----------------------------------------------------+-------+--+ | 20130918 | / | 3139 | | 20130918 | /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 | 361 | | 20130918 | /wp-includes/js/jquery/jquery.js?ver=1.10.2 | 358 | | 20130918 | /js/baidu.js | 318 | | 20130918 | /wp-admin/admin-ajax.php | 308 | | 20130918 | /js/google.js | 308 | | 20130918 | /wp-content/themes/silesia/js/jquery.cycle.all.min.js | 293 | | 20130918 | /wp-content/themes/silesia/functions/js/shortcode.js | 290 | | 20130918 | /wp-content/themes/silesia/js/load.js | 290 | | 20130918 | /wp-includes/js/comment-reply.min.js?ver=3.6 | 285 | +-----------+----------------------------------------------------+-------+--+
- 创建热门表
- 统计每天最热门页面的Top10
SELECT CONCAT(a.month,a.day),a.month,a.day,a.request,a.request_counts FROM ( SELECT month,day,request,COUNT(1) AS request_counts FROM ods_weblog_detail WHERE datestr = '20130918' GROUP BY request,month,day HAVING request IS NOT NULL ORDER BY request_counts DESC LIMIT 10 ) a;
- 各页面PV(每个页面受到多少次访问)——使用request字段来代表我们访问的页面
+-------+----------+--------+----------------------------------------------------+-------------------+--+
| _c0 | a.month | a.day | a.request | a.request_counts |
+-------+----------+--------+----------------------------------------------------+-------------------+--+
| 0918 | 09 | 18 | / | 2268 |
| 0919 | 09 | 19 | / | 871 |
| 0918 | 09 | 18 | /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 | 293 |
| 0918 | 09 | 18 | /wp-includes/js/jquery/jquery.js?ver=1.10.2 | 290 |
| 0918 | 09 | 18 | /js/baidu.js | 269 |
| 0918 | 09 | 18 | /js/google.js | 259 |
| 0918 | 09 | 18 | /wp-content/themes/silesia/js/jquery.cycle.all.min.js | 244 |
| 0918 | 09 | 18 | /wp-content/themes/silesia/js/load.js | 243 |
| 0918 | 09 | 18 | /wp-content/themes/silesia/functions/js/shortcode.js | 242 |
| 0918 | 09 | 18 | /wp-includes/js/comment-reply.min.js?ver=3.6 | 223 |
+-------+----------+--------+----------------------------------------------------+-------------------+--+
-
访客分析
- 独立访客
按照时间维度比如小时来统计独立访客及其产生的pv
对于独立访客的识别,如果在原始日志中有用户标识,则根据用户标识即很好实现;此处,由于原始日志中并没有用户标识,以访客IP来模拟,技术上是一样的,只是精确度相对较低。 - 统计每小时的独立访客和产生的pv量
- 建表
CREATE TABLE dw_user_dstc_ip_h( remote_addr string, pvs bigint, hour string); - 统计数据
INSERT INTO dw_user_dstc_ip_h SELECT remote_addr,count(1) AS pvs,concat(month,day,hour) AS hour FROM ods_weblog_detail WHERE datestr = '20130918' GROUP BY remote_addr,concat(month,day,hour);
- 建表
- 每日新访客
- 创建历日去重访客累积表
CREATE TABLE dw_user_dsct_history( day string, ip string) partitioned by (datestr string); - 创建每日新访客表
CREATE TABLE dw_user_new_d( day string, ip string) partitioned by (datestr string); - 每日新访客插入到新访客表
INSERT INTO TABLE dw_user_new_d PARTITION (datestr = '20130918') SELECT tmp.day AS day,tmp.today_addr AS new_ip FROM ( SELECT today.day AS day,today.remote_addr AS today_addr,old.ip AS old_addr FROM ( SELECT DISTINCT remote_addr AS remote_addr,"20130918" AS day FROM ods_weblog_detail WHERE datestr = '20130918' ) today LEFT OUTER JOIN dw_user_dsct_history old ON today.remote_addr = old.ip ) tmp WHERE tmp.old_addr IS NULL; - 每日新访客追加到历日去重访客累积表
INSERT INTO TABLE dw_user_dsct_history PARTITION (datestr = '20130918') SELECT day,ip FROM dw_user_new_d WHERE datestr = '20130918';
- 创建历日去重访客累积表
- 独立访客
-
访客visit分析
- 回头/单次访客统计

- 创建回头访客表
CREATE TABLE dw_user_returning( day string, remote_addr string, acc_cnt string) partitioned by (datestr string); - 统计回头访客数据
INSERT overwrite TABLE dw_user_returning PARTITION (datestr = '20130918') SELECT tmp.day,tmp.remote_addr,tmp.acc_cnt FROM ( SELECT '20130918' AS day,remote_addr,count(session) AS acc_cnt FROM ods_click_stream_visit GROUP BY remote_addr ) tmp WHERE tmp.acc_cnt > 1;
- 创建回头访客表
- 人均访问频次
就是总visit数除以去重后的总用户数SELECT SUM(pagevisits)/COUNT(DISTINCT remote_addr) FROM ods_click_stream_visit WHERE datestr = '20130918';
- 回头/单次访客统计
-
关键路径转化率分析(漏斗模型)
-
级联求和