通过将CUDA相关计算操作放在库中,方便在项目中调用,省去了每次编译cu文件的麻烦,也便于集成到其他平台上。
本文配置:VS2015 CUDA8.0
一、封装CUDA动态库
主要步骤:修改自定义方式、设置cu文件项类型为CDUA CC++ ,添加依赖库cudart.lib.
1、创建一个动态库,这里建的库是x86的,也可以更改为x64.

2、添加cu文件

3、源程序内容
CudaDll32.h
// 下列 ifdef 块是创建使从 DLL 导出更简单的 // 宏的标准方法。此 DLL 中的所有文件都是用命令行上定义的 CUDADLL32_EXPORTS // 符号编译的。在使用此 DLL 的 // 任何其他项目上不应定义此符号。这样,源文件中包含此文件的任何其他项目都会将 // CUDADLL32_API 函数视为是从 DLL 导入的,而此 DLL 则将用此宏定义的 // 符号视为是被导出的。 #ifdef CUDADLL32_EXPORTS #define CUDADLL32_API __declspec(dllexport) #else #define CUDADLL32_API __declspec(dllimport) #endif extern "C" CUDADLL32_API int vectorAdd(int c[], int a[], int b[], int size);
kernel.cu
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include "CudaDll32.h" //CUDA核函数 __global__ void addKernel(int *c, const int *a, const int *b) { int i = threadIdx.x; c[i] = a[i] + b[i]; } //向量相加 CUDADLL32_API int vectorAdd(int c[], int a[], int b[], int size) { int result = -1; int *dev_a = 0; int *dev_b = 0; int *dev_c = 0; cudaError_t cudaStatus; // 选择用于运行的GPU cudaStatus = cudaSetDevice(0); if (cudaStatus != cudaSuccess) { result = 1; goto Error; } // 在GPU中为变量dev_a、dev_b、dev_c分配内存空间. cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int)); if (cudaStatus != cudaSuccess) { result = 2; goto Error; } cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int)); if (cudaStatus != cudaSuccess) { result = 3; goto Error; } cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int)); if (cudaStatus != cudaSuccess) { result = 4; goto Error; } // 从主机内存复制数据到GPU内存中. cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { result = 5; goto Error; } cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { result = 6; goto Error; } // 启动GPU内核函数 addKernel << <1, size >> >(dev_c, dev_a, dev_b); // 采用cudaDeviceSynchronize等待GPU内核函数执行完成并且返回遇到的任何错误信息 cudaStatus = cudaDeviceSynchronize(); if (cudaStatus != cudaSuccess) { result = 7 goto Error } // 从GPU内存中复制数据到主机内存中 cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); if (cudaStatus != cudaSuccess) { result = 8; goto Error; } result = 0; // 重置CUDA设备,在退出之前必须调用cudaDeviceReset cudaStatus = cudaDeviceReset(); if (cudaStatus != cudaSuccess) { return 9; } Error: //释放设备中变量所占内存 cudaFree(dev_c); cudaFree(dev_a); cudaFree(dev_b); return result; }
4、修改项目的自定义方式为:CUDA8.0

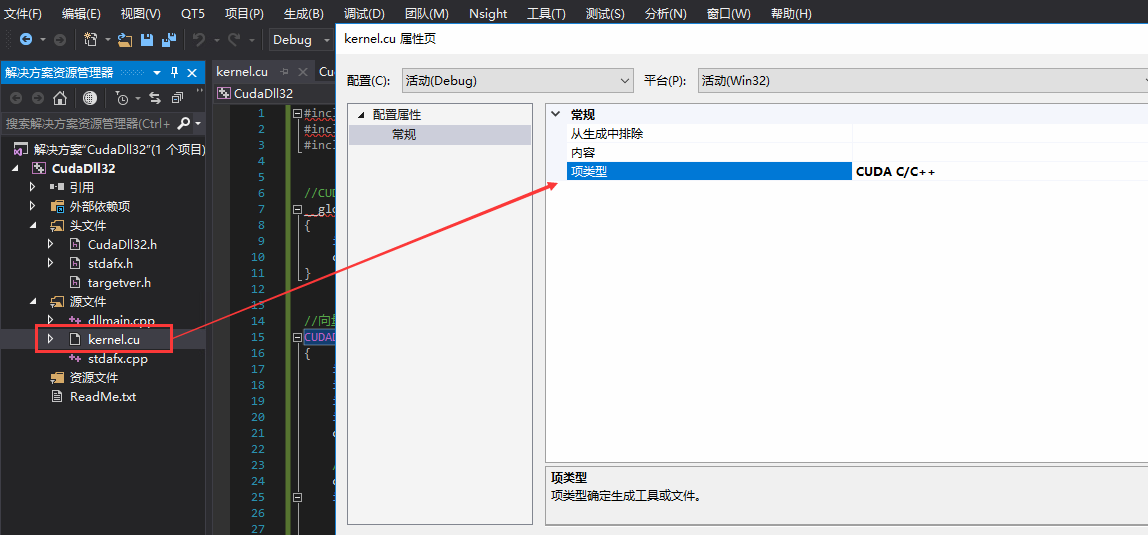
5、修改cu文件的项类型
6、添加链接器的附加依赖项 cudart.lib

7、生成DLL文件

二、调用动态库
创建一个控制台工程,调用库三步骤:
调用源代码:包含头文件、并把dll文件拷贝到可行性目录下
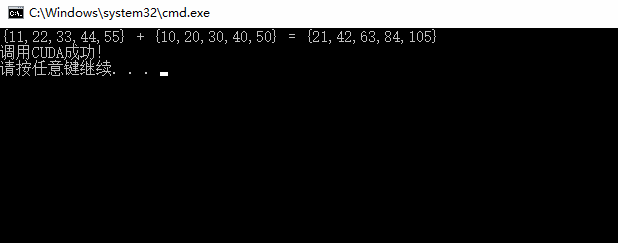
// CallCudaDll32.cpp : 定义控制台应用程序的入口点。 // #include "stdafx.h" #include "CudaDll32.h" int main() { const int arraySize = 5; int a[arraySize] = { 11, 22, 33, 44, 55 }; int b[arraySize] = { 10, 20, 30, 40, 50 }; int c[arraySize] = { 0 }; // Add vectors in parallel. int number = vectorAdd(c, a, b, arraySize); printf("{11,22,33,44,55} + {10,20,30,40,50} = {%d,%d,%d,%d,%d} ", c[0], c[1], c[2], c[3], c[4]); printf("调用CUDA成功! "); return 0; }
结果显示: