概念解析
首先,我们先整理一下:平时在使用一些GPU加速算法是都是在Python环境下执行,但是一般的Python代码是没办法使用GPU加速的,因为GPU是更接近计算机底层的硬件,Python一类的高级语言是没办法直接和GPU沟通的。
然后就引出话题的重点:硬件的加速必须使用硬件语言。
查询Python+GPU关键字,除了TensorFlow,另外出镜率比较高的几个概念是:Numba、CUDA、PyCUDA、minpy。
所以如果要想使对Python和GPU加速相关知识了解更深入,必须了解一些计算机的底层知识。
GPU概念相关
GPU(Graphics Processing Unit),视觉处理器、图形显示卡。
GPU负责渲染出2D、3D、VR效果,主要专注于计算机图形图像领域。后来人们发现,GPU非常适合并行计算,可以加速现代科学计算,GPU也因此不再局限于游戏和视频领域。
无论是CPU还是GPU,在进行计算时,都需要用核心(Core,也就是ALU+寄存器)来做算术逻辑运算。
一个核心只能顺序执行某项任务,为了同时并行处理更多任务,芯片公司开发出了多核架构,只要相互之间没有依赖,每个核心做自己的事情,多核之间互不干扰,就可以达到并行计算的效果。
CPU的局限
个人桌面电脑CPU只有2~8个核心Core,数据中信的服务器上也只有20到40个核心,GPU却有上千个核心。
然而,CPU和GPU的核心并不相同,GPU的核心只能专注于某些特性的任务,而CPU核心具有更广泛的计算能力。
CPU更通用,起到协调管理的作用,GPU功能局限在计算特定任务。
CPU与GPU交互
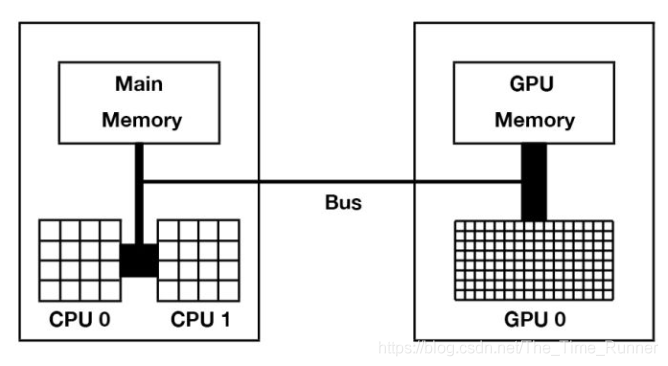
CPU从主存(Main Memory)中读写数据,并通过总线(Bus)与GPU交互。
GPU在许多计算核心之外,也有自己独立的存储,称为显存。
GPU核心在做计算时,只能直接从显存中读写数据,程序员需要在代码中指明哪些数据需要从内存和显存之间相互拷贝,这些数据传输都是在总线上,因此总线(NVLink技术、PCI-E技术…)的传输速度和带宽也会是部分计算任务的瓶颈。
因为CPU和GPU是分开的,在英伟达的设计理念中,CPU和主存被称为Host,GPU被称为Device。
Host和·概念会贯穿整个英伟达GPU编程。
使用CPU和GPU组合来加速计算,也被称为异构计算。
世界第一的超级计算机Summit使用了9216个IBM POWER9 CPU和27648个英伟达Tesla GPU。
GPU架构
Turing 图灵
2018年发布
消费显卡:GeForce 2080 Ti
Volta 伏特
2017年发布
专业显卡:Tesla V100(16或32GB显存,5120个核心)
Pascal 帕斯卡
2016年发布
专业显卡:Tesla P100(12或16GB显存,3584个核心)
英伟达设计理念中,多个小核心组成一个Streaming Multiprocessor(SM),一张GPU卡又多个SM。
英伟达主要以SM为运算和调度的基本单元。
单个SM的结构包括:
针对不同计算的小核心(绿色小格子),包括优化深度学习的TENSOR CORE,32个64位浮点核心(FP64),64个整型核心(INT),64个32位浮点核心(FP32);
计算核心直接从寄存器(Register)中读写数据;
调度和分发器(Scheduler和Dispatch Unit);
L0和L1级缓存;
前面以物理学家命名的架构区分主要针对设计,对消费者而言,英伟达主要又两条产品线:
消费级产品 GeForce系列:GeForce 2080 Ti…
高性能计算产品 Telsa系列:Telsa V100、Telsa P100、Telsa P40…
GPU的软件生态
前面描述的都是GPU的物理层面的结构,英伟达之所以能在人工智能时代成功,除了上述硬件卓越之外,更主要的是率先提供了可编程的软件架构。
早期GPU编程不友好,2007年英伟达发布CUDA编程模型之后改变了这一情形。
CUDA对于GPU就像个人电脑上的Windows、手机上的安卓系统。一旦建立好系统,吸引了开发者,用户非常依赖这套软件生态体系。
英伟达软件栈:
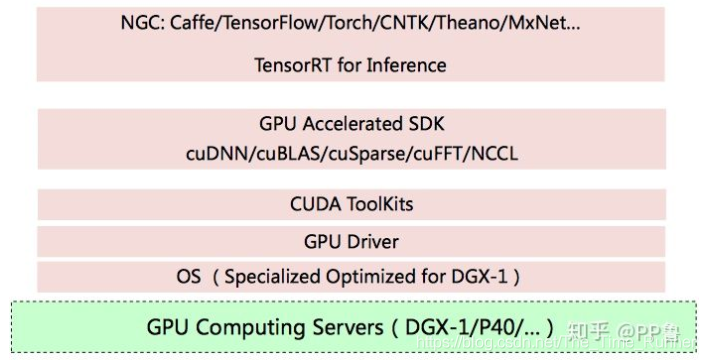
GPU编程方法:
直接使用CUDA的C/C++版本进行编程;
Python使用Numba库调用CUDA;
CUDA及其软件栈的缺点:
软件环境复杂,库及版本很多;
顶层应用严重依赖底层工具库,入门者很难快读配置好一整套环境;多环境配置困难;
用户只能使用英伟达的显卡,成本高;
入门可以考虑云厂商的Tesla P4虚拟机,大约十几元/小时。